 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Shape Matters: Detecting Vertebral Fractures Using Differentiable Point-Based Shape Decoding
Dec 08, 2023
Degenerative spinal pathologies are highly prevalent among the elderly population. Timely diagnosis of osteoporotic fractures and other degenerative deformities facilitates proactive measures to mitigate the risk of severe back pain and disability. In this study, we specifically explore the use of shape auto-encoders for vertebrae, taking advantage of advancements in automated multi-label segmentation and the availability of large datasets for unsupervised learning. Our shape auto-encoders are trained on a large set of vertebrae surface patches, leveraging the vast amount of available data for vertebra segmentation. This addresses the label scarcity problem faced when learning shape information of vertebrae from image intensities. Based on the learned shape features we train an MLP to detect vertebral body fractures. Using segmentation masks that were automatically generated using the TotalSegmentator, our proposed method achieves an AUC of 0.901 on the VerSe19 testset. This outperforms image-based and surface-based end-to-end trained models. Additionally, our results demonstrate that pre-training the models in an unsupervised manner enhances geometric methods like PointNet and DGCNN. Our findings emphasise the advantages of explicitly learning shape features for diagnosing osteoporotic vertebrae fractures. This approach improves the reliability of classification results and reduces the need for annotated labels. This study provides novel insights into the effectiveness of various encoder-decoder models for shape analysis of vertebrae and proposes a new decoder architecture: the point-based shape decoder.
Zoology: Measuring and Improving Recall in Efficient Language Models
Dec 08, 2023Attention-free language models that combine gating and convolutions are growing in popularity due to their efficiency and increasingly competitive performance. To better understand these architectures, we pretrain a suite of 17 attention and "gated-convolution" language models, finding that SoTA gated-convolution architectures still underperform attention by up to 2.1 perplexity points on the Pile. In fine-grained analysis, we find 82% of the gap is explained by each model's ability to recall information that is previously mentioned in-context, e.g. "Hakuna Matata means no worries Hakuna Matata it means no" $\rightarrow$ "??". On this task, termed "associative recall", we find that attention outperforms gated-convolutions by a large margin: a 70M parameter attention model outperforms a 1.4 billion parameter gated-convolution model on associative recall. This is surprising because prior work shows gated convolutions can perfectly solve synthetic tests for AR capability. To close the gap between synthetics and real language, we develop a new formalization of the task called multi-query associative recall (MQAR) that better reflects actual language. We perform an empirical and theoretical study of MQAR that elucidates differences in the parameter-efficiency of attention and gated-convolution recall. Informed by our analysis, we evaluate simple convolution-attention hybrids and show that hybrids with input-dependent sparse attention patterns can close 97.4% of the gap to attention, while maintaining sub-quadratic scaling. Our code is accessible at: https://github.com/HazyResearch/zoology.
Visual Grounding of Whole Radiology Reports for 3D CT Images
Dec 08, 2023Building a large-scale training dataset is an essential problem in the development of medical image recognition systems. Visual grounding techniques, which automatically associate objects in images with corresponding descriptions, can facilitate labeling of large number of images. However, visual grounding of radiology reports for CT images remains challenging, because so many kinds of anomalies are detectable via CT imaging, and resulting report descriptions are long and complex. In this paper, we present the first visual grounding framework designed for CT image and report pairs covering various body parts and diverse anomaly types. Our framework combines two components of 1) anatomical segmentation of images, and 2) report structuring. The anatomical segmentation provides multiple organ masks of given CT images, and helps the grounding model recognize detailed anatomies. The report structuring helps to accurately extract information regarding the presence, location, and type of each anomaly described in corresponding reports. Given the two additional image/report features, the grounding model can achieve better localization. In the verification process, we constructed a large-scale dataset with region-description correspondence annotations for 10,410 studies of 7,321 unique patients. We evaluated our framework using grounding accuracy, the percentage of correctly localized anomalies, as a metric and demonstrated that the combination of the anatomical segmentation and the report structuring improves the performance with a large margin over the baseline model (66.0% vs 77.8%). Comparison with the prior techniques also showed higher performance of our method.
* 14 pages, 7 figures. Accepted at MICCAI 2023
TaskMet: Task-Driven Metric Learning for Model Learning
Dec 08, 2023Deep learning models are often deployed in downstream tasks that the training procedure may not be aware of. For example, models solely trained to achieve accurate predictions may struggle to perform well on downstream tasks because seemingly small prediction errors may incur drastic task errors. The standard end-to-end learning approach is to make the task loss differentiable or to introduce a differentiable surrogate that the model can be trained on. In these settings, the task loss needs to be carefully balanced with the prediction loss because they may have conflicting objectives. We propose take the task loss signal one level deeper than the parameters of the model and use it to learn the parameters of the loss function the model is trained on, which can be done by learning a metric in the prediction space. This approach does not alter the optimal prediction model itself, but rather changes the model learning to emphasize the information important for the downstream task. This enables us to achieve the best of both worlds: a prediction model trained in the original prediction space while also being valuable for the desired downstream task. We validate our approach through experiments conducted in two main settings: 1) decision-focused model learning scenarios involving portfolio optimization and budget allocation, and 2) reinforcement learning in noisy environments with distracting states. The source code to reproduce our experiments is available at https://github.com/facebookresearch/taskmet
Multi-View Spectrogram Transformer for Respiratory Sound Classification
Dec 05, 2023Deep neural networks have been applied to audio spectrograms for respiratory sound classification. Existing models often treat the spectrogram as a synthetic image while overlooking its physical characteristics. In this paper, a Multi-View Spectrogram Transformer (MVST) is proposed to embed different views of time-frequency characteristics into the vision transformer. Specifically, the proposed MVST splits the mel-spectrogram into different sized patches, representing the multi-view acoustic elements of a respiratory sound. These patches and positional embeddings are then fed into transformer encoders to extract the attentional information among patches through a self-attention mechanism. Finally, a gated fusion scheme is designed to automatically weigh the multi-view features to highlight the best one in a specific scenario. Experimental results on the ICBHI dataset demonstrate that the proposed MVST significantly outperforms state-of-the-art methods for classifying respiratory sounds.
Transformer-empowered Multi-modal Item Embedding for Enhanced Image Search in E-Commerce
Nov 29, 2023Over the past decade, significant advances have been made in the field of image search for e-commerce applications. Traditional image-to-image retrieval models, which focus solely on image details such as texture, tend to overlook useful semantic information contained within the images. As a result, the retrieved products might possess similar image details, but fail to fulfil the user's search goals. Moreover, the use of image-to-image retrieval models for products containing multiple images results in significant online product feature storage overhead and complex mapping implementations. In this paper, we report the design and deployment of the proposed Multi-modal Item Embedding Model (MIEM) to address these limitations. It is capable of utilizing both textual information and multiple images about a product to construct meaningful product features. By leveraging semantic information from images, MIEM effectively supplements the image search process, improving the overall accuracy of retrieval results. MIEM has become an integral part of the Shopee image search platform. Since its deployment in March 2023, it has achieved a remarkable 9.90% increase in terms of clicks per user and a 4.23% boost in terms of orders per user for the image search feature on the Shopee e-commerce platform.
Multi-scale Semantic Correlation Mining for Visible-Infrared Person Re-Identification
Nov 24, 2023The main challenge in the Visible-Infrared Person Re-Identification (VI-ReID) task lies in how to extract discriminative features from different modalities for matching purposes. While the existing well works primarily focus on minimizing the modal discrepancies, the modality information can not thoroughly be leveraged. To solve this problem, a Multi-scale Semantic Correlation Mining network (MSCMNet) is proposed to comprehensively exploit semantic features at multiple scales and simultaneously reduce modality information loss as small as possible in feature extraction. The proposed network contains three novel components. Firstly, after taking into account the effective utilization of modality information, the Multi-scale Information Correlation Mining Block (MIMB) is designed to explore semantic correlations across multiple scales. Secondly, in order to enrich the semantic information that MIMB can utilize, a quadruple-stream feature extractor (QFE) with non-shared parameters is specifically designed to extract information from different dimensions of the dataset. Finally, the Quadruple Center Triplet Loss (QCT) is further proposed to address the information discrepancy in the comprehensive features. Extensive experiments on the SYSU-MM01, RegDB, and LLCM datasets demonstrate that the proposed MSCMNet achieves the greatest accuracy.
Performance of externally validated machine learning models based on histopathology images for the diagnosis, classification, prognosis, or treatment outcome prediction in female breast cancer: A systematic review
Dec 09, 2023Numerous machine learning (ML) models have been developed for breast cancer using various types of data. Successful external validation (EV) of ML models is important evidence of their generalizability. The aim of this systematic review was to assess the performance of externally validated ML models based on histopathology images for diagnosis, classification, prognosis, or treatment outcome prediction in female breast cancer. A systematic search of MEDLINE, EMBASE, CINAHL, IEEE, MICCAI, and SPIE conferences was performed for studies published between January 2010 and February 2022. The Prediction Model Risk of Bias Assessment Tool (PROBAST) was employed, and the results were narratively described. Of the 2011 non-duplicated citations, 8 journal articles and 2 conference proceedings met inclusion criteria. Three studies externally validated ML models for diagnosis, 4 for classification, 2 for prognosis, and 1 for both classification and prognosis. Most studies used Convolutional Neural Networks and one used logistic regression algorithms. For diagnostic/classification models, the most common performance metrics reported in the EV were accuracy and area under the curve, which were greater than 87% and 90%, respectively, using pathologists' annotations as ground truth. The hazard ratios in the EV of prognostic ML models were between 1.7 (95% CI, 1.2-2.6) and 1.8 (95% CI, 1.3-2.7) to predict distant disease-free survival; 1.91 (95% CI, 1.11-3.29) for recurrence, and between 0.09 (95% CI, 0.01-0.70) and 0.65 (95% CI, 0.43-0.98) for overall survival, using clinical data as ground truth. Despite EV being an important step before the clinical application of a ML model, it hasn't been performed routinely. The large variability in the training/validation datasets, methods, performance metrics, and reported information limited the comparison of the models and the analysis of their results (...)
DeepFidelity: Perceptual Forgery Fidelity Assessment for Deepfake Detection
Dec 07, 2023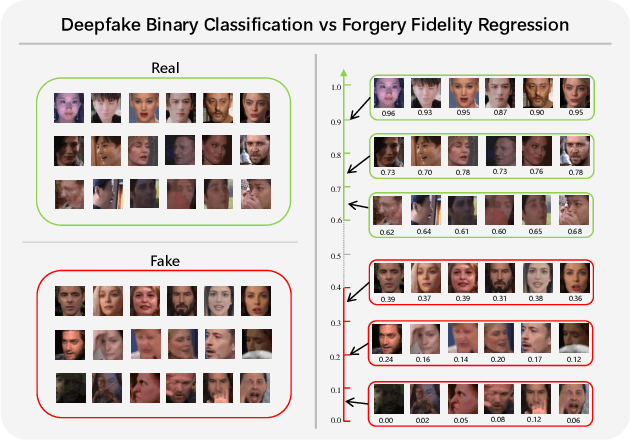
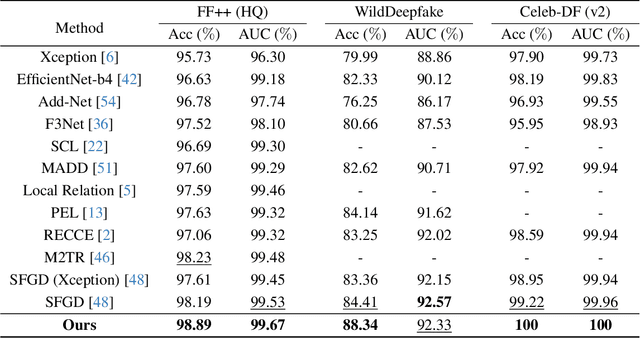
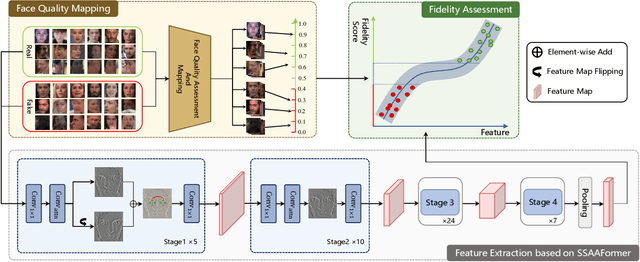
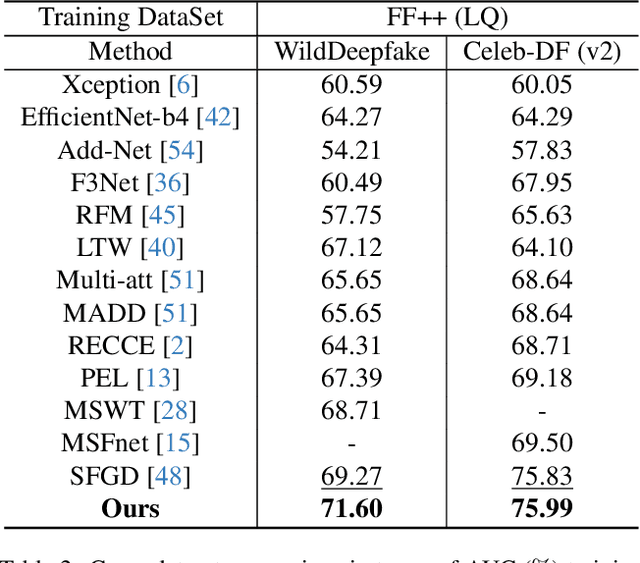
Deepfake detection refers to detecting artificially generated or edited faces in images or videos, which plays an essential role in visual information security. Despite promising progress in recent years, Deepfake detection remains a challenging problem due to the complexity and variability of face forgery techniques. Existing Deepfake detection methods are often devoted to extracting features by designing sophisticated networks but ignore the influence of perceptual quality of faces. Considering the complexity of the quality distribution of both real and fake faces, we propose a novel Deepfake detection framework named DeepFidelity to adaptively distinguish real and fake faces with varying image quality by mining the perceptual forgery fidelity of face images. Specifically, we improve the model's ability to identify complex samples by mapping real and fake face data of different qualities to different scores to distinguish them in a more detailed way. In addition, we propose a network structure called Symmetric Spatial Attention Augmentation based vision Transformer (SSAAFormer), which uses the symmetry of face images to promote the network to model the geographic long-distance relationship at the shallow level and augment local features. Extensive experiments on multiple benchmark datasets demonstrate the superiority of the proposed method over state-of-the-art methods.
Rapid detection of rare events from in situ X-ray diffraction data using machine learning
Dec 07, 2023High-energy X-ray diffraction methods can non-destructively map the 3D microstructure and associated attributes of metallic polycrystalline engineering materials in their bulk form. These methods are often combined with external stimuli such as thermo-mechanical loading to take snapshots over time of the evolving microstructure and attributes. However, the extreme data volumes and the high costs of traditional data acquisition and reduction approaches pose a barrier to quickly extracting actionable insights and improving the temporal resolution of these snapshots. Here we present a fully automated technique capable of rapidly detecting the onset of plasticity in high-energy X-ray microscopy data. Our technique is computationally faster by at least 50 times than the traditional approaches and works for data sets that are up to 9 times sparser than a full data set. This new technique leverages self-supervised image representation learning and clustering to transform massive data into compact, semantic-rich representations of visually salient characteristics (e.g., peak shapes). These characteristics can be a rapid indicator of anomalous events such as changes in diffraction peak shapes. We anticipate that this technique will provide just-in-time actionable information to drive smarter experiments that effectively deploy multi-modal X-ray diffraction methods that span many decades of length scales.