 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Can Electromagnetic Information Theory Improve Wireless Systems? A Channel Estimation Example
Oct 19, 2023
Electromagnetic information theory (EIT) is an emerging interdisciplinary subject that integrates classical Maxwell electromagnetics and Shannon information theory. The goal of EIT is to uncover the information transmission mechanisms from an electromagnetic (EM) perspective in wireless systems. Existing works on EIT are mainly focused on the analysis of degrees-of-freedom (DoF), system capacity, and characteristics of the electromagnetic channel. However, these works do not clarify how EIT can improve wireless communication systems. To answer this question, in this paper, we provide a novel demonstration of the application of EIT. By integrating EM knowledge into the classical MMSE channel estimator, we observe for the first time that EIT is capable of improving the channel estimation performace. Specifically, the EM knowledge is first encoded into a spatio-temporal correlation function (STCF), which we term as the EM kernel. This EM kernel plays the role of side information to the channel estimator. Since the EM kernel takes the form of Gaussian processes (GP), we propose the EIT-based Gaussian process regression (EIT-GPR) to derive the channel estimations. In addition, since the EM kernel allows parameter tuning, we propose EM kernel learning to fit the EM kernel to channel observations. Simulation results show that the application of EIT to the channel estimator enables it to outperform traditional isotropic MMSE algorithm, thus proving the practical values of EIT.
Learn to Unlearn for Deep Neural Networks: Minimizing Unlearning Interference with Gradient Projection
Dec 07, 2023Recent data-privacy laws have sparked interest in machine unlearning, which involves removing the effect of specific training samples from a learnt model as if they were never present in the original training dataset. The challenge of machine unlearning is to discard information about the ``forget'' data in the learnt model without altering the knowledge about the remaining dataset and to do so more efficiently than the naive retraining approach. To achieve this, we adopt a projected-gradient based learning method, named as Projected-Gradient Unlearning (PGU), in which the model takes steps in the orthogonal direction to the gradient subspaces deemed unimportant for the retaining dataset, so as to its knowledge is preserved. By utilizing Stochastic Gradient Descent (SGD) to update the model weights, our method can efficiently scale to any model and dataset size. We provide empirically evidence to demonstrate that our unlearning method can produce models that behave similar to models retrained from scratch across various metrics even when the training dataset is no longer accessible. Our code is available at https://github.com/hnanhtuan/projected_gradient_unlearning.
Analysis of Coding Gain Due to In-Loop Reshaping
Dec 07, 2023Reshaping, a point operation that alters the characteristics of signals, has been shown capable of improving the compression ratio in video coding practices. Out-of-loop reshaping that directly modifies the input video signal was first adopted as the supplemental enhancement information~(SEI) for the HEVC/H.265 without the need of altering the core design of the video codec. VVC/H.266 further improves the coding efficiency by adopting in-loop reshaping that modifies the residual signal being processed in the hybrid coding loop. In this paper, we theoretically analyze the rate-distortion performance of the in-loop reshaping and use experiments to verify the theoretical result. We prove that the in-loop reshaping can improve coding efficiency when the entropy coder adopted in the coding pipeline is suboptimal, which is in line with the practical scenarios that video codecs operate in. We derive the PSNR gain in a closed form and show that the theoretically predicted gain is consistent with that measured from experiments using standard testing video sequences.
MuRF: Multi-Baseline Radiance Fields
Dec 07, 2023
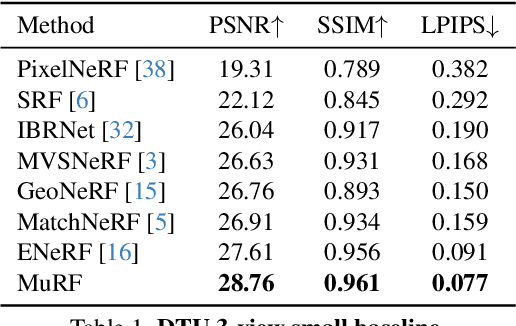
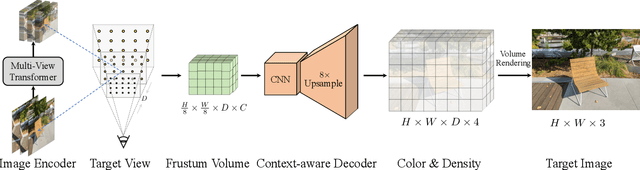
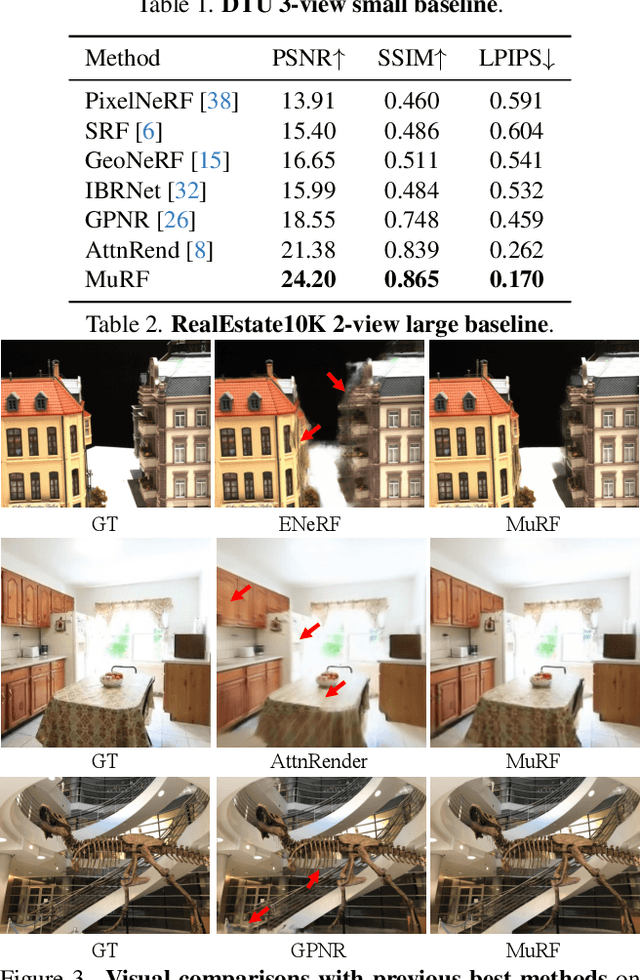
We present Multi-Baseline Radiance Fields (MuRF), a general feed-forward approach to solving sparse view synthesis under multiple different baseline settings (small and large baselines, and different number of input views). To render a target novel view, we discretize the 3D space into planes parallel to the target image plane, and accordingly construct a target view frustum volume. Such a target volume representation is spatially aligned with the target view, which effectively aggregates relevant information from the input views for high-quality rendering. It also facilitates subsequent radiance field regression with a convolutional network thanks to its axis-aligned nature. The 3D context modeled by the convolutional network enables our method to synthesis sharper scene structures than prior works. Our MuRF achieves state-of-the-art performance across multiple different baseline settings and diverse scenarios ranging from simple objects (DTU) to complex indoor and outdoor scenes (RealEstate10K and LLFF). We also show promising zero-shot generalization abilities on the Mip-NeRF 360 dataset, demonstrating the general applicability of MuRF.
Free3D: Consistent Novel View Synthesis without 3D Representation
Dec 07, 2023We introduce Free3D, a simple approach designed for open-set novel view synthesis (NVS) from a single image. Similar to Zero-1-to-3, we start from a pre-trained 2D image generator for generalization, and fine-tune it for NVS. Compared to recent and concurrent works, we obtain significant improvements without resorting to an explicit 3D representation, which is slow and memory-consuming or training an additional 3D network. We do so by encoding better the target camera pose via a new per-pixel ray conditioning normalization (RCN) layer. The latter injects pose information in the underlying 2D image generator by telling each pixel its specific viewing direction. We also improve multi-view consistency via a light-weight multi-view attention layer and multi-view noise sharing. We train Free3D on the Objaverse dataset and demonstrate excellent generalization to various new categories in several new datasets, including OminiObject3D and GSO. We hope our simple and effective approach will serve as a solid baseline and help future research in NVS with more accuracy pose. The project page is available at https://chuanxiaz.com/free3d/.
Graph Metanetworks for Processing Diverse Neural Architectures
Dec 07, 2023Neural networks efficiently encode learned information within their parameters. Consequently, many tasks can be unified by treating neural networks themselves as input data. When doing so, recent studies demonstrated the importance of accounting for the symmetries and geometry of parameter spaces. However, those works developed architectures tailored to specific networks such as MLPs and CNNs without normalization layers, and generalizing such architectures to other types of networks can be challenging. In this work, we overcome these challenges by building new metanetworks - neural networks that take weights from other neural networks as input. Put simply, we carefully build graphs representing the input neural networks and process the graphs using graph neural networks. Our approach, Graph Metanetworks (GMNs), generalizes to neural architectures where competing methods struggle, such as multi-head attention layers, normalization layers, convolutional layers, ResNet blocks, and group-equivariant linear layers. We prove that GMNs are expressive and equivariant to parameter permutation symmetries that leave the input neural network functions unchanged. We validate the effectiveness of our method on several metanetwork tasks over diverse neural network architectures.
Privacy-preserving quantum federated learning via gradient hiding
Dec 07, 2023Distributed quantum computing, particularly distributed quantum machine learning, has gained substantial prominence for its capacity to harness the collective power of distributed quantum resources, transcending the limitations of individual quantum nodes. Meanwhile, the critical concern of privacy within distributed computing protocols remains a significant challenge, particularly in standard classical federated learning (FL) scenarios where data of participating clients is susceptible to leakage via gradient inversion attacks by the server. This paper presents innovative quantum protocols with quantum communication designed to address the FL problem, strengthen privacy measures, and optimize communication efficiency. In contrast to previous works that leverage expressive variational quantum circuits or differential privacy techniques, we consider gradient information concealment using quantum states and propose two distinct FL protocols, one based on private inner-product estimation and the other on incremental learning. These protocols offer substantial advancements in privacy preservation with low communication resources, forging a path toward efficient quantum communication-assisted FL protocols and contributing to the development of secure distributed quantum machine learning, thus addressing critical privacy concerns in the quantum computing era.
Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
Dec 07, 2023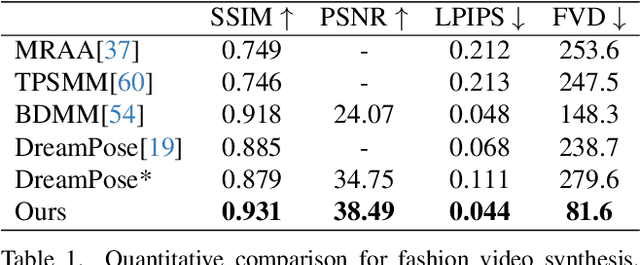
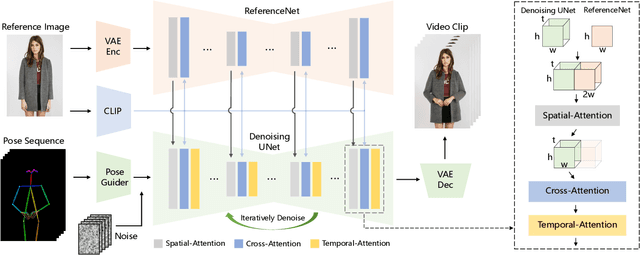
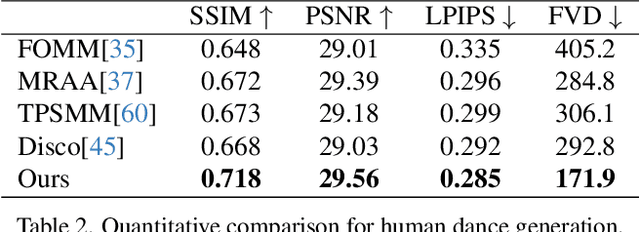

Character Animation aims to generating character videos from still images through driving signals. Currently, diffusion models have become the mainstream in visual generation research, owing to their robust generative capabilities. However, challenges persist in the realm of image-to-video, especially in character animation, where temporally maintaining consistency with detailed information from character remains a formidable problem. In this paper, we leverage the power of diffusion models and propose a novel framework tailored for character animation. To preserve consistency of intricate appearance features from reference image, we design ReferenceNet to merge detail features via spatial attention. To ensure controllability and continuity, we introduce an efficient pose guider to direct character's movements and employ an effective temporal modeling approach to ensure smooth inter-frame transitions between video frames. By expanding the training data, our approach can animate arbitrary characters, yielding superior results in character animation compared to other image-to-video methods. Furthermore, we evaluate our method on benchmarks for fashion video and human dance synthesis, achieving state-of-the-art results.
NeuSD: Surface Completion with Multi-View Text-to-Image Diffusion
Dec 07, 2023We present a novel method for 3D surface reconstruction from multiple images where only a part of the object of interest is captured. Our approach builds on two recent developments: surface reconstruction using neural radiance fields for the reconstruction of the visible parts of the surface, and guidance of pre-trained 2D diffusion models in the form of Score Distillation Sampling (SDS) to complete the shape in unobserved regions in a plausible manner. We introduce three components. First, we suggest employing normal maps as a pure geometric representation for SDS instead of color renderings which are entangled with the appearance information. Second, we introduce the freezing of the SDS noise during training which results in more coherent gradients and better convergence. Third, we propose Multi-View SDS as a way to condition the generation of the non-observable part of the surface without fine-tuning or making changes to the underlying 2D Stable Diffusion model. We evaluate our approach on the BlendedMVS dataset demonstrating significant qualitative and quantitative improvements over competing methods.
A Pipeline For Discourse Circuits From CCG
Nov 29, 2023There is a significant disconnect between linguistic theory and modern NLP practice, which relies heavily on inscrutable black-box architectures. DisCoCirc is a newly proposed model for meaning that aims to bridge this divide, by providing neuro-symbolic models that incorporate linguistic structure. DisCoCirc represents natural language text as a `circuit' that captures the core semantic information of the text. These circuits can then be interpreted as modular machine learning models. Additionally, DisCoCirc fulfils another major aim of providing an NLP model that can be implemented on near-term quantum computers. In this paper we describe a software pipeline that converts English text to its DisCoCirc representation. The pipeline achieves coverage over a large fragment of the English language. It relies on Combinatory Categorial Grammar (CCG) parses of the input text as well as coreference resolution information. This semantic and syntactic information is used in several steps to convert the text into a simply-typed $\lambda$-calculus term, and then into a circuit diagram. This pipeline will enable the application of the DisCoCirc framework to NLP tasks, using both classical and quantum approaches.