 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Rate Variable-Length CSI Compression for FDD Massive MIMO
Nov 30, 2023
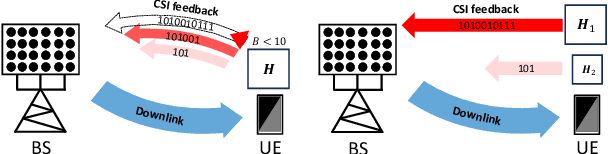
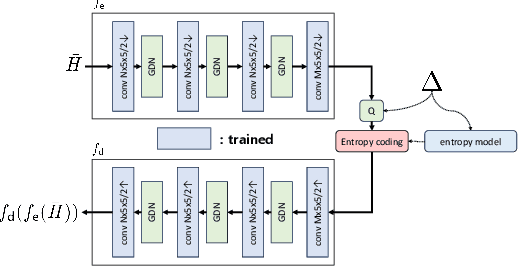
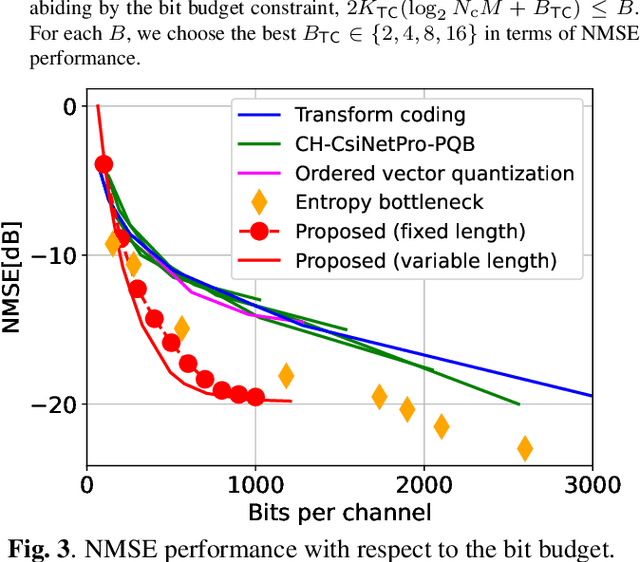
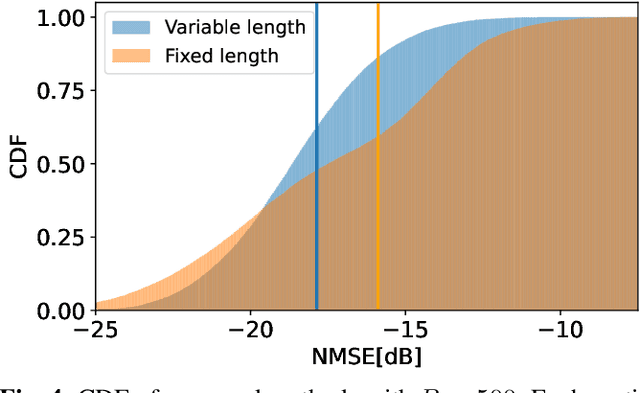
For frequency-division-duplexing (FDD) systems, channel state information (CSI) should be fed back from the user terminal to the base station. This feedback overhead becomes problematic as the number of antennas grows. To alleviate this issue, we propose a flexible CSI compression method using variational autoencoder (VAE) with an entropy bottleneck structure, which can support multi-rate and variable-length operation. Numerical study confirms that the proposed method outperforms the existing CSI compression techniques in terms of normalized mean squared error.
Generalized Large-Scale Data Condensation via Various Backbone and Statistical Matching
Nov 29, 2023The lightweight "local-match-global" matching introduced by SRe2L successfully creates a distilled dataset with comprehensive information on the full 224x224 ImageNet-1k. However, this one-sided approach is limited to a particular backbone, layer, and statistics, which limits the improvement of the generalization of a distilled dataset. We suggest that sufficient and various "local-match-global" matching are more precise and effective than a single one and has the ability to create a distilled dataset with richer information and better generalization. We call this perspective "generalized matching" and propose Generalized Various Backbone and Statistical Matching (G-VBSM) in this work, which aims to create a synthetic dataset with densities, ensuring consistency with the complete dataset across various backbones, layers, and statistics. As experimentally demonstrated, G-VBSM is the first algorithm to obtain strong performance across both small-scale and large-scale datasets. Specifically, G-VBSM achieves a performance of 38.7% on CIFAR-100 with 128-width ConvNet, 47.6% on Tiny-ImageNet with ResNet18, and 31.4% on the full 224x224 ImageNet-1k with ResNet18, under images per class (IPC) 10, 50, and 10, respectively. These results surpass all SOTA methods by margins of 3.9%, 6.5%, and 10.1%, respectively.
Leveraging Timestamp Information for Serialized Joint Streaming Recognition and Translation
Oct 23, 2023The growing need for instant spoken language transcription and translation is driven by increased global communication and cross-lingual interactions. This has made offering translations in multiple languages essential for user applications. Traditional approaches to automatic speech recognition (ASR) and speech translation (ST) have often relied on separate systems, leading to inefficiencies in computational resources, and increased synchronization complexity in real time. In this paper, we propose a streaming Transformer-Transducer (T-T) model able to jointly produce many-to-one and one-to-many transcription and translation using a single decoder. We introduce a novel method for joint token-level serialized output training based on timestamp information to effectively produce ASR and ST outputs in the streaming setting. Experiments on {it,es,de}->en prove the effectiveness of our approach, enabling the generation of one-to-many joint outputs with a single decoder for the first time.
A Novel Information-Theoretic Objective to Disentangle Representations for Fair Classification
Oct 21, 2023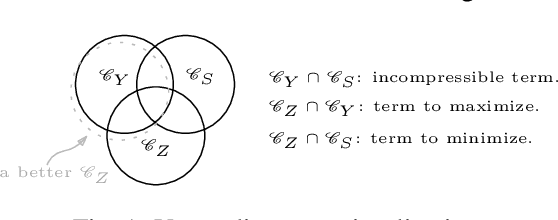
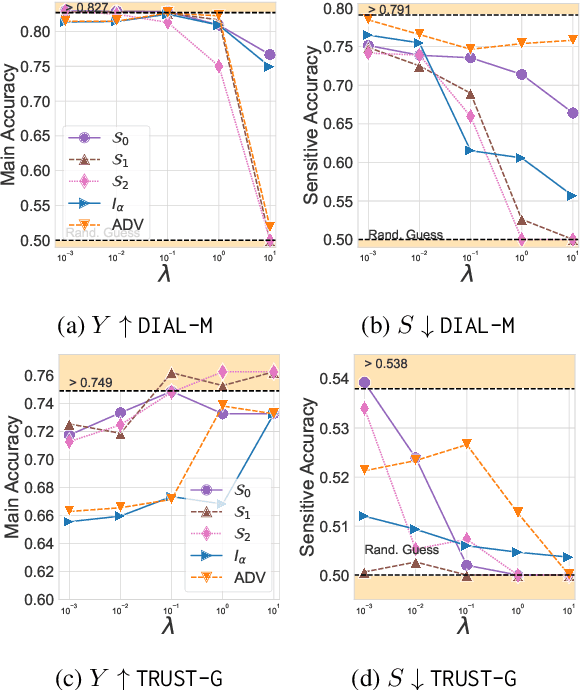
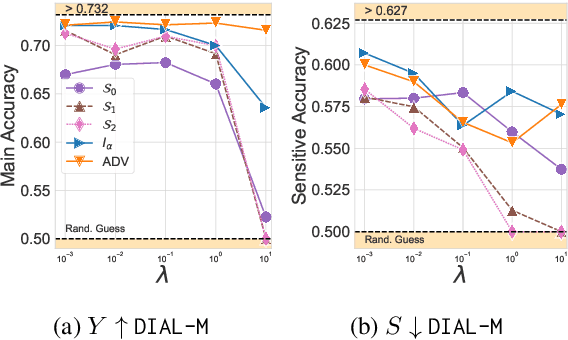
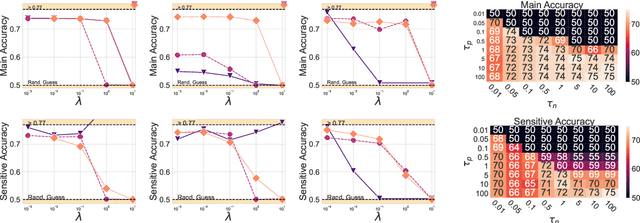
One of the pursued objectives of deep learning is to provide tools that learn abstract representations of reality from the observation of multiple contextual situations. More precisely, one wishes to extract disentangled representations which are (i) low dimensional and (ii) whose components are independent and correspond to concepts capturing the essence of the objects under consideration (Locatello et al., 2019b). One step towards this ambitious project consists in learning disentangled representations with respect to a predefined (sensitive) attribute, e.g., the gender or age of the writer. Perhaps one of the main application for such disentangled representations is fair classification. Existing methods extract the last layer of a neural network trained with a loss that is composed of a cross-entropy objective and a disentanglement regularizer. In this work, we adopt an information-theoretic view of this problem which motivates a novel family of regularizers that minimizes the mutual information between the latent representation and the sensitive attribute conditional to the target. The resulting set of losses, called CLINIC, is parameter free and thus, it is easier and faster to train. CLINIC losses are studied through extensive numerical experiments by training over 2k neural networks. We demonstrate that our methods offer a better disentanglement/accuracy trade-off than previous techniques, and generalize better than training with cross-entropy loss solely provided that the disentanglement task is not too constraining.
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
Dec 05, 2023End-to-end autonomous driving recently emerged as a promising research direction to target autonomy from a full-stack perspective. Along this line, many of the latest works follow an open-loop evaluation setting on nuScenes to study the planning behavior. In this paper, we delve deeper into the problem by conducting thorough analyses and demystifying more devils in the details. We initially observed that the nuScenes dataset, characterized by relatively simple driving scenarios, leads to an under-utilization of perception information in end-to-end models incorporating ego status, such as the ego vehicle's velocity. These models tend to rely predominantly on the ego vehicle's status for future path planning. Beyond the limitations of the dataset, we also note that current metrics do not comprehensively assess the planning quality, leading to potentially biased conclusions drawn from existing benchmarks. To address this issue, we introduce a new metric to evaluate whether the predicted trajectories adhere to the road. We further propose a simple baseline able to achieve competitive results without relying on perception annotations. Given the current limitations on the benchmark and metrics, we suggest the community reassess relevant prevailing research and be cautious whether the continued pursuit of state-of-the-art would yield convincing and universal conclusions. Code and models are available at \url{https://github.com/NVlabs/BEV-Planner}
Materials Expert-Artificial Intelligence for Materials Discovery
Dec 05, 2023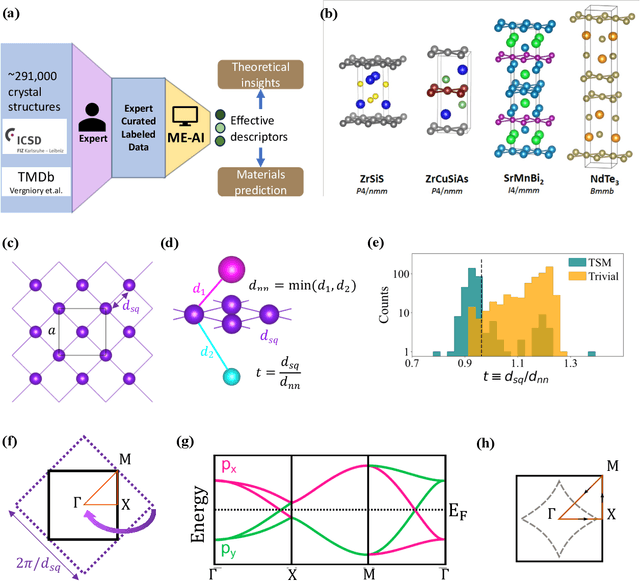

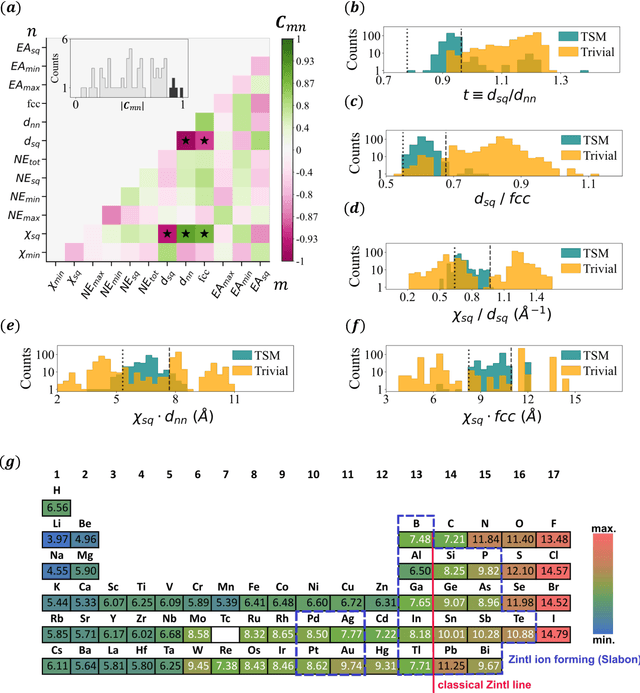
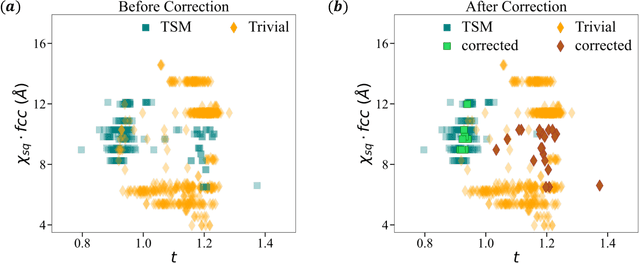
The advent of material databases provides an unprecedented opportunity to uncover predictive descriptors for emergent material properties from vast data space. However, common reliance on high-throughput ab initio data necessarily inherits limitations of such data: mismatch with experiments. On the other hand, experimental decisions are often guided by an expert's intuition honed from experiences that are rarely articulated. We propose using machine learning to "bottle" such operational intuition into quantifiable descriptors using expertly curated measurement-based data. We introduce "Materials Expert-Artificial Intelligence" (ME-AI) to encapsulate and articulate this human intuition. As a first step towards such a program, we focus on the topological semimetal (TSM) among square-net materials as the property inspired by the expert-identified descriptor based on structural information: the tolerance factor. We start by curating a dataset encompassing 12 primary features of 879 square-net materials, using experimental data whenever possible. We then use Dirichlet-based Gaussian process regression using a specialized kernel to reveal composite descriptors for square-net topological semimetals. The ME-AI learned descriptors independently reproduce expert intuition and expand upon it. Specifically, new descriptors point to hypervalency as a critical chemical feature predicting TSM within square-net compounds. Our success with a carefully defined problem points to the "machine bottling human insight" approach as promising for machine learning-aided material discovery.
T3D: Towards 3D Medical Image Understanding through Vision-Language Pre-training
Dec 05, 2023Expert annotation of 3D medical image for downstream analysis is resource-intensive, posing challenges in clinical applications. Visual self-supervised learning (vSSL), though effective for learning visual invariance, neglects the incorporation of domain knowledge from medicine. To incorporate medical knowledge into visual representation learning, vision-language pre-training (VLP) has shown promising results in 2D image. However, existing VLP approaches become generally impractical when applied to high-resolution 3D medical images due to GPU hardware constraints and the potential loss of critical details caused by downsampling, which is the intuitive solution to hardware constraints. To address the above limitations, we introduce T3D, the first VLP framework designed for high-resolution 3D medical images. T3D incorporates two text-informed pretext tasks: (\lowerromannumeral{1}) text-informed contrastive learning; (\lowerromannumeral{2}) text-informed image restoration. These tasks focus on learning 3D visual representations from high-resolution 3D medical images and integrating clinical knowledge from radiology reports, without distorting information through forced alignment of downsampled volumes with detailed anatomical text. Trained on a newly curated large-scale dataset of 3D medical images and radiology reports, T3D significantly outperforms current vSSL methods in tasks like organ and tumor segmentation, as well as disease classification. This underlines T3D's potential in representation learning for 3D medical image analysis. All data and code will be available upon acceptance.
Topology combined machine learning for consonant recognition
Nov 26, 2023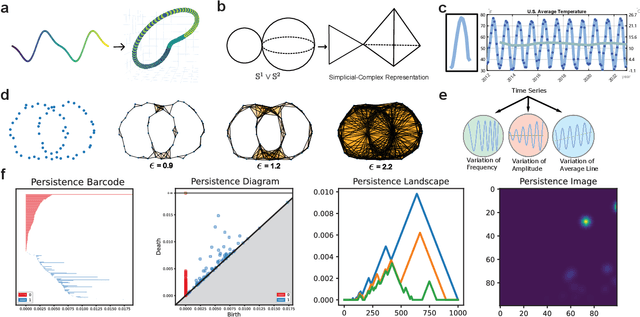
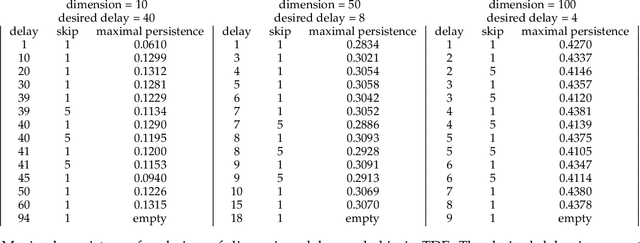
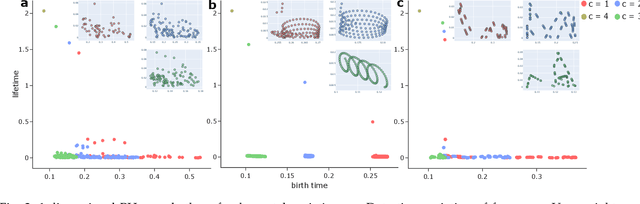
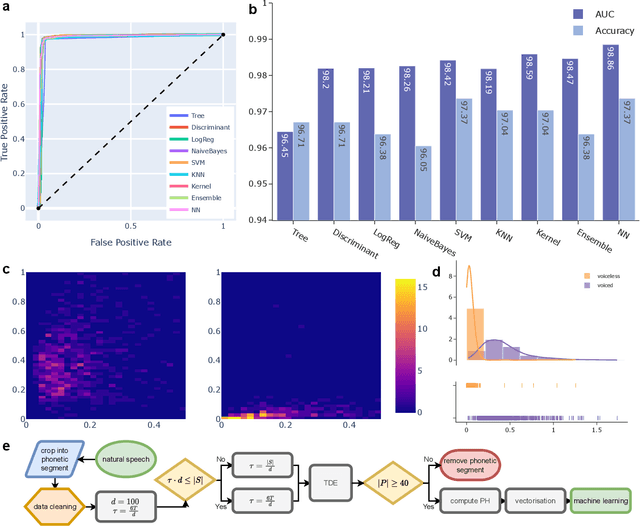
In artificial-intelligence-aided signal processing, existing deep learning models often exhibit a black-box structure, and their validity and comprehensibility remain elusive. The integration of topological methods, despite its relatively nascent application, serves a dual purpose of making models more interpretable as well as extracting structural information from time-dependent data for smarter learning. Here, we provide a transparent and broadly applicable methodology, TopCap, to capture the most salient topological features inherent in time series for machine learning. Rooted in high-dimensional ambient spaces, TopCap is capable of capturing features rarely detected in datasets with low intrinsic dimensionality. Applying time-delay embedding and persistent homology, we obtain descriptors which encapsulate information such as the vibration of a time series, in terms of its variability of frequency, amplitude, and average line, demonstrated with simulated data. This information is then vectorised and fed into multiple machine learning algorithms such as k-nearest neighbours and support vector machine. Notably, in classifying voiced and voiceless consonants, TopCap achieves an accuracy exceeding 96% and is geared towards designing topological convolutional layers for deep learning of speech and audio signals.
Generative Rendering: Controllable 4D-Guided Video Generation with 2D Diffusion Models
Dec 03, 2023Traditional 3D content creation tools empower users to bring their imagination to life by giving them direct control over a scene's geometry, appearance, motion, and camera path. Creating computer-generated videos, however, is a tedious manual process, which can be automated by emerging text-to-video diffusion models. Despite great promise, video diffusion models are difficult to control, hindering a user to apply their own creativity rather than amplifying it. To address this challenge, we present a novel approach that combines the controllability of dynamic 3D meshes with the expressivity and editability of emerging diffusion models. For this purpose, our approach takes an animated, low-fidelity rendered mesh as input and injects the ground truth correspondence information obtained from the dynamic mesh into various stages of a pre-trained text-to-image generation model to output high-quality and temporally consistent frames. We demonstrate our approach on various examples where motion can be obtained by animating rigged assets or changing the camera path.
An Information Bottleneck Characterization of the Understanding-Workload Tradeoff
Oct 11, 2023Recent advances in artificial intelligence (AI) have underscored the need for explainable AI (XAI) to support human understanding of AI systems. Consideration of human factors that impact explanation efficacy, such as mental workload and human understanding, is central to effective XAI design. Existing work in XAI has demonstrated a tradeoff between understanding and workload induced by different types of explanations. Explaining complex concepts through abstractions (hand-crafted groupings of related problem features) has been shown to effectively address and balance this workload-understanding tradeoff. In this work, we characterize the workload-understanding balance via the Information Bottleneck method: an information-theoretic approach which automatically generates abstractions that maximize informativeness and minimize complexity. In particular, we establish empirical connections between workload and complexity and between understanding and informativeness through human-subject experiments. This empirical link between human factors and information-theoretic concepts provides an important mathematical characterization of the workload-understanding tradeoff which enables user-tailored XAI design.