 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Perceiving University Student's Opinions from Google App Reviews
Dec 10, 2023
Google app market captures the school of thought of users from every corner of the globe via ratings and text reviews, in a multilinguistic arena. The potential information from the reviews cannot be extracted manually, due to its exponential growth. So, Sentiment analysis, by machine learning and deep learning algorithms employing NLP, explicitly uncovers and interprets the emotions. This study performs the sentiment classification of the app reviews and identifies the university student's behavior towards the app market via exploratory analysis. We applied machine learning algorithms using the TP, TF, and TF IDF text representation scheme and evaluated its performance on Bagging, an ensemble learning method. We used word embedding, Glove, on the deep learning paradigms. Our model was trained on Google app reviews and tested on Student's App Reviews(SAR). The various combinations of these algorithms were compared amongst each other using F score and accuracy and inferences were highlighted graphically. SVM, amongst other classifiers, gave fruitful accuracy(93.41%), F score(89%) on bigram and TF IDF scheme. Bagging enhanced the performance of LR and NB with accuracy of 87.88% and 86.69% and F score of 86% and 78% respectively. Overall, LSTM on Glove embedding recorded the highest accuracy(95.2%) and F score(88%).
* Accepted in Concurrency and Computation Practice and Experience
A Decoupled Spatio-Temporal Framework for Skeleton-based Action Segmentation
Dec 10, 2023Effectively modeling discriminative spatio-temporal information is essential for segmenting activities in long action sequences. However, we observe that existing methods are limited in weak spatio-temporal modeling capability due to two forms of decoupled modeling: (i) cascaded interaction couples spatial and temporal modeling, which over-smooths motion modeling over the long sequence, and (ii) joint-shared temporal modeling adopts shared weights to model each joint, ignoring the distinct motion patterns of different joints. We propose a Decoupled Spatio-Temporal Framework (DeST) to address the above issues. Firstly, we decouple the cascaded spatio-temporal interaction to avoid stacking multiple spatio-temporal blocks, while achieving sufficient spatio-temporal interaction. Specifically, DeST performs once unified spatial modeling and divides the spatial features into different groups of subfeatures, which then adaptively interact with temporal features from different layers. Since the different sub-features contain distinct spatial semantics, the model could learn the optimal interaction pattern at each layer. Meanwhile, inspired by the fact that different joints move at different speeds, we propose joint-decoupled temporal modeling, which employs independent trainable weights to capture distinctive temporal features of each joint. On four large-scale benchmarks of different scenes, DeST significantly outperforms current state-of-the-art methods with less computational complexity.
Beyond One Model Fits All: Ensemble Deep Learning for Autonomous Vehicles
Dec 10, 2023Deep learning has revolutionized autonomous driving by enabling vehicles to perceive and interpret their surroundings with remarkable accuracy. This progress is attributed to various deep learning models, including Mediated Perception, Behavior Reflex, and Direct Perception, each offering unique advantages and challenges in enhancing autonomous driving capabilities. However, there is a gap in research addressing integrating these approaches and understanding their relevance in diverse driving scenarios. This study introduces three distinct neural network models corresponding to Mediated Perception, Behavior Reflex, and Direct Perception approaches. We explore their significance across varying driving conditions, shedding light on the strengths and limitations of each approach. Our architecture fuses information from the base, future latent vector prediction, and auxiliary task networks, using global routing commands to select appropriate action sub-networks. We aim to provide insights into effectively utilizing diverse modeling strategies in autonomous driving by conducting experiments and evaluations. The results show that the ensemble model performs better than the individual approaches, suggesting that each modality contributes uniquely toward the performance of the overall model. Moreover, by exploring the significance of each modality, this study offers a roadmap for future research in autonomous driving, emphasizing the importance of leveraging multiple models to achieve robust performance.
QMGeo: Differentially Private Federated Learning via Stochastic Quantization with Mixed Truncated Geometric Distribution
Dec 10, 2023Federated learning (FL) is a framework which allows multiple users to jointly train a global machine learning (ML) model by transmitting only model updates under the coordination of a parameter server, while being able to keep their datasets local. One key motivation of such distributed frameworks is to provide privacy guarantees to the users. However, preserving the users' datasets locally is shown to be not sufficient for privacy. Several differential privacy (DP) mechanisms have been proposed to provide provable privacy guarantees by introducing randomness into the framework, and majority of these mechanisms rely on injecting additive noise. FL frameworks also face the challenge of communication efficiency, especially as machine learning models grow in complexity and size. Quantization is a commonly utilized method, reducing the communication cost by transmitting compressed representation of the underlying information. Although there have been several studies on DP and quantization in FL, the potential contribution of the quantization method alone in providing privacy guarantees has not been extensively analyzed yet. We in this paper present a novel stochastic quantization method, utilizing a mixed geometric distribution to introduce the randomness needed to provide DP, without any additive noise. We provide convergence analysis for our framework and empirically study its performance.
Constructing Vec-tionaries to Extract Latent Message Features from Texts: A Case Study of Moral Appeals
Dec 10, 2023While communication research frequently studies latent message features like moral appeals, their quantification remains a challenge. Conventional human coding struggles with scalability and intercoder reliability. While dictionary-based methods are cost-effective and computationally efficient, they often lack contextual sensitivity and are limited by the vocabularies developed for the original applications. In this paper, we present a novel approach to construct vec-tionary measurement tools that boost validated dictionaries with word embeddings through nonlinear optimization. By harnessing semantic relationships encoded by embeddings, vec-tionaries improve the measurement of latent message features by expanding the applicability of original vocabularies to other contexts. Vec-tionaries can also help extract semantic information from texts, especially those in short format, beyond the original vocabulary of a dictionary. Importantly, a vec-tionary can produce additional metrics to capture the valence and ambivalence of a latent feature beyond its strength in texts. Using moral appeals in COVID-19-related tweets as a case study, we illustrate the steps to construct the moral foundations vec-tionary, showcasing its ability to process posts missed by dictionary methods and to produce measurements better aligned with crowdsourced human assessments. Furthermore, additional metrics from the moral foundations vec-tionary unveiled unique insights that facilitated predicting outcomes such as message retransmission.
Keyword-optimized Template Insertion for Clinical Information Extraction via Prompt-based Learning
Oct 31, 2023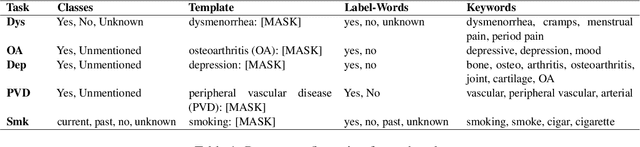
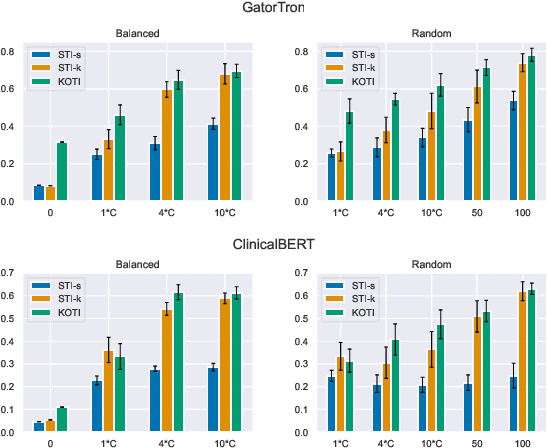
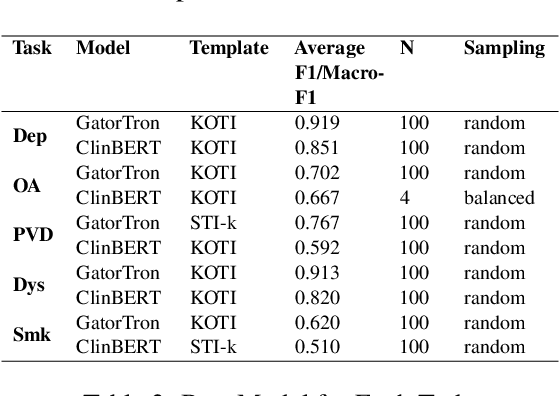

Clinical note classification is a common clinical NLP task. However, annotated data-sets are scarse. Prompt-based learning has recently emerged as an effective method to adapt pre-trained models for text classification using only few training examples. A critical component of prompt design is the definition of the template (i.e. prompt text). The effect of template position, however, has been insufficiently investigated. This seems particularly important in the clinical setting, where task-relevant information is usually sparse in clinical notes. In this study we develop a keyword-optimized template insertion method (KOTI) and show how optimizing position can improve performance on several clinical tasks in a zero-shot and few-shot training setting.
Understanding and Improving In-Context Learning on Vision-language Models
Nov 29, 2023Recently, in-context learning (ICL) on large language models (LLMs) has received great attention, and this technique can also be applied to vision-language models (VLMs) built upon LLMs. These VLMs can respond to queries by conditioning responses on a series of multimodal demonstrations, which comprise images, queries, and answers. Though ICL has been extensively studied on LLMs, its research on VLMs remains limited. The inclusion of additional visual information in the demonstrations motivates the following research questions: which of the two modalities in the demonstration is more significant? How can we select effective multimodal demonstrations to enhance ICL performance? This study investigates the significance of both visual and language information. Our findings indicate that ICL in VLMs is predominantly driven by the textual information in the demonstrations whereas the visual information in the demonstrations barely affects the ICL performance. Subsequently, we provide an understanding of the findings by analyzing the model information flow and comparing model inner states given different ICL settings. Motivated by our analysis, we propose a simple yet effective approach, termed Mixed Modality In-Context Example Selection (MMICES), which considers both visual and language modalities when selecting demonstrations and shows better ICL performance. Extensive experiments are conducted to support our findings, understanding, and improvement of the ICL performance of VLMs.
Beneath the Surface: Unveiling Harmful Memes with Multimodal Reasoning Distilled from Large Language Models
Dec 09, 2023The age of social media is rife with memes. Understanding and detecting harmful memes pose a significant challenge due to their implicit meaning that is not explicitly conveyed through the surface text and image. However, existing harmful meme detection approaches only recognize superficial harm-indicative signals in an end-to-end classification manner but ignore in-depth cognition of the meme text and image. In this paper, we attempt to detect harmful memes based on advanced reasoning over the interplay of multimodal information in memes. Inspired by the success of Large Language Models (LLMs) on complex reasoning, we first conduct abductive reasoning with LLMs. Then we propose a novel generative framework to learn reasonable thoughts from LLMs for better multimodal fusion and lightweight fine-tuning, which consists of two training stages: 1) Distill multimodal reasoning knowledge from LLMs; and 2) Fine-tune the generative framework to infer harmfulness. Extensive experiments conducted on three meme datasets demonstrate that our proposed approach achieves superior performance than state-of-the-art methods on the harmful meme detection task.
* The first work to alleviate the issue of superficial understanding for harmful meme detection by explicitly utilizing commonsense knowledge, from a fresh perspective on harnessing advanced Large Language Models
FT2TF: First-Person Statement Text-To-Talking Face Generation
Dec 09, 2023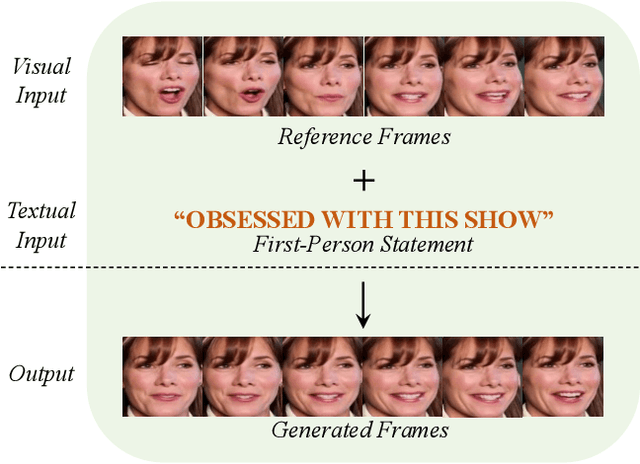
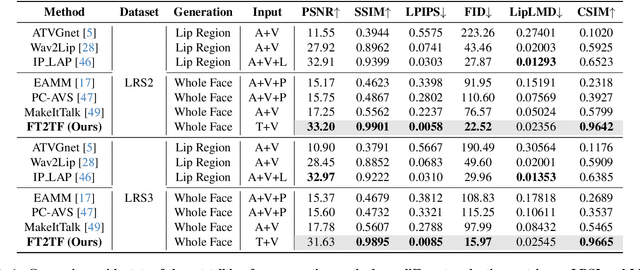
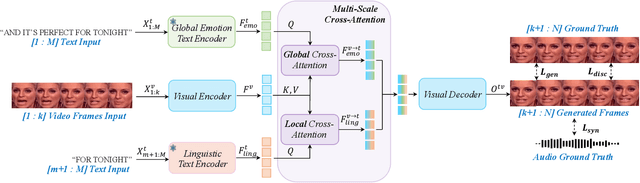
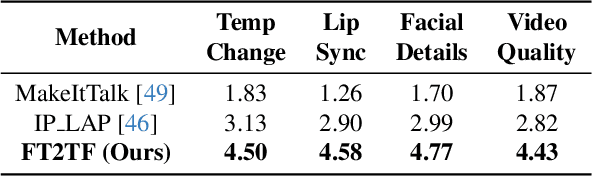
Talking face generation has gained immense popularity in the computer vision community, with various applications including AR/VR, teleconferencing, digital assistants, and avatars. Traditional methods are mainly audio-driven ones which have to deal with the inevitable resource-intensive nature of audio storage and processing. To address such a challenge, we propose FT2TF - First-Person Statement Text-To-Talking Face Generation, a novel one-stage end-to-end pipeline for talking face generation driven by first-person statement text. Moreover, FT2TF implements accurate manipulation of the facial expressions by altering the corresponding input text. Different from previous work, our model only leverages visual and textual information without any other sources (e.g. audio/landmark/pose) during inference. Extensive experiments are conducted on LRS2 and LRS3 datasets, and results on multi-dimensional evaluation metrics are reported. Both quantitative and qualitative results showcase that FT2TF outperforms existing relevant methods and reaches the state-of-the-art. This achievement highlights our model capability to bridge first-person statements and dynamic face generation, providing insightful guidance for future work.
Teaching Specific Scientific Knowledge into Large Language Models through Additional Training
Dec 06, 2023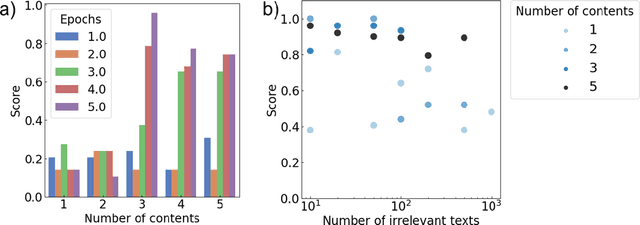
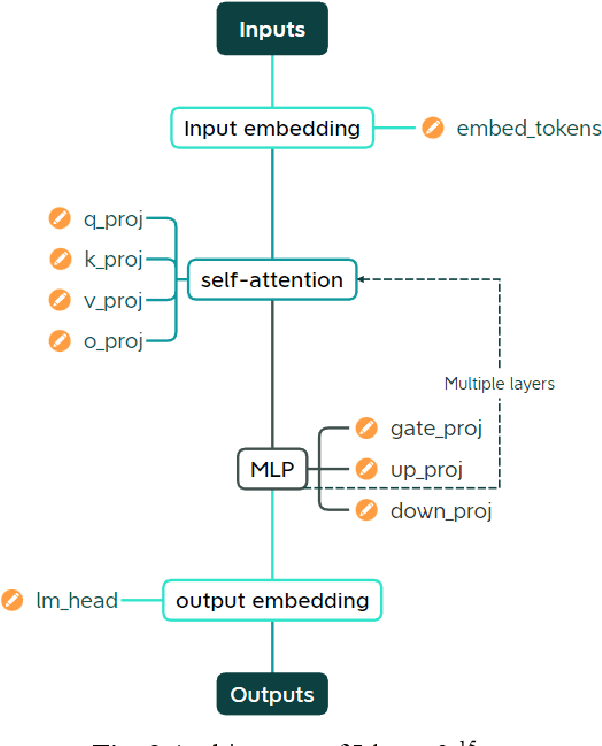
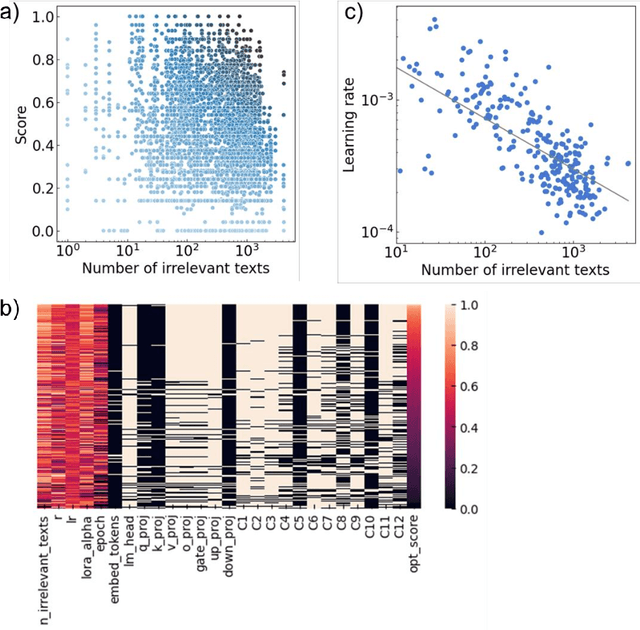
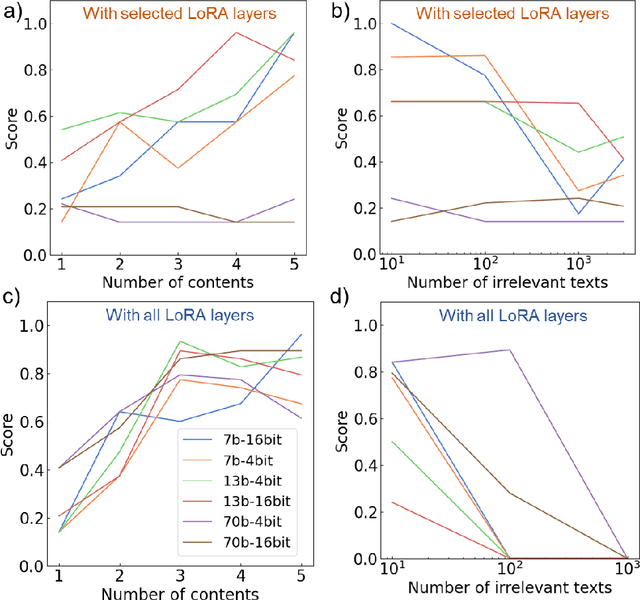
Through additional training, we explore embedding specialized scientific knowledge into the Llama 2 Large Language Model (LLM). Key findings reveal that effective knowledge integration requires reading texts from multiple perspectives, especially in instructional formats. We utilize text augmentation to tackle the scarcity of specialized texts, including style conversions and translations. Hyperparameter optimization proves crucial, with different size models (7b, 13b, and 70b) reasonably undergoing additional training. Validating our methods, we construct a dataset of 65,000 scientific papers. Although we have succeeded in partially embedding knowledge, the study highlights the complexities and limitations of incorporating specialized information into LLMs, suggesting areas for further improvement.