 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AV2AV: Direct Audio-Visual Speech to Audio-Visual Speech Translation with Unified Audio-Visual Speech Representation
Dec 05, 2023
This paper proposes a novel direct Audio-Visual Speech to Audio-Visual Speech Translation (AV2AV) framework, where the input and output of the system are multimodal (i.e., audio and visual speech). With the proposed AV2AV, two key advantages can be brought: 1) We can perform real-like conversations with individuals worldwide in a virtual meeting by utilizing our own primary languages. In contrast to Speech-to-Speech Translation (A2A), which solely translates between audio modalities, the proposed AV2AV directly translates between audio-visual speech. This capability enhances the dialogue experience by presenting synchronized lip movements along with the translated speech. 2) We can improve the robustness of the spoken language translation system. By employing the complementary information of audio-visual speech, the system can effectively translate spoken language even in the presence of acoustic noise, showcasing robust performance. To mitigate the problem of the absence of a parallel AV2AV translation dataset, we propose to train our spoken language translation system with the audio-only dataset of A2A. This is done by learning unified audio-visual speech representations through self-supervised learning in advance to train the translation system. Moreover, we propose an AV-Renderer that can generate raw audio and video in parallel. It is designed with zero-shot speaker modeling, thus the speaker in source audio-visual speech can be maintained at the target translated audio-visual speech. The effectiveness of AV2AV is evaluated with extensive experiments in a many-to-many language translation setting. The demo page is available on https://choijeongsoo.github.io/av2av.
Robust UAV Position and Attitude Estimation using Multiple GNSS Receivers for Laser-based 3D Mapping
Dec 05, 2023Small-sized unmanned aerial vehicles (UAVs) have been widely investigated for use in a variety of applications such as remote sensing and aerial surveying. Direct three-dimensional (3D) mapping using a small-sized UAV equipped with a laser scanner is required for numerous remote sensing applications. In direct 3D mapping, the precise information about the position and attitude of the UAV is necessary for constructing 3D maps. In this study, we propose a novel and robust technique for estimating the position and attitude of small-sized UAVs by employing multiple low-cost and light-weight global navigation satellite system (GNSS) antennas/receivers. Using the "redundancy" of multiple GNSS receivers, we enhance the performance of real-time kinematic (RTK)-GNSS by employing single-frequency GNSS receivers. This method consists of two approaches: hybrid GNSS fix solutions and consistency examination of the GNSS signal strength. The fix rate of RTK-GNSS using single-frequency GNSS receivers can be highly enhanced to combine multiple RTK-GNSS to fix solutions in the multiple antennas. In addition, positioning accuracy and fix rate can be further enhanced to detect multipath signals by using multiple GNSS antennas. In this study, we developed a prototype UAV that is equipped with six GNSS antennas/receivers. From the static test results, we conclude that the proposed technique can enhance the accuracy of the position and attitude estimation in multipath environments. From the flight test, the proposed system could generate a 3D map with an accuracy of 5 cm.
* Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2019
Learning optimal integration of spatial and temporal information in noisy chemotaxis
Oct 16, 2023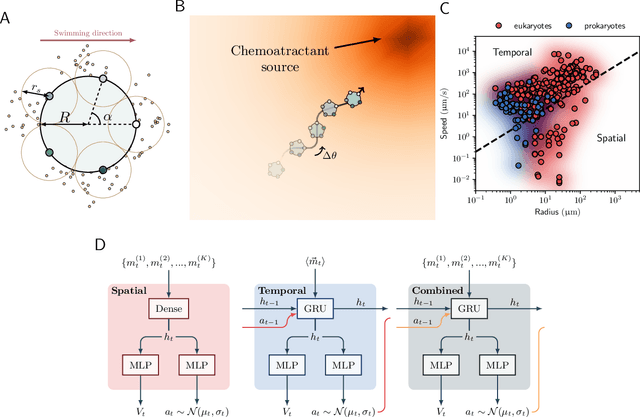
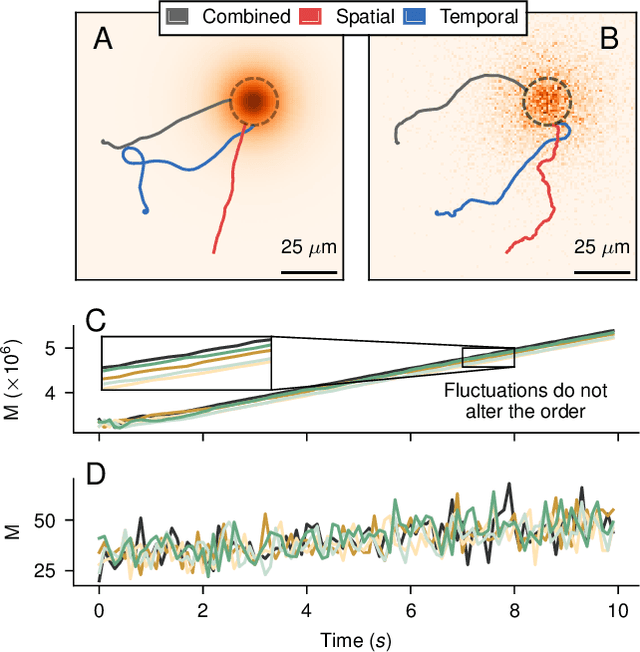
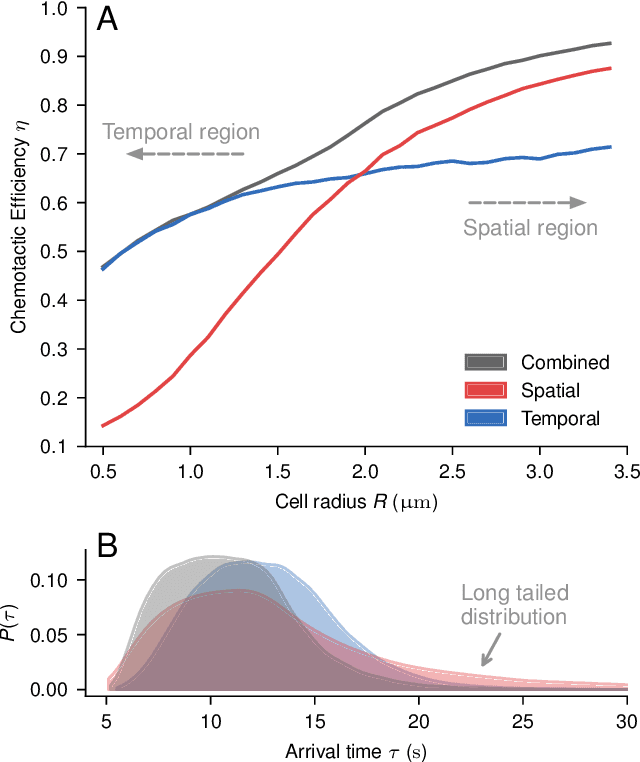
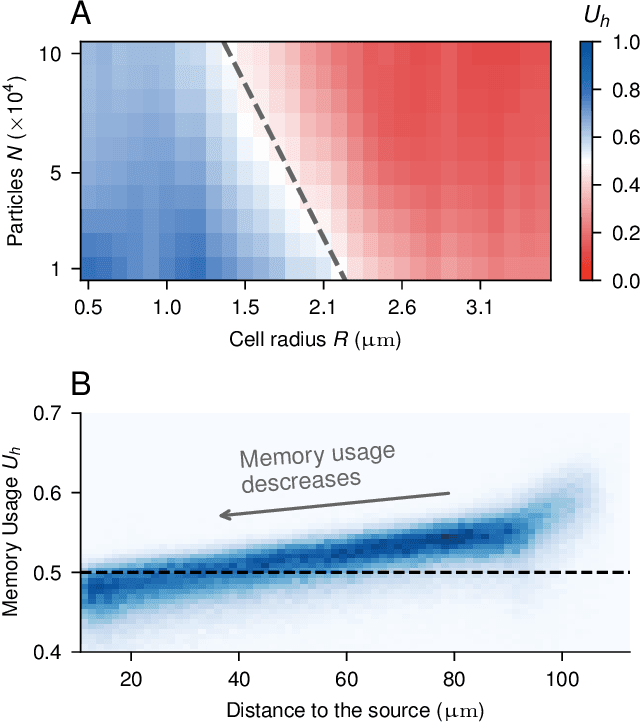
We investigate the boundary between chemotaxis driven by spatial estimation of gradients and chemotaxis driven by temporal estimation. While it is well known that spatial chemotaxis becomes disadvantageous for small organisms at high noise levels, it is unclear whether there is a discontinuous switch of optimal strategies or a continuous transition exists. Here, we employ deep reinforcement learning to study the possible integration of spatial and temporal information in an a priori unconstrained manner. We parameterize such a combined chemotactic policy by a recurrent neural network and evaluate it using a minimal theoretical model of a chemotactic cell. By comparing with constrained variants of the policy, we show that it converges to purely temporal and spatial strategies at small and large cell sizes, respectively. We find that the transition between the regimes is continuous, with the combined strategy outperforming in the transition region both the constrained variants as well as models that explicitly integrate spatial and temporal information. Finally, by utilizing the attribution method of integrated gradients, we show that the policy relies on a non-trivial combination of spatially and temporally derived gradient information in a ratio that varies dynamically during the chemotactic trajectories.
GPT Struct Me: Probing GPT Models on Narrative Entity Extraction
Nov 24, 2023The importance of systems that can extract structured information from textual data becomes increasingly pronounced given the ever-increasing volume of text produced on a daily basis. Having a system that can effectively extract such information in an interoperable manner would be an asset for several domains, be it finance, health, or legal. Recent developments in natural language processing led to the production of powerful language models that can, to some degree, mimic human intelligence. Such effectiveness raises a pertinent question: Can these models be leveraged for the extraction of structured information? In this work, we address this question by evaluating the capabilities of two state-of-the-art language models -- GPT-3 and GPT-3.5, commonly known as ChatGPT -- in the extraction of narrative entities, namely events, participants, and temporal expressions. This study is conducted on the Text2Story Lusa dataset, a collection of 119 Portuguese news articles whose annotation framework includes a set of entity structures along with several tags and attribute values. We first select the best prompt template through an ablation study over prompt components that provide varying degrees of information on a subset of documents of the dataset. Subsequently, we use the best templates to evaluate the effectiveness of the models on the remaining documents. The results obtained indicate that GPT models are competitive with out-of-the-box baseline systems, presenting an all-in-one alternative for practitioners with limited resources. By studying the strengths and limitations of these models in the context of information extraction, we offer insights that can guide future improvements and avenues to explore in this field.
The Mixtures and the Neural Critics: On the Pointwise Mutual Information Profiles of Fine Distributions
Oct 16, 2023Mutual information quantifies the dependence between two random variables and remains invariant under diffeomorphisms. In this paper, we explore the pointwise mutual information profile, an extension of mutual information that maintains this invariance. We analytically describe the profiles of multivariate normal distributions and introduce the family of fine distributions, for which the profile can be accurately approximated using Monte Carlo methods. We then show how fine distributions can be used to study the limitations of existing mutual information estimators, investigate the behavior of neural critics used in variational estimators, and understand the effect of experimental outliers on mutual information estimation. Finally, we show how fine distributions can be used to obtain model-based Bayesian estimates of mutual information, suitable for problems with available domain expertise in which uncertainty quantification is necessary.
SenTest: Evaluating Robustness of Sentence Encoders
Nov 29, 2023
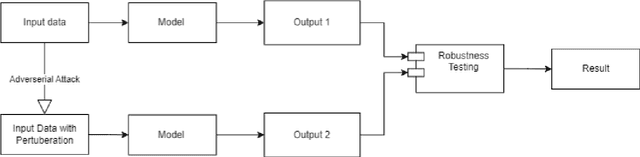


Contrastive learning has proven to be an effective method for pre-training models using weakly labeled data in the vision domain. Sentence transformers are the NLP counterparts to this architecture, and have been growing in popularity due to their rich and effective sentence representations. Having effective sentence representations is paramount in multiple tasks, such as information retrieval, retrieval augmented generation (RAG), and sentence comparison. Keeping in mind the deployability factor of transformers, evaluating the robustness of sentence transformers is of utmost importance. This work focuses on evaluating the robustness of the sentence encoders. We employ several adversarial attacks to evaluate its robustness. This system uses character-level attacks in the form of random character substitution, word-level attacks in the form of synonym replacement, and sentence-level attacks in the form of intra-sentence word order shuffling. The results of the experiments strongly undermine the robustness of sentence encoders. The models produce significantly different predictions as well as embeddings on perturbed datasets. The accuracy of the models can fall up to 15 percent on perturbed datasets as compared to unperturbed datasets. Furthermore, the experiments demonstrate that these embeddings does capture the semantic and syntactic structure (sentence order) of sentences. However, existing supervised classification strategies fail to leverage this information, and merely function as n-gram detectors.
C3Net: Compound Conditioned ControlNet for Multimodal Content Generation
Nov 29, 2023We present Compound Conditioned ControlNet, C3Net, a novel generative neural architecture taking conditions from multiple modalities and synthesizing multimodal contents simultaneously (e.g., image, text, audio). C3Net adapts the ControlNet architecture to jointly train and make inferences on a production-ready diffusion model and its trainable copies. Specifically, C3Net first aligns the conditions from multi-modalities to the same semantic latent space using modality-specific encoders based on contrastive training. Then, it generates multimodal outputs based on the aligned latent space, whose semantic information is combined using a ControlNet-like architecture called Control C3-UNet. Correspondingly, with this system design, our model offers an improved solution for joint-modality generation through learning and explaining multimodal conditions instead of simply taking linear interpolations on the latent space. Meanwhile, as we align conditions to a unified latent space, C3Net only requires one trainable Control C3-UNet to work on multimodal semantic information. Furthermore, our model employs unimodal pretraining on the condition alignment stage, outperforming the non-pretrained alignment even on relatively scarce training data and thus demonstrating high-quality compound condition generation. We contribute the first high-quality tri-modal validation set to validate quantitatively that C3Net outperforms or is on par with first and contemporary state-of-the-art multimodal generation. Our codes and tri-modal dataset will be released.
Action-slot: Visual Action-centric Representations for Multi-label Atomic Activity Recognition in Traffic Scenes
Nov 29, 2023In this paper, we study multi-label atomic activity recognition. Despite the notable progress in action recognition, it is still challenging to recognize atomic activities due to a deficiency in a holistic understanding of both multiple road users' motions and their contextual information. In this paper, we introduce Action-slot, a slot attention-based approach that learns visual action-centric representations, capturing both motion and contextual information. Our key idea is to design action slots that are capable of paying attention to regions where atomic activities occur, without the need for explicit perception guidance. To further enhance slot attention, we introduce a background slot that competes with action slots, aiding the training process in avoiding unnecessary focus on background regions devoid of activities. Yet, the imbalanced class distribution in the existing dataset hampers the assessment of rare activities. To address the limitation, we collect a synthetic dataset called TACO, which is four times larger than OATS and features a balanced distribution of atomic activities. To validate the effectiveness of our method, we conduct comprehensive experiments and ablation studies against various action recognition baselines. We also show that the performance of multi-label atomic activity recognition on real-world datasets can be improved by pretraining representations on TACO. We will release our source code and dataset. See the videos of visualization on the project page: https://hcis-lab.github.io/Action-slot/
eMotions: A Large-Scale Dataset for Emotion Recognition in Short Videos
Nov 29, 2023Nowadays, short videos (SVs) are essential to information acquisition and sharing in our life. The prevailing use of SVs to spread emotions leads to the necessity of emotion recognition in SVs. Considering the lack of SVs emotion data, we introduce a large-scale dataset named eMotions, comprising 27,996 videos. Meanwhile, we alleviate the impact of subjectivities on labeling quality by emphasizing better personnel allocations and multi-stage annotations. In addition, we provide the category-balanced and test-oriented variants through targeted data sampling. Some commonly used videos (e.g., facial expressions and postures) have been well studied. However, it is still challenging to understand the emotions in SVs. Since the enhanced content diversity brings more distinct semantic gaps and difficulties in learning emotion-related features, and there exists information gaps caused by the emotion incompleteness under the prevalently audio-visual co-expressions. To tackle these problems, we present an end-to-end baseline method AV-CPNet that employs the video transformer to better learn semantically relevant representations. We further design the two-stage cross-modal fusion module to complementarily model the correlations of audio-visual features. The EP-CE Loss, incorporating three emotion polarities, is then applied to guide model optimization. Extensive experimental results on nine datasets verify the effectiveness of AV-CPNet. Datasets and code will be open on https://github.com/XuecWu/eMotions.
SigFormer: Sparse Signal-Guided Transformer for Multi-Modal Human Action Segmentation
Nov 29, 2023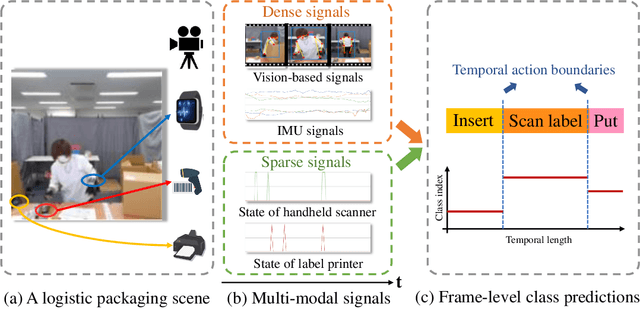
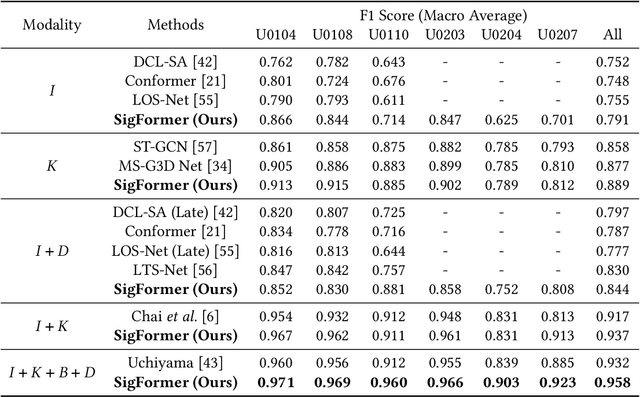
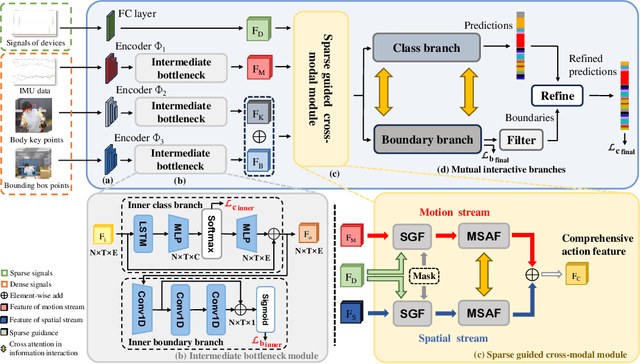
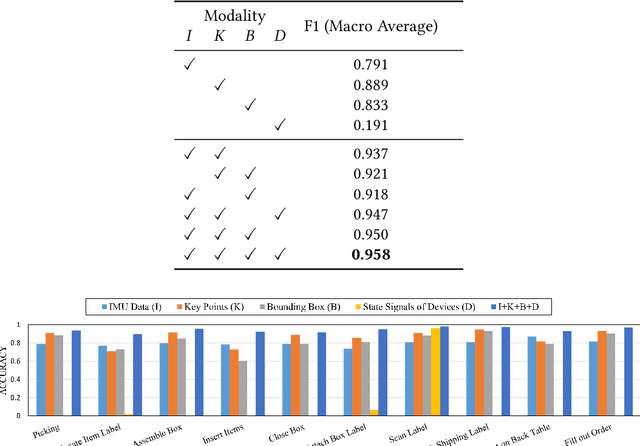
Multi-modal human action segmentation is a critical and challenging task with a wide range of applications. Nowadays, the majority of approaches concentrate on the fusion of dense signals (i.e., RGB, optical flow, and depth maps). However, the potential contributions of sparse IoT sensor signals, which can be crucial for achieving accurate recognition, have not been fully explored. To make up for this, we introduce a Sparse signalguided Transformer (SigFormer) to combine both dense and sparse signals. We employ mask attention to fuse localized features by constraining cross-attention within the regions where sparse signals are valid. However, since sparse signals are discrete, they lack sufficient information about the temporal action boundaries. Therefore, in SigFormer, we propose to emphasize the boundary information at two stages to alleviate this problem. In the first feature extraction stage, we introduce an intermediate bottleneck module to jointly learn both category and boundary features of each dense modality through the inner loss functions. After the fusion of dense modalities and sparse signals, we then devise a two-branch architecture that explicitly models the interrelationship between action category and temporal boundary. Experimental results demonstrate that SigFormer outperforms the state-of-the-art approaches on a multi-modal action segmentation dataset from real industrial environments, reaching an outstanding F1 score of 0.958. The codes and pre-trained models have been available at https://github.com/LIUQI-creat/SigFormer.