 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Zero-Shot Point Cloud Registration
Dec 08, 2023
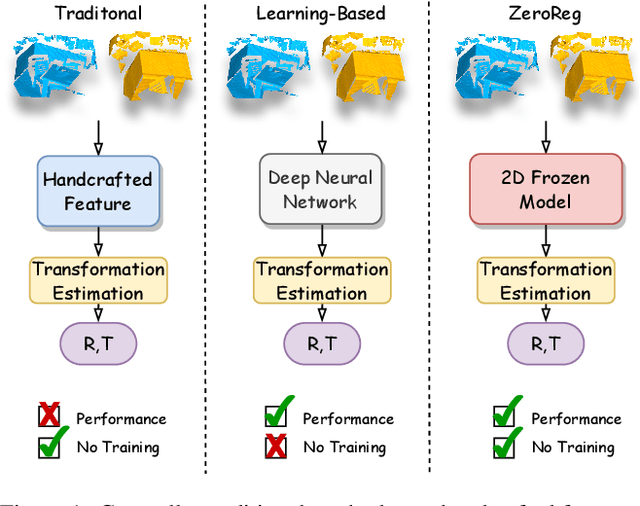
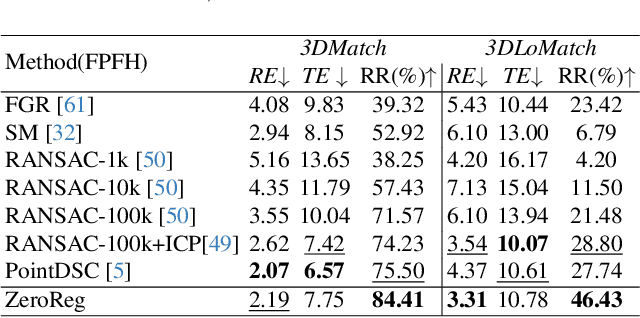
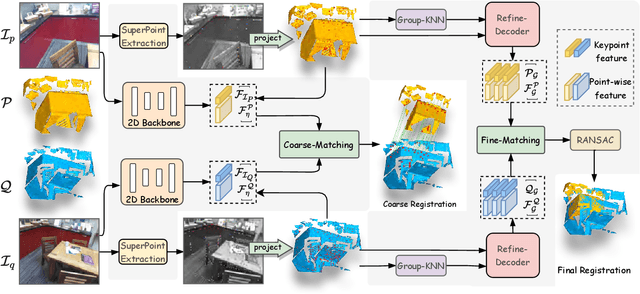
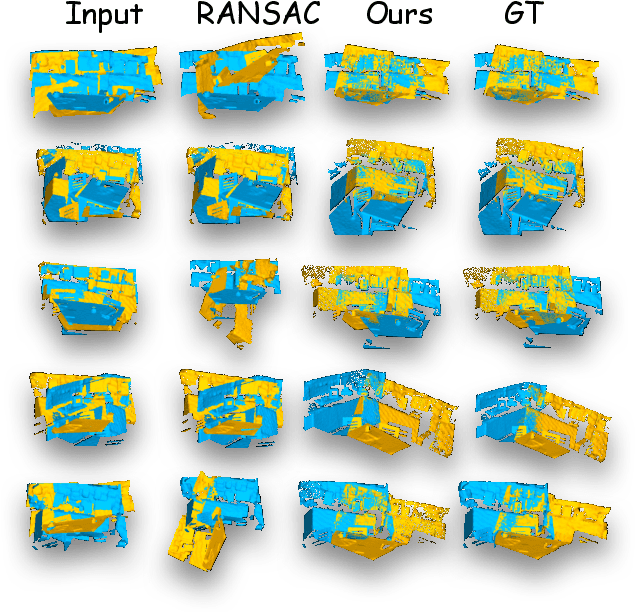
Learning-based point cloud registration approaches have significantly outperformed their traditional counterparts. However, they typically require extensive training on specific datasets. In this paper, we propose , the first zero-shot point cloud registration approach that eliminates the need for training on point cloud datasets. The cornerstone of ZeroReg is the novel transfer of image features from keypoints to the point cloud, enriched by aggregating information from 3D geometric neighborhoods. Specifically, we extract keypoints and features from 2D image pairs using a frozen pretrained 2D backbone. These features are then projected in 3D, and patches are constructed by searching for neighboring points. We integrate the geometric and visual features of each point using our novel parameter-free geometric decoder. Subsequently, the task of determining correspondences between point clouds is formulated as an optimal transport problem. Extensive evaluations of ZeroReg demonstrate its competitive performance against both traditional and learning-based methods. On benchmarks such as 3DMatch, 3DLoMatch, and ScanNet, ZeroReg achieves impressive Recall Ratios (RR) of over 84%, 46%, and 75%, respectively.
ControlRoom3D: Room Generation using Semantic Proxy Rooms
Dec 08, 2023Manually creating 3D environments for AR/VR applications is a complex process requiring expert knowledge in 3D modeling software. Pioneering works facilitate this process by generating room meshes conditioned on textual style descriptions. Yet, many of these automatically generated 3D meshes do not adhere to typical room layouts, compromising their plausibility, e.g., by placing several beds in one bedroom. To address these challenges, we present ControlRoom3D, a novel method to generate high-quality room meshes. Central to our approach is a user-defined 3D semantic proxy room that outlines a rough room layout based on semantic bounding boxes and a textual description of the overall room style. Our key insight is that when rendered to 2D, this 3D representation provides valuable geometric and semantic information to control powerful 2D models to generate 3D consistent textures and geometry that aligns well with the proxy room. Backed up by an extensive study including quantitative metrics and qualitative user evaluations, our method generates diverse and globally plausible 3D room meshes, thus empowering users to design 3D rooms effortlessly without specialized knowledge.
Quantitative perfusion maps using a novelty spatiotemporal convolutional neural network
Dec 08, 2023Dynamic susceptibility contrast magnetic resonance imaging (DSC-MRI) is widely used to evaluate acute ischemic stroke to distinguish salvageable tissue and infarct core. For this purpose, traditional methods employ deconvolution techniques, like singular value decomposition, which are known to be vulnerable to noise, potentially distorting the derived perfusion parameters. However, deep learning technology could leverage it, which can accurately estimate clinical perfusion parameters compared to traditional clinical approaches. Therefore, this study presents a perfusion parameters estimation network that considers spatial and temporal information, the Spatiotemporal Network (ST-Net), for the first time. The proposed network comprises a designed physical loss function to enhance model performance further. The results indicate that the network can accurately estimate perfusion parameters, including cerebral blood volume (CBV), cerebral blood flow (CBF), and time to maximum of the residual function (Tmax). The structural similarity index (SSIM) mean values for CBV, CBF, and Tmax parameters were 0.952, 0.943, and 0.863, respectively. The DICE score for the hypo-perfused region reached 0.859, demonstrating high consistency. The proposed model also maintains time efficiency, closely approaching the performance of commercial gold-standard software.
Critical Analysis of 5G Networks Traffic Intrusion using PCA, t-SNE and UMAP Visualization and Classifying Attacks
Dec 08, 2023Networks, threat models, and malicious actors are advancing quickly. With the increased deployment of the 5G networks, the security issues of the attached 5G physical devices have also increased. Therefore, artificial intelligence based autonomous end-to-end security design is needed that can deal with incoming threats by detecting network traffic anomalies. To address this requirement, in this research, we used a recently published 5G traffic dataset, 5G-NIDD, to detect network traffic anomalies using machine and deep learning approaches. First, we analyzed the dataset using three visualization techniques: t-Distributed Stochastic Neighbor Embedding (t-SNE), Uniform Manifold Approximation and Projection (UMAP), and Principal Component Analysis (PCA). Second, we reduced the data dimensionality using mutual information and PCA techniques. Third, we solve the class imbalance issue by inserting synthetic records of minority classes. Last, we performed classification using six different classifiers and presented the evaluation metrics. We received the best results when K-Nearest Neighbors classifier was used: accuracy (97.2%), detection rate (96.7%), and false positive rate (2.2%).
SiCP: Simultaneous Individual and Cooperative Perception for 3D Object Detection in Connected and Automated Vehicles
Dec 08, 2023Cooperative perception for connected and automated vehicles is traditionally achieved through the fusion of feature maps from two or more vehicles. However, the absence of feature maps shared from other vehicles can lead to a significant decline in object detection performance for cooperative perception models compared to standalone 3D detection models. This drawback impedes the adoption of cooperative perception as vehicle resources are often insufficient to concurrently employ two perception models. To tackle this issue, we present Simultaneous Individual and Cooperative Perception (SiCP), a generic framework that supports a wide range of the state-of-the-art standalone perception backbones and enhances them with a novel Dual-Perception Network (DP-Net) designed to facilitate both individual and cooperative perception. In addition to its lightweight nature with only 0.13M parameters, DP-Net is robust and retains crucial gradient information during feature map fusion. As demonstrated in a comprehensive evaluation on the OPV2V dataset, thanks to DP-Net, SiCP surpasses state-of-the-art cooperative perception solutions while preserving the performance of standalone perception solutions.
ReconU-Net: a direct PET image reconstruction using U-Net architecture with back projection-induced skip connection
Dec 05, 2023[Objective] This study aims to introduce a novel back projection-induced U-Net-shaped architecture, called ReconU-Net, for deep learning-based direct positron emission tomography (PET) image reconstruction. Additionally, our objective is to analyze the behavior of direct PET image reconstruction and gain deeper insights by comparing the proposed ReconU-Net architecture with other encoder-decoder architectures without skip connections. [Approach] The proposed ReconU-Net architecture uniquely integrates the physical model of the back projection operation into the skip connection. This distinctive feature facilitates the effective transfer of intrinsic spatial information from the input sinogram to the reconstructed image via an embedded physical model. The proposed ReconU-Net was trained using Monte Carlo simulation data from the Brainweb phantom and tested on both simulated and real Hoffman brain phantom data. [Main results] The proposed ReconU-Net method generated a reconstructed image with a more accurate structure compared to other deep learning-based direct reconstruction methods. Further analysis showed that the proposed ReconU-Net architecture has the ability to transfer features of multiple resolutions, especially non-abstract high-resolution information, through skip connections. Despite limited training on simulated data, the proposed ReconU-Net successfully reconstructed the real Hoffman brain phantom, unlike other deep learning-based direct reconstruction methods, which failed to produce a reconstructed image. [Significance] The proposed ReconU-Net can improve the fidelity of direct PET image reconstruction, even when dealing with small training datasets, by leveraging the synergistic relationship between data-driven modeling and the physics model of the imaging process.
INarIG: Iterative Non-autoregressive Instruct Generation Model For Word-Level Auto Completion
Nov 30, 2023Computer-aided translation (CAT) aims to enhance human translation efficiency and is still important in scenarios where machine translation cannot meet quality requirements. One fundamental task within this field is Word-Level Auto Completion (WLAC). WLAC predicts a target word given a source sentence, translation context, and a human typed character sequence. Previous works either employ word classification models to exploit contextual information from both sides of the target word or directly disregarded the dependencies from the right-side context. Furthermore, the key information, i.e. human typed sequences, is only used as prefix constraints in the decoding module. In this paper, we propose the INarIG (Iterative Non-autoregressive Instruct Generation) model, which constructs the human typed sequence into Instruction Unit and employs iterative decoding with subwords to fully utilize input information given in the task. Our model is more competent in dealing with low-frequency words (core scenario of this task), and achieves state-of-the-art results on the WMT22 and benchmark datasets, with a maximum increase of over 10% prediction accuracy.
Asymmetric leader-laggard cluster synchronization for collective decision-making with laser network
Dec 05, 2023Photonic accelerators have recently attracted soaring interest, harnessing the ultimate nature of light for information processing. Collective decision-making with a laser network, employing the chaotic and synchronous dynamics of optically interconnected lasers to address the competitive multi-armed bandit (CMAB) problem, is a highly compelling approach due to its scalability and experimental feasibility. We investigated essential network structures for collective decision-making through quantitative stability analysis. Moreover, we demonstrated the asymmetric preferences of players in the CMAB problem, extending its functionality to more practical applications. Our study highlights the capability and significance of machine learning built upon chaotic lasers and photonic devices.
Improved Face Representation via Joint Label Classification and Supervised Contrastive Clustering
Dec 07, 2023Face clustering tasks can learn hierarchical semantic information from large-scale data, which has the potential to help facilitate face recognition. However, there are few works on this problem. This paper explores it by proposing a joint optimization task of label classification and supervised contrastive clustering to introduce the cluster knowledge to the traditional face recognition task in two ways. We first extend ArcFace with a cluster-guided angular margin to adjust the within-class feature distribution according to the hard level of face clustering. Secondly, we propose a supervised contrastive clustering approach to pull the features to the cluster center and propose the cluster-aligning procedure to align the cluster center and the learnable class center in the classifier for joint training. Finally, extensive qualitative and quantitative experiments on popular facial benchmarks demonstrate the effectiveness of our paradigm and its superiority over the existing approaches to face recognition.
A Structural-Clustering Based Active Learning for Graph Neural Networks
Dec 07, 2023In active learning for graph-structured data, Graph Neural Networks (GNNs) have shown effectiveness. However, a common challenge in these applications is the underutilization of crucial structural information. To address this problem, we propose the Structural-Clustering PageRank method for improved Active learning (SPA) specifically designed for graph-structured data. SPA integrates community detection using the SCAN algorithm with the PageRank scoring method for efficient and informative sample selection. SPA prioritizes nodes that are not only informative but also central in structure. Through extensive experiments, SPA demonstrates higher accuracy and macro-F1 score over existing methods across different annotation budgets and achieves significant reductions in query time. In addition, the proposed method only adds two hyperparameters, $\epsilon$ and $\mu$ in the algorithm to finely tune the balance between structural learning and node selection. This simplicity is a key advantage in active learning scenarios, where extensive hyperparameter tuning is often impractical.