 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Kirchhoff Meets Johnson: In Pursuit of Unconditionally Secure Communication
Dec 04, 2023
Noise: an enemy to be dealt with and a major factor limiting communication system performance. However, what if there is gold in that garbage? In conventional engineering, our focus is primarily on eliminating, suppressing, combating, or even ignoring noise and its detrimental impacts. Conversely, could we exploit it similarly to biology, which utilizes noise-alike carrier signals to convey information? In this context, the utilization of noise, or noise-alike signals in general, has been put forward as a means to realize unconditionally secure communication systems in the future. In this tutorial article, we begin by tracing the origins of thermal noise-based communication and highlighting one of its significant applications for ensuring unconditionally secure networks: the Kirchhoff-law-Johnson-noise (KLJN) secure key exchange scheme. We then delve into the inherent challenges tied to secure communication and discuss the imperative need for physics-based key distribution schemes in pursuit of unconditional security. Concurrently, we provide a concise overview of quantum key distribution (QKD) schemes and draw comparisons with their KLJN-based counterparts. Finally, extending beyond wired communication loops, we explore the transmission of noise signals over-the-air and evaluate their potential for stealth and secure wireless communication systems.
SRTransGAN: Image Super-Resolution using Transformer based Generative Adversarial Network
Dec 04, 2023Image super-resolution aims to synthesize high-resolution image from a low-resolution image. It is an active area to overcome the resolution limitations in several applications like low-resolution object-recognition, medical image enhancement, etc. The generative adversarial network (GAN) based methods have been the state-of-the-art for image super-resolution by utilizing the convolutional neural networks (CNNs) based generator and discriminator networks. However, the CNNs are not able to exploit the global information very effectively in contrast to the transformers, which are the recent breakthrough in deep learning by exploiting the self-attention mechanism. Motivated from the success of transformers in language and vision applications, we propose a SRTransGAN for image super-resolution using transformer based GAN. Specifically, we propose a novel transformer-based encoder-decoder network as a generator to generate 2x images and 4x images. We design the discriminator network using vision transformer which uses the image as sequence of patches and hence useful for binary classification between synthesized and real high-resolution images. The proposed SRTransGAN outperforms the existing methods by 4.38 % on an average of PSNR and SSIM scores. We also analyze the saliency map to understand the learning ability of the proposed method.
AGD: an Auto-switchable Optimizer using Stepwise Gradient Difference for Preconditioning Matrix
Dec 04, 2023Adaptive optimizers, such as Adam, have achieved remarkable success in deep learning. A key component of these optimizers is the so-called preconditioning matrix, providing enhanced gradient information and regulating the step size of each gradient direction. In this paper, we propose a novel approach to designing the preconditioning matrix by utilizing the gradient difference between two successive steps as the diagonal elements. These diagonal elements are closely related to the Hessian and can be perceived as an approximation of the inner product between the Hessian row vectors and difference of the adjacent parameter vectors. Additionally, we introduce an auto-switching function that enables the preconditioning matrix to switch dynamically between Stochastic Gradient Descent (SGD) and the adaptive optimizer. Based on these two techniques, we develop a new optimizer named AGD that enhances the generalization performance. We evaluate AGD on public datasets of Natural Language Processing (NLP), Computer Vision (CV), and Recommendation Systems (RecSys). Our experimental results demonstrate that AGD outperforms the state-of-the-art (SOTA) optimizers, achieving highly competitive or significantly better predictive performance. Furthermore, we analyze how AGD is able to switch automatically between SGD and the adaptive optimizer and its actual effects on various scenarios. The code is available at https://github.com/intelligent-machine-learning/dlrover/tree/master/atorch/atorch/optimizers.
Generating Action-conditioned Prompts for Open-vocabulary Video Action Recognition
Dec 04, 2023Exploring open-vocabulary video action recognition is a promising venture, which aims to recognize previously unseen actions within any arbitrary set of categories. Existing methods typically adapt pretrained image-text models to the video domain, capitalizing on their inherent strengths in generalization. A common thread among such methods is the augmentation of visual embeddings with temporal information to improve the recognition of seen actions. Yet, they compromise with standard less-informative action descriptions, thus faltering when confronted with novel actions. Drawing inspiration from human cognitive processes, we argue that augmenting text embeddings with human prior knowledge is pivotal for open-vocabulary video action recognition. To realize this, we innovatively blend video models with Large Language Models (LLMs) to devise Action-conditioned Prompts. Specifically, we harness the knowledge in LLMs to produce a set of descriptive sentences that contain distinctive features for identifying given actions. Building upon this foundation, we further introduce a multi-modal action knowledge alignment mechanism to align concepts in video and textual knowledge encapsulated within the prompts. Extensive experiments on various video benchmarks, including zero-shot, few-shot, and base-to-novel generalization settings, demonstrate that our method not only sets new SOTA performance but also possesses excellent interpretability.
KEEC: Embed to Control on An Equivariant Geometry
Dec 04, 2023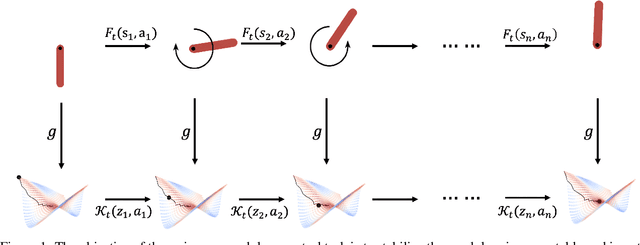
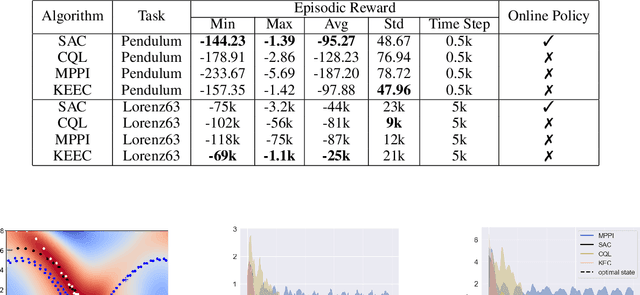
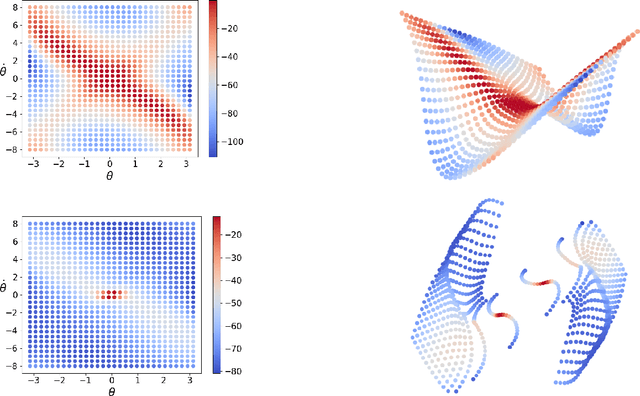
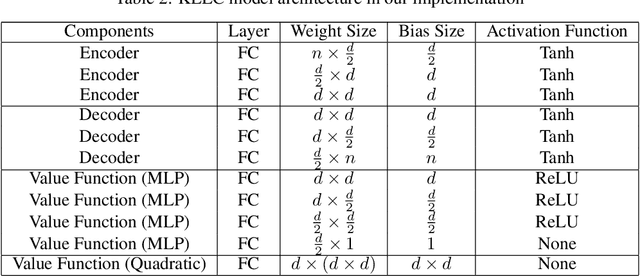
This paper investigates how representation learning can enable optimal control in unknown and complex dynamics, such as chaotic and non-linear systems, without relying on prior domain knowledge of the dynamics. The core idea is to establish an equivariant geometry that is diffeomorphic to the manifold defined by a dynamical system and to perform optimal control within this corresponding geometry, which is a non-trivial task. To address this challenge, Koopman Embed to Equivariant Control (KEEC) is introduced for model learning and control. Inspired by Lie theory, KEEC begins by learning a non-linear dynamical system defined on a manifold and embedding trajectories into a Lie group. Subsequently, KEEC formulates an equivariant value function equation in reinforcement learning on the equivariant geometry, ensuring an invariant effect as the value function on the original manifold. By deriving analytical-form optimal actions on the equivariant value function, KEEC theoretically achieves quadratic convergence for the optimal equivariant value function by leveraging the differential information on the equivariant geometry. The effectiveness of KEEC is demonstrated in challenging dynamical systems, including chaotic ones like Lorenz-63. Notably, our findings indicate that isometric and isomorphic loss functions, ensuring the compactness and smoothness of geometry, outperform loss functions without these properties.
DepthSSC: Depth-Spatial Alignment and Dynamic Voxel Resolution for Monocular 3D Semantic Scene Completion
Nov 28, 2023The task of 3D semantic scene completion with monocular cameras is gaining increasing attention in the field of autonomous driving. Its objective is to predict the occupancy status of each voxel in the 3D scene from partial image inputs. Despite the existence of numerous methods, many of them overlook the issue of accurate alignment between spatial and depth information. To address this, we propose DepthSSC, an advanced method for semantic scene completion solely based on monocular cameras. DepthSSC combines the ST-GF (Spatial Transformation Graph Fusion) module with geometric-aware voxelization, enabling dynamic adjustment of voxel resolution and considering the geometric complexity of 3D space to ensure precise alignment between spatial and depth information. This approach successfully mitigates spatial misalignment and distortion issues observed in prior methods. Through evaluation on the SemanticKITTI dataset, DepthSSC not only demonstrates its effectiveness in capturing intricate 3D structural details but also achieves state-of-the-art performance. We believe DepthSSC provides a fresh perspective on monocular camera-based 3D semantic scene completion research and anticipate it will inspire further related studies.
HandyPriors: Physically Consistent Perception of Hand-Object Interactions with Differentiable Priors
Dec 03, 2023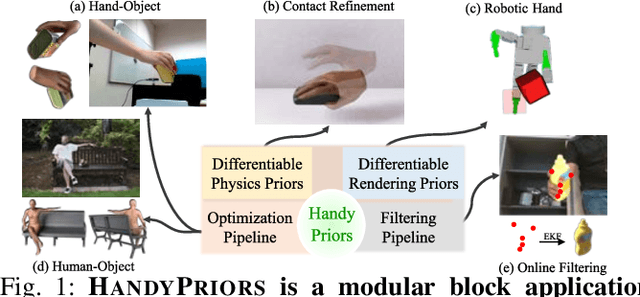
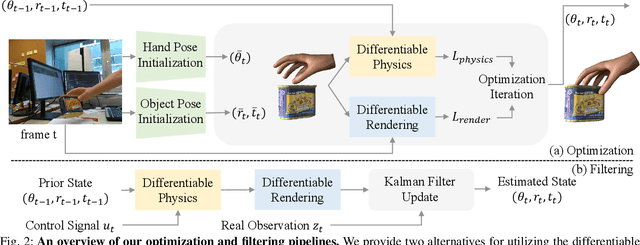
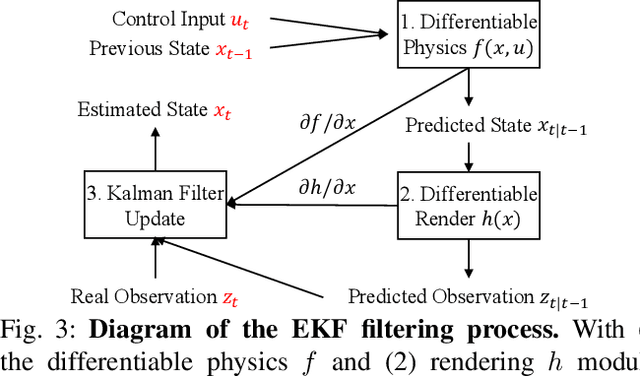

Various heuristic objectives for modeling hand-object interaction have been proposed in past work. However, due to the lack of a cohesive framework, these objectives often possess a narrow scope of applicability and are limited by their efficiency or accuracy. In this paper, we propose HandyPriors, a unified and general pipeline for pose estimation in human-object interaction scenes by leveraging recent advances in differentiable physics and rendering. Our approach employs rendering priors to align with input images and segmentation masks along with physics priors to mitigate penetration and relative-sliding across frames. Furthermore, we present two alternatives for hand and object pose estimation. The optimization-based pose estimation achieves higher accuracy, while the filtering-based tracking, which utilizes the differentiable priors as dynamics and observation models, executes faster. We demonstrate that HandyPriors attains comparable or superior results in the pose estimation task, and that the differentiable physics module can predict contact information for pose refinement. We also show that our approach generalizes to perception tasks, including robotic hand manipulation and human-object pose estimation in the wild.
Recurrent Distance-Encoding Neural Networks for Graph Representation Learning
Dec 03, 2023Graph neural networks based on iterative one-hop message passing have been shown to struggle in harnessing information from distant nodes effectively. Conversely, graph transformers allow each node to attend to all other nodes directly, but suffer from high computational complexity and have to rely on ad-hoc positional encoding to bake in the graph inductive bias. In this paper, we propose a new architecture to reconcile these challenges. Our approach stems from the recent breakthroughs in long-range modeling provided by deep state-space models on sequential data: for a given target node, our model aggregates other nodes by their shortest distances to the target and uses a parallelizable linear recurrent network over the chain of distances to provide a natural encoding of its neighborhood structure. With no need for positional encoding, we empirically show that the performance of our model is highly competitive compared with that of state-of-the-art graph transformers on various benchmarks, at a drastically reduced computational complexity. In addition, we show that our model is theoretically more expressive than one-hop message passing neural networks.
Elevating Code-mixed Text Handling through Auditory Information of Words
Oct 27, 2023With the growing popularity of code-mixed data, there is an increasing need for better handling of this type of data, which poses a number of challenges, such as dealing with spelling variations, multiple languages, different scripts, and a lack of resources. Current language models face difficulty in effectively handling code-mixed data as they primarily focus on the semantic representation of words and ignore the auditory phonetic features. This leads to difficulties in handling spelling variations in code-mixed text. In this paper, we propose an effective approach for creating language models for handling code-mixed textual data using auditory information of words from SOUNDEX. Our approach includes a pre-training step based on masked-language-modelling, which includes SOUNDEX representations (SAMLM) and a new method of providing input data to the pre-trained model. Through experimentation on various code-mixed datasets (of different languages) for sentiment, offensive and aggression classification tasks, we establish that our novel language modeling approach (SAMLM) results in improved robustness towards adversarial attacks on code-mixed classification tasks. Additionally, our SAMLM based approach also results in better classification results over the popular baselines for code-mixed tasks. We use the explainability technique, SHAP (SHapley Additive exPlanations) to explain how the auditory features incorporated through SAMLM assist the model to handle the code-mixed text effectively and increase robustness against adversarial attacks \footnote{Source code has been made available on \url{https://github.com/20118/DefenseWithPhonetics}, \url{https://www.iitp.ac.in/~ai-nlp-ml/resources.html\#Phonetics}}.
Classifying patient voice in social media data using neural networks: A comparison of AI models on different data sources and therapeutic domains
Nov 30, 2023It is essential that healthcare professionals and members of the healthcare community can access and easily understand patient experiences in the real world, so that care standards can be improved and driven towards personalised drug treatment. Social media platforms and message boards are deemed suitable sources of patient experience information, as patients have been observed to discuss and exchange knowledge, look for and provide support online. This paper tests the hypothesis that not all online patient experience information can be treated and collected in the same way, as a result of the inherent differences in the way individuals talk about their journeys, in different therapeutic domains and or data sources. We used linguistic analysis to understand and identify similarities between datasets, across patient language, between data sources (Reddit, SocialGist) and therapeutic domains (cardiovascular, oncology, immunology, neurology). We detected common vocabulary used by patients in the same therapeutic domain across data sources, except for immunology patients, who use unique vocabulary between the two data sources, and compared to all other datasets. We combined linguistically similar datasets to train classifiers (CNN, transformer) to accurately identify patient experience posts from social media, a task we refer to as patient voice classification. The cardiovascular and neurology transformer classifiers perform the best in their respective comparisons for the Reddit data source, achieving F1-scores of 0.865 and 1.0 respectively. The overall best performing classifier is the transformer classifier trained on all data collected for this experiment, achieving F1-scores ranging between 0.863 and 0.995 across all therapeutic domain and data source specific test datasets.