 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Large Language Models on Graphs: A Comprehensive Survey
Dec 05, 2023
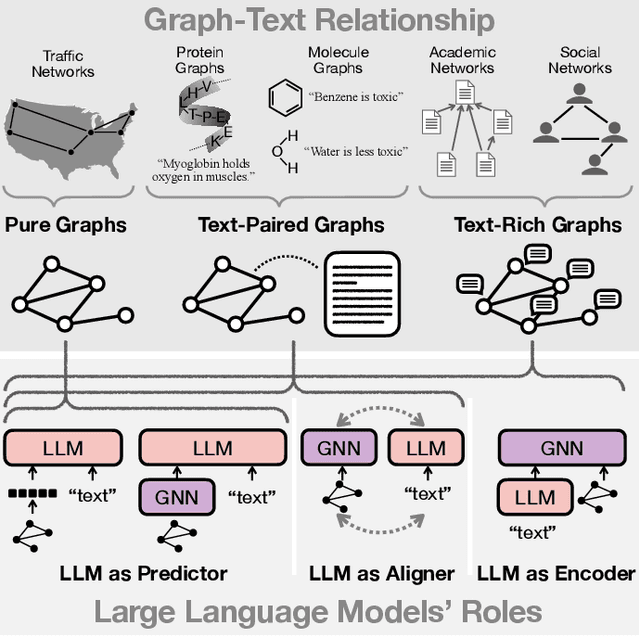
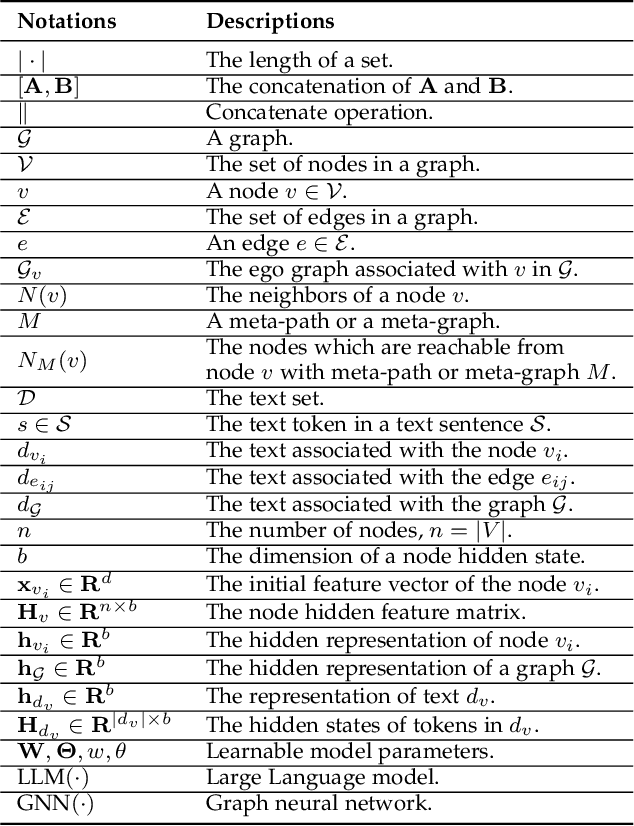
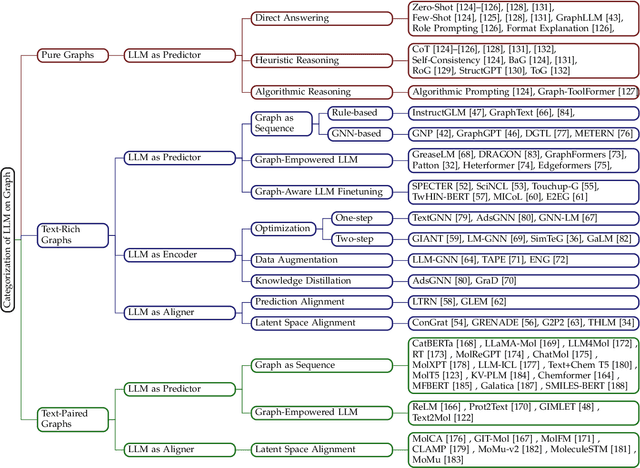
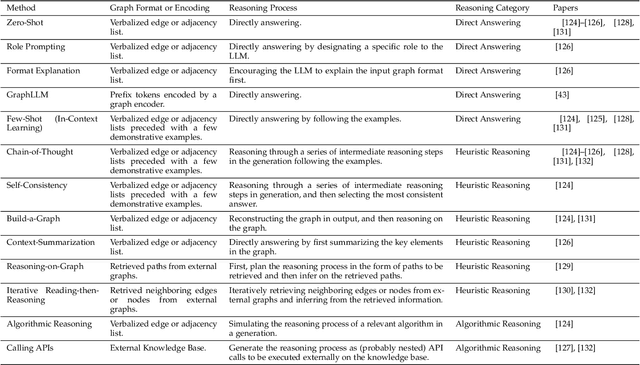
Large language models (LLMs), such as ChatGPT and LLaMA, are creating significant advancements in natural language processing, due to their strong text encoding/decoding ability and newly found emergent capability (e.g., reasoning). While LLMs are mainly designed to process pure texts, there are many real-world scenarios where text data are associated with rich structure information in the form of graphs (e.g., academic networks, and e-commerce networks) or scenarios where graph data are paired with rich textual information (e.g., molecules with descriptions). Besides, although LLMs have shown their pure text-based reasoning ability, it is underexplored whether such ability can be generalized to graph scenarios (i.e., graph-based reasoning). In this paper, we provide a systematic review of scenarios and techniques related to large language models on graphs. We first summarize potential scenarios of adopting LLMs on graphs into three categories, namely pure graphs, text-rich graphs, and text-paired graphs. We then discuss detailed techniques for utilizing LLMs on graphs, including LLM as Predictor, LLM as Encoder, and LLM as Aligner, and compare the advantages and disadvantages of different schools of models. Furthermore, we mention the real-world applications of such methods and summarize open-source codes and benchmark datasets. Finally, we conclude with potential future research directions in this fast-growing field. The related source can be found at https://github.com/PeterGriffinJin/Awesome-Language-Model-on-Graphs.
A Multi-Granularity-Aware Aspect Learning Model for Multi-Aspect Dense Retrieval
Dec 05, 2023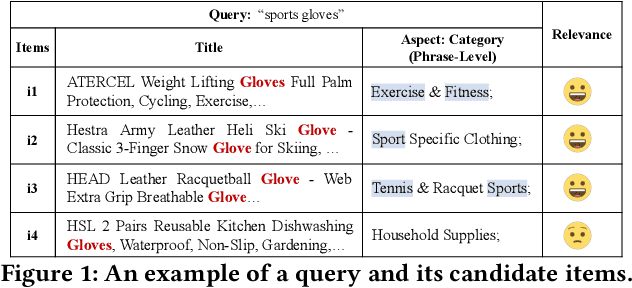

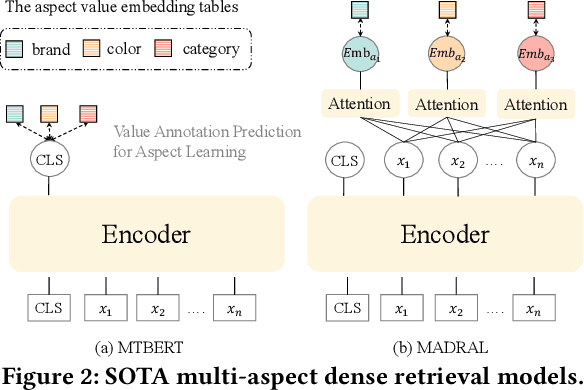

Dense retrieval methods have been mostly focused on unstructured text and less attention has been drawn to structured data with various aspects, e.g., products with aspects such as category and brand. Recent work has proposed two approaches to incorporate the aspect information into item representations for effective retrieval by predicting the values associated with the item aspects. Despite their efficacy, they treat the values as isolated classes (e.g., "Smart Homes", "Home, Garden & Tools", and "Beauty & Health") and ignore their fine-grained semantic relation. Furthermore, they either enforce the learning of aspects into the CLS token, which could confuse it from its designated use for representing the entire content semantics, or learn extra aspect embeddings only with the value prediction objective, which could be insufficient especially when there are no annotated values for an item aspect. Aware of these limitations, we propose a MUlti-granulaRity-aware Aspect Learning model (MURAL) for multi-aspect dense retrieval. It leverages aspect information across various granularities to capture both coarse and fine-grained semantic relations between values. Moreover, MURAL incorporates separate aspect embeddings as input to transformer encoders so that the masked language model objective can assist implicit aspect learning even without aspect-value annotations. Extensive experiments on two real-world datasets of products and mini-programs show that MURAL outperforms state-of-the-art baselines significantly.
Stable Messenger: Steganography for Message-Concealed Image Generation
Dec 03, 2023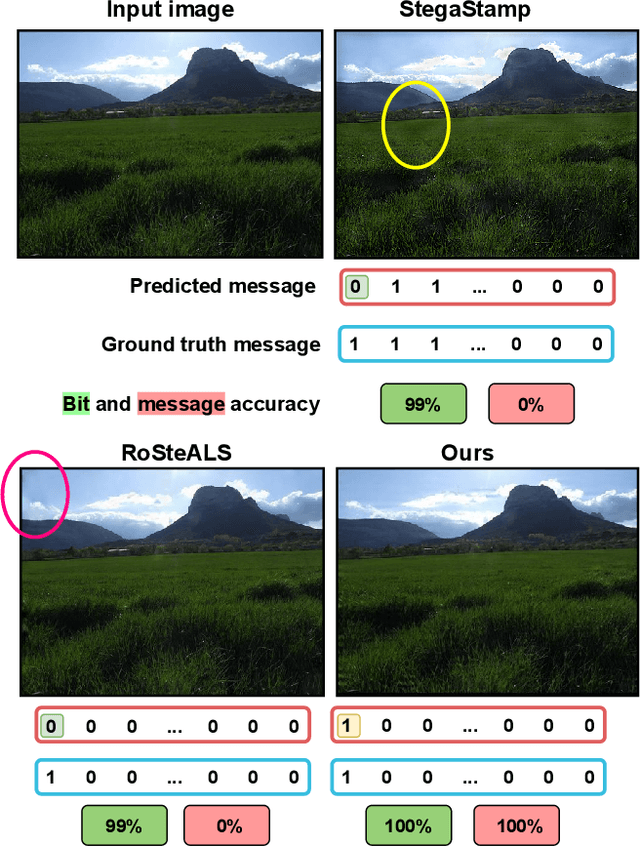
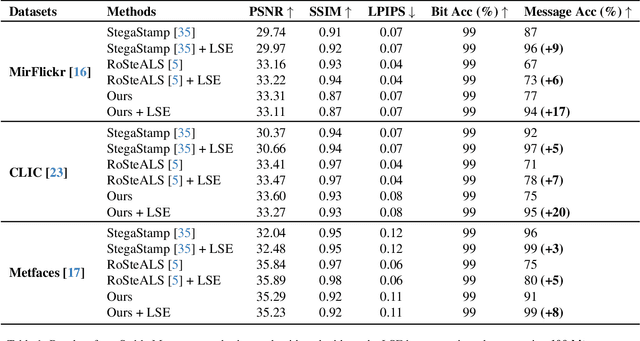
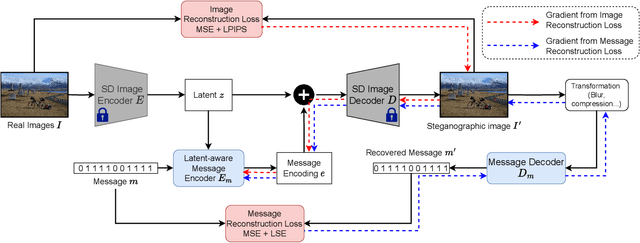

In the ever-expanding digital landscape, safeguarding sensitive information remains paramount. This paper delves deep into digital protection, specifically focusing on steganography. While prior research predominantly fixated on individual bit decoding, we address this limitation by introducing ``message accuracy'', a novel metric evaluating the entirety of decoded messages for a more holistic evaluation. In addition, we propose an adaptive universal loss tailored to enhance message accuracy, named Log-Sum-Exponential (LSE) loss, thereby significantly improving the message accuracy of recent approaches. Furthermore, we also introduce a new latent-aware encoding technique in our framework named \Approach, harnessing pretrained Stable Diffusion for advanced steganographic image generation, giving rise to a better trade-off between image quality and message recovery. Throughout experimental results, we have demonstrated the superior performance of the new LSE loss and latent-aware encoding technique. This comprehensive approach marks a significant step in evolving evaluation metrics, refining loss functions, and innovating image concealment techniques, aiming for more robust and dependable information protection.
Prompting Disentangled Embeddings for Knowledge Graph Completion with Pre-trained Language Model
Dec 04, 2023Both graph structures and textual information play a critical role in Knowledge Graph Completion (KGC). With the success of Pre-trained Language Models (PLMs) such as BERT, they have been applied for text encoding for KGC. However, the current methods mostly prefer to fine-tune PLMs, leading to huge training costs and limited scalability to larger PLMs. In contrast, we propose to utilize prompts and perform KGC on a frozen PLM with only the prompts trained. Accordingly, we propose a new KGC method named PDKGC with two prompts -- a hard task prompt which is to adapt the KGC task to the PLM pre-training task of token prediction, and a disentangled structure prompt which learns disentangled graph representation so as to enable the PLM to combine more relevant structure knowledge with the text information. With the two prompts, PDKGC builds a textual predictor and a structural predictor, respectively, and their combination leads to more comprehensive entity prediction. Solid evaluation on two widely used KGC datasets has shown that PDKGC often outperforms the baselines including the state-of-the-art, and its components are all effective. Our codes and data are available at https://github.com/genggengcss/PDKGC.
A Comprehensive Survey on Multi-modal Conversational Emotion Recognition with Deep Learning
Dec 10, 2023Multi-modal conversation emotion recognition (MCER) aims to recognize and track the speaker's emotional state using text, speech, and visual information in the conversation scene. Analyzing and studying MCER issues is significant to affective computing, intelligent recommendations, and human-computer interaction fields. Unlike the traditional single-utterance multi-modal emotion recognition or single-modal conversation emotion recognition, MCER is a more challenging problem that needs to deal with more complex emotional interaction relationships. The critical issue is learning consistency and complementary semantics for multi-modal feature fusion based on emotional interaction relationships. To solve this problem, people have conducted extensive research on MCER based on deep learning technology, but there is still a lack of systematic review of the modeling methods. Therefore, a timely and comprehensive overview of MCER's recent advances in deep learning is of great significance to academia and industry. In this survey, we provide a comprehensive overview of MCER modeling methods and roughly divide MCER methods into four categories, i.e., context-free modeling, sequential context modeling, speaker-differentiated modeling, and speaker-relationship modeling. In addition, we further discuss MCER's publicly available popular datasets, multi-modal feature extraction methods, application areas, existing challenges, and future development directions. We hope that our review can help MCER researchers understand the current research status in emotion recognition, provide some inspiration, and develop more efficient models.
Consistency Prototype Module and Motion Compensation for Few-Shot Action Recognition (CLIP-CP$\mathbf{M^2}$C)
Dec 02, 2023Recently, few-shot action recognition has significantly progressed by learning the feature discriminability and designing suitable comparison methods. Still, there are the following restrictions. (a) Previous works are mainly based on visual mono-modal. Although some multi-modal works use labels as supplementary to construct prototypes of support videos, they can not use this information for query videos. The labels are not used efficiently. (b) Most of the works ignore the motion feature of video, although the motion features are essential for distinguishing. We proposed a Consistency Prototype and Motion Compensation Network(CLIP-CP$M^2$C) to address these issues. Firstly, we use the CLIP for multi-modal few-shot action recognition with the text-image comparison for domain adaption. Secondly, in order to make the amount of information between the prototype and the query more similar, we propose a novel method to compensate for the text(prompt) information of query videos when text(prompt) does not exist, which depends on a Consistency Loss. Thirdly, we use the differential features of the adjacent frames in two directions as the motion features, which explicitly embeds the network with motion dynamics. We also apply the Consistency Loss to the motion features. Extensive experiments on standard benchmark datasets demonstrate that the proposed method can compete with state-of-the-art results. Our code is available at the URL: https://github.com/xxx/xxx.git.
Learning county from pixels: Corn yield prediction with attention-weighted multiple instance learning
Dec 02, 2023Remote sensing technology has become a promising tool in yield prediction. Most prior work employs satellite imagery for county-level corn yield prediction by spatially aggregating all pixels within a county into a single value, potentially overlooking the detailed information and valuable insights offered by more granular data. To this end, this research examines each county at the pixel level and applies multiple instance learning to leverage detailed information within a county. In addition, our method addresses the "mixed pixel" issue caused by the inconsistent resolution between feature datasets and crop mask, which may introduce noise into the model and therefore hinder accurate yield prediction. Specifically, the attention mechanism is employed to automatically assign weights to different pixels, which can mitigate the influence of mixed pixels. The experimental results show that the developed model outperforms four other machine learning models over the past five years in the U.S. corn belt and demonstrates its best performance in 2022, achieving a coefficient of determination (R2) value of 0.84 and a root mean square error (RMSE) of 0.83. This paper demonstrates the advantages of our approach from both spatial and temporal perspectives. Furthermore, through an in-depth study of the relationship between mixed pixels and attention, it is verified that our approach can capture critical feature information while filtering out noise from mixed pixels.
Boosting Prompt-Based Self-Training With Mapping-Free Automatic Verbalizer for Multi-Class Classification
Dec 08, 2023Recently, prompt-based fine-tuning has garnered considerable interest as a core technique for few-shot text classification task. This approach reformulates the fine-tuning objective to align with the Masked Language Modeling (MLM) objective. Leveraging unlabeled data, prompt-based self-training has shown greater effectiveness in binary and three-class classification. However, prompt-based self-training for multi-class classification has not been adequately investigated, despite its significant applicability to real-world scenarios. Moreover, extending current methods to multi-class classification suffers from the verbalizer that extracts the predicted value of manually pre-defined single label word for each class from MLM predictions. Consequently, we introduce a novel, efficient verbalizer structure, named Mapping-free Automatic Verbalizer (MAV). Comprising two fully connected layers, MAV serves as a trainable verbalizer that automatically extracts the requisite word features for classification by capitalizing on all available information from MLM predictions. Experimental results on five multi-class classification datasets indicate MAV's superior self-training efficacy.
Pruning Convolutional Filters via Reinforcement Learning with Entropy Minimization
Dec 08, 2023Structural pruning has become an integral part of neural network optimization, used to achieve architectural configurations which can be deployed and run more efficiently on embedded devices. Previous results showed that pruning is possible with minimum performance loss by utilizing a reinforcement learning agent which makes decisions about the sparsity level of each neural layer by maximizing as a reward the accuracy of the network. We introduce a novel information-theoretic reward function which minimizes the spatial entropy of convolutional activations. This minimization ultimately acts as a proxy for maintaining accuracy, although these two criteria are not related in any way. Our method shows that there is another possibility to preserve accuracy without the need to directly optimize it in the agent's reward function. In our experiments, we were able to reduce the total number of FLOPS of multiple popular neural network architectures by 5-10x, incurring minimal or no performance drop and being on par with the solution found by maximizing the accuracy.
Sparse Beats Dense: Rethinking Supervision in Radar-Camera Depth Completion
Dec 08, 2023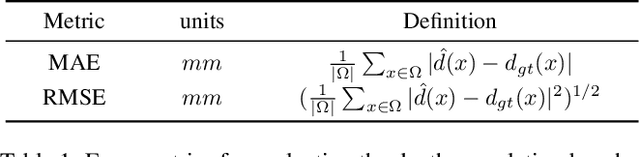

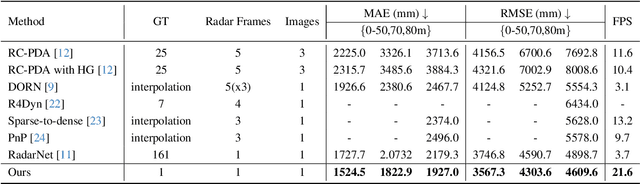
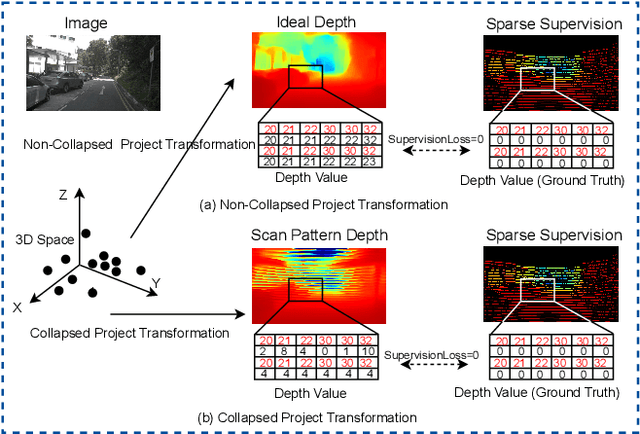
It is widely believed that the dense supervision is better than the sparse supervision in the field of depth completion, but the underlying reasons for this are rarely discussed. In this paper, we find that the challenge of using sparse supervision for training Radar-Camera depth prediction models is the Projection Transformation Collapse (PTC). The PTC implies that sparse supervision leads the model to learn unexpected collapsed projection transformations between Image/Radar/LiDAR spaces. Building on this insight, we propose a novel ``Disruption-Compensation" framework to handle the PTC, thereby relighting the use of sparse supervision in depth completion tasks. The disruption part deliberately discards position correspondences among Image/Radar/LiDAR, while the compensation part leverages 3D spatial and 2D semantic information to compensate for the discarded beneficial position correspondence. Extensive experimental results demonstrate that our framework (sparse supervision) outperforms the state-of-the-art (dense supervision) with 11.6$\%$ improvement in mean absolute error and $1.6 \times$ speedup. The code is available at ...