 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GNNFlow: A Distributed Framework for Continuous Temporal GNN Learning on Dynamic Graphs
Nov 30, 2023
Graph Neural Networks (GNNs) play a crucial role in various fields. However, most existing deep graph learning frameworks assume pre-stored static graphs and do not support training on graph streams. In contrast, many real-world graphs are dynamic and contain time domain information. We introduce GNNFlow, a distributed framework that enables efficient continuous temporal graph representation learning on dynamic graphs on multi-GPU machines. GNNFlow introduces an adaptive time-indexed block-based data structure that effectively balances memory usage with graph update and sampling operation efficiency. It features a hybrid GPU-CPU graph data placement for rapid GPU-based temporal neighborhood sampling and kernel optimizations for enhanced sampling processes. A dynamic GPU cache for node and edge features is developed to maximize cache hit rates through reuse and restoration strategies. GNNFlow supports distributed training across multiple machines with static scheduling to ensure load balance. We implement GNNFlow based on DGL and PyTorch. Our experimental results show that GNNFlow provides up to 21.1x faster continuous learning than existing systems.
Dual-stream contrastive predictive network with joint handcrafted feature view for SAR ship classification
Nov 30, 2023Most existing synthetic aperture radar (SAR) ship classification technologies heavily rely on correctly labeled data, ignoring the discriminative features of unlabeled SAR ship images. Even though researchers try to enrich CNN-based features by introducing traditional handcrafted features, existing methods easily cause information redundancy and fail to capture the interaction between them. To address these issues, we propose a novel dual-stream contrastive predictive network (DCPNet), which consists of two asymmetric task designs and the false negative sample elimination module. The first task is to construct positive sample pairs, guiding the core encoder to learn more general representations. The second task is to encourage adaptive capture of the correspondence between deep features and handcrated features, achieving knowledge transfer within the model, and effectively improving the redundancy caused by the feature fusion. To increase the separability between clusters, we also design a cluster-level tasks. The experimental results on OpenSARShip and FUSAR-Ship datasets demonstrate the improvement in classification accuracy of supervised models and confirm the capability of learning effective representations of DCPNet.
Use of explicit replies as coordination mechanisms in online student debate
Nov 30, 2023People in conversation entrain their linguistic behaviours through spontaneous alignment mechanisms [7] - both in face-to-face and computer-mediated communication (CMC) [8]. In CMC, one of the mechanisms through which linguistic entrainment happens is through explicit replies. Indeed, the use of explicit replies influences the structure of conversations, favouring the formation of reply-trees typically delineated by topic shifts [5]. The interpersonal coordination mechanisms realized by how actors address each other have been studied using a probabilistic framework proposed by David Gibson [2,3]. Other recent approaches use computational methods and information theory to quantify changes in text. We explore coordination mechanisms concerned with some of the roles utterances play in dialogues - specifically in explicit replies. We identify these roles by finding community structure in the conversation's vocabulary using a non-parametric, hierarchical topic model. Some conversations may always stay on the ground, remaining at the level of general introductory chatter. Some others may develop a specific sub-topic in significant depth and detail. Even others may jump between general chatter, out-of-topic remarks and people agreeing or disagreeing without further elaboration.
Unsupervised high-throughput segmentation of cells and cell nuclei in quantitative phase images
Nov 24, 2023In the effort to aid cytologic diagnostics by establishing automatic single cell screening using high throughput digital holographic microscopy for clinical studies thousands of images and millions of cells are captured. The bottleneck lies in an automatic, fast, and unsupervised segmentation technique that does not limit the types of cells which might occur. We propose an unsupervised multistage method that segments correctly without confusing noise or reflections with cells and without missing cells that also includes the detection of relevant inner structures, especially the cell nucleus in the unstained cell. In an effort to make the information reasonable and interpretable for cytopathologists, we also introduce new cytoplasmic and nuclear features of potential help for cytologic diagnoses which exploit the quantitative phase information inherent to the measurement scheme. We show that the segmentation provides consistently good results over many experiments on patient samples in a reasonable per cell analysis time.
Insights into Age-Related Functional Brain Changes during Audiovisual Integration Tasks: A Comprehensive EEG Source-Based Analysis
Nov 27, 2023The seamless integration of visual and auditory information is a fundamental aspect of human cognition. Although age-related functional changes in Audio-Visual Integration (AVI) have been extensively explored in the past, thorough studies across various age groups remain insufficient. Previous studies have provided valuable insights into agerelated AVI using EEG-based sensor data. However, these studies have been limited in their ability to capture spatial information related to brain source activation and their connectivity. To address these gaps, our study conducted a comprehensive audiovisual integration task with a specific focus on assessing the aging effects in various age groups, particularly middle-aged individuals. We presented visual, auditory, and audio-visual stimuli and recorded EEG data from Young (18-25 years), Transition (26- 33 years), and Middle (34-42 years) age cohort healthy participants. We aimed to understand how aging affects brain activation and functional connectivity among hubs during audio-visual tasks. Our findings revealed delayed brain activation in middleaged individuals, especially for bimodal stimuli. The superior temporal cortex and superior frontal gyrus showed significant changes in neuronal activation with aging. Lower frequency bands (theta and alpha) showed substantial changes with increasing age during AVI. Our findings also revealed that the AVI-associated brain regions can be clustered into five different brain networks using the k-means algorithm. Additionally, we observed increased functional connectivity in middle age, particularly in the frontal, temporal, and occipital regions. These results highlight the compensatory neural mechanisms involved in aging during cognitive tasks.
Online Video Quality Enhancement with Spatial-Temporal Look-up Tables
Nov 22, 2023Low latency rates are crucial for online video-based applications, such as video conferencing and cloud gaming, which make improving video quality in online scenarios increasingly important. However, existing quality enhancement methods are limited by slow inference speed and the requirement for temporal information contained in future frames, making it challenging to deploy them directly in online tasks. In this paper, we propose a novel method, STLVQE, specifically designed to address the rarely studied online video quality enhancement (Online-VQE) problem. Our STLVQE designs a new VQE framework which contains a Module-Agnostic Feature Extractor that greatly reduces the redundant computations and redesign the propagation, alignment, and enhancement module of the network. A Spatial-Temporal Look-up Tables (STL) is proposed, which extracts spatial-temporal information in videos while saving substantial inference time. To the best of our knowledge, we are the first to exploit the LUT structure to extract temporal information in video tasks. Extensive experiments on the MFQE 2.0 dataset demonstrate that our STLVQE achieves a satisfactory performance-speed trade-off.
On RIS-Aided SIMO Gaussian Channels: Towards A Single-RF MIMO Transceiver Architecture
Nov 24, 2023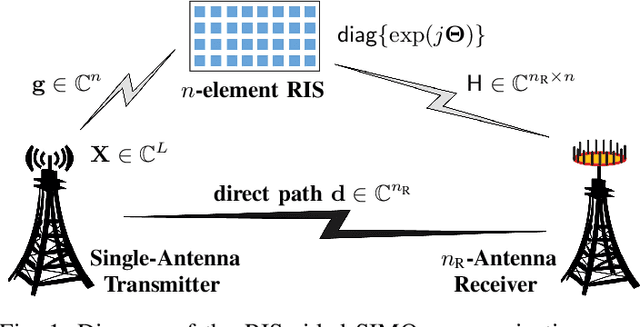
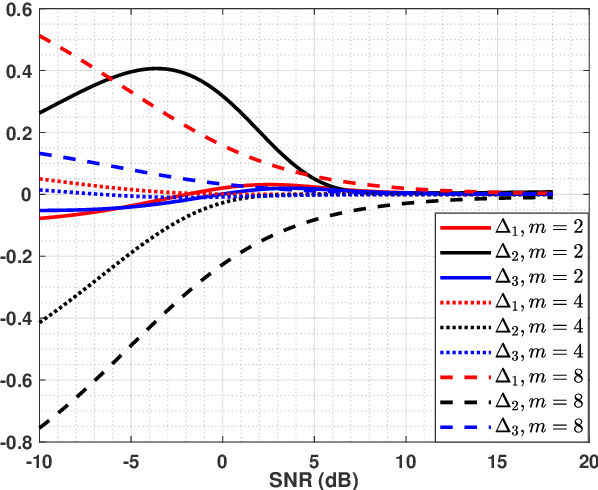
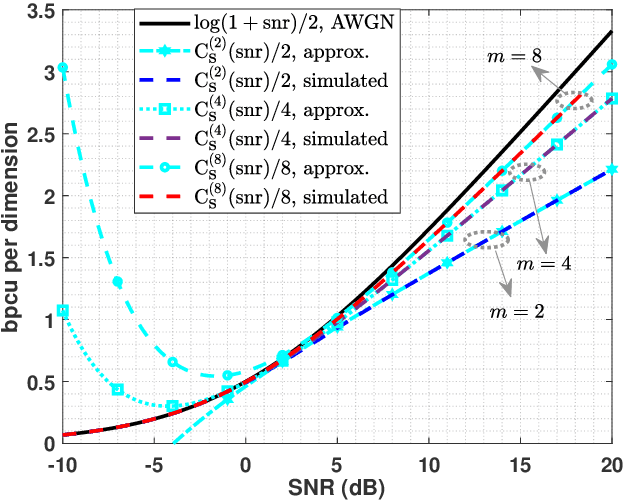
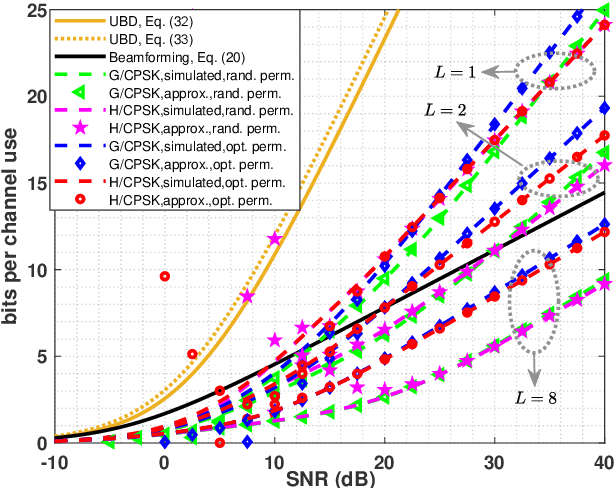
In this paper, for a single-input multiple-output (SIMO) system aided by a passive reconfigurable intelligent surface (RIS), the joint transmission accomplished by the single transmit antenna and the RIS with multiple controllable reflective elements is considered. Relying on a general capacity upper bound derived by a maximum-trace argument, we respectively characterize the capacity of such \rev{a} channel in the low-SNR or the rank-one regimes, in which the optimal configuration of the RIS is proved to be beamforming with carefully-chosen phase shifts. To exploit the potential of modulating extra information on the RIS, based on the QR decomposition, successive interference cancellation, and a strategy named \textit{partially beamforming and partially information-carrying}, we propose a novel transceiver architecture with only a single RF front end at the transmitter, by which the considered channel can be regarded as a concatenation of a vector Gaussian channel and several phase-modulated channels. Especially, we investigate a class of vector Gaussian channels with a hypersphere input support constraint, and not only generalize the existing result to arbitrary-dimensional real spaces but also present its high-order capacity asymptotics, by which both capacities of hypersphere-constrained channels and achievable rates of the proposed transceiver with two different signaling schemes can be well-approximated. Information-theoretic analyses show that the transceiver architecture designed for the SIMO channel has a boosted multiplexing gain, rather than one for the conventionally-used optimized beamforming scheme.Numerical results verify our derived asymptotics and show notable superiority of the proposed transceiver.
InstructMol: Multi-Modal Integration for Building a Versatile and Reliable Molecular Assistant in Drug Discovery
Nov 27, 2023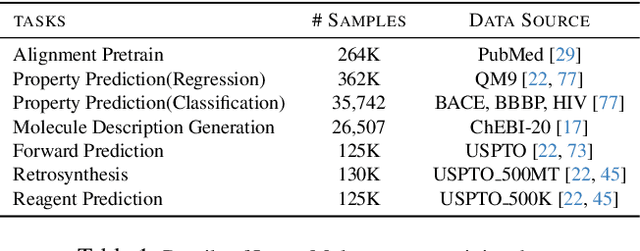
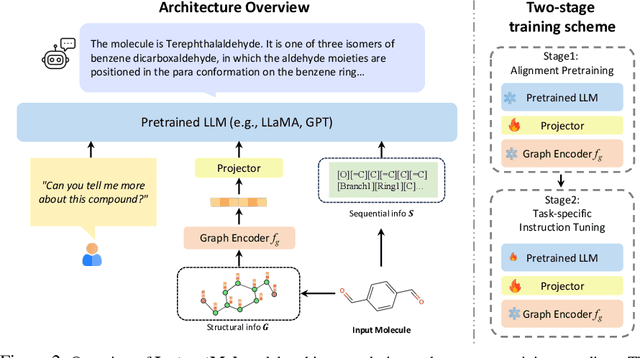
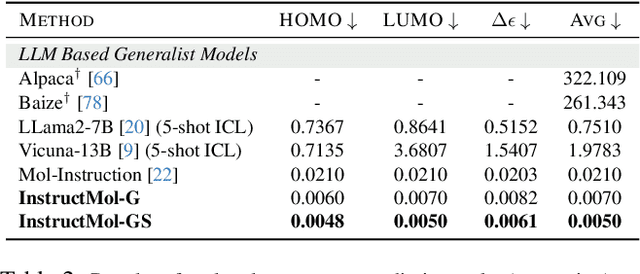
The rapid evolution of artificial intelligence in drug discovery encounters challenges with generalization and extensive training, yet Large Language Models (LLMs) offer promise in reshaping interactions with complex molecular data. Our novel contribution, InstructMol, a multi-modal LLM, effectively aligns molecular structures with natural language via an instruction-tuning approach, utilizing a two-stage training strategy that adeptly combines limited domain-specific data with molecular and textual information. InstructMol showcases substantial performance improvements in drug discovery-related molecular tasks, surpassing leading LLMs and significantly reducing the gap with specialized models, thereby establishing a robust foundation for a versatile and dependable drug discovery assistant.
Semi-supervised Medical Image Segmentation via Query Distribution Consistency
Nov 21, 2023Semi-supervised learning is increasingly popular in medical image segmentation due to its ability to leverage large amounts of unlabeled data to extract additional information. However, most existing semi-supervised segmentation methods focus only on extracting information from unlabeled data. In this paper, we propose a novel Dual KMax UX-Net framework that leverages labeled data to guide the extraction of information from unlabeled data. Our approach is based on a mutual learning strategy that incorporates two modules: 3D UX-Net as our backbone meta-architecture and KMax decoder to enhance the segmentation performance. Extensive experiments on the Atrial Segmentation Challenge dataset have shown that our method can significantly improve performance by merging unlabeled data. Meanwhile, our framework outperforms state-of-the-art semi-supervised learning methods on 10\% and 20\% labeled settings. Code located at: https://github.com/Rows21/DK-UXNet.
A Survey of Temporal Credit Assignment in Deep Reinforcement Learning
Dec 02, 2023The Credit Assignment Problem (CAP) refers to the longstanding challenge of Reinforcement Learning (RL) agents to associate actions with their long-term consequences. Solving the CAP is a crucial step towards the successful deployment of RL in the real world since most decision problems provide feedback that is noisy, delayed, and with little or no information about the causes. These conditions make it hard to distinguish serendipitous outcomes from those caused by informed decision-making. However, the mathematical nature of credit and the CAP remains poorly understood and defined. In this survey, we review the state of the art of Temporal Credit Assignment (CA) in deep RL. We propose a unifying formalism for credit that enables equitable comparisons of state of the art algorithms and improves our understanding of the trade-offs between the various methods. We cast the CAP as the problem of learning the influence of an action over an outcome from a finite amount of experience. We discuss the challenges posed by delayed effects, transpositions, and a lack of action influence, and analyse how existing methods aim to address them. Finally, we survey the protocols to evaluate a credit assignment method, and suggest ways to diagnoses the sources of struggle for different credit assignment methods. Overall, this survey provides an overview of the field for new-entry practitioners and researchers, it offers a coherent perspective for scholars looking to expedite the starting stages of a new study on the CAP, and it suggests potential directions for future research