 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DEVIAS: Learning Disentangled Video Representations of Action and Scene for Holistic Video Understanding
Nov 30, 2023
When watching a video, humans can naturally extract human actions from the surrounding scene context, even when action-scene combinations are unusual. However, unlike humans, video action recognition models often learn scene-biased action representations from the spurious correlation in training data, leading to poor performance in out-of-context scenarios. While scene-debiased models achieve improved performance in out-of-context scenarios, they often overlook valuable scene information in the data. Addressing this challenge, we propose Disentangled VIdeo representations of Action and Scene (DEVIAS), which aims to achieve holistic video understanding. Disentangled action and scene representations with our method could provide flexibility to adjust the emphasis on action or scene information depending on downstream task and dataset characteristics. Disentangled action and scene representations could be beneficial for both in-context and out-of-context video understanding. To this end, we employ slot attention to learn disentangled action and scene representations with a single model, along with auxiliary tasks that further guide slot attention. We validate the proposed method on both in-context datasets: UCF-101 and Kinetics-400, and out-of-context datasets: SCUBA and HAT. Our proposed method shows favorable performance across different datasets compared to the baselines, demonstrating its effectiveness in diverse video understanding scenarios.
ALSTER: A Local Spatio-Temporal Expert for Online 3D Semantic Reconstruction
Nov 29, 2023We propose an online 3D semantic segmentation method that incrementally reconstructs a 3D semantic map from a stream of RGB-D frames. Unlike offline methods, ours is directly applicable to scenarios with real-time constraints, such as robotics or mixed reality. To overcome the inherent challenges of online methods, we make two main contributions. First, to effectively extract information from the input RGB-D video stream, we jointly estimate geometry and semantic labels per frame in 3D. A key focus of our approach is to reason about semantic entities both in the 2D input and the local 3D domain to leverage differences in spatial context and network architectures. Our method predicts 2D features using an off-the-shelf segmentation network. The extracted 2D features are refined by a lightweight 3D network to enable reasoning about the local 3D structure. Second, to efficiently deal with an infinite stream of input RGB-D frames, a subsequent network serves as a temporal expert predicting the incremental scene updates by leveraging 2D, 3D, and past information in a learned manner. These updates are then integrated into a global scene representation. Using these main contributions, our method can enable scenarios with real-time constraints and can scale to arbitrary scene sizes by processing and updating the scene only in a local region defined by the new measurement. Our experiments demonstrate improved results compared to existing online methods that purely operate in local regions and show that complementary sources of information can boost the performance. We provide a thorough ablation study on the benefits of different architectural as well as algorithmic design decisions. Our method yields competitive results on the popular ScanNet benchmark and SceneNN dataset.
ImageDream: Image-Prompt Multi-view Diffusion for 3D Generation
Dec 02, 2023We introduce "ImageDream," an innovative image-prompt, multi-view diffusion model for 3D object generation. ImageDream stands out for its ability to produce 3D models of higher quality compared to existing state-of-the-art, image-conditioned methods. Our approach utilizes a canonical camera coordination for the objects in images, improving visual geometry accuracy. The model is designed with various levels of control at each block inside the diffusion model based on the input image, where global control shapes the overall object layout and local control fine-tunes the image details. The effectiveness of ImageDream is demonstrated through extensive evaluations using a standard prompt list. For more information, visit our project page at https://Image-Dream.github.io.
Design and Performance Analysis of Index Modulation Empowered AFDM System
Dec 02, 2023In this letter, we incorporate index modulation (IM) into affine frequency division multiplexing (AFDM), called AFDM-IM, to enhance the bit error rate (BER) and energy efficiency (EE) performance. In this scheme, the information bits are conveyed not only by $M$-ary constellation symbols, but also by the activation of the chirp subcarriers (SCs) indices, which are determined based on the incoming bit streams. Then, two power allocation strategies, namely power reallocation (PR) strategy and power saving (PS) strategy, are proposed to enhance BER and EE performance, respectively. Furthermore, the average bit error probability (ABEP) is theoretically analyzed. Simulation results demonstrate that the proposed AFDM-IM scheme achieves better BER performance than the conventional AFDM scheme.
U-Net v2: Rethinking the Skip Connections of U-Net for Medical Image Segmentation
Nov 29, 2023In this paper, we introduce U-Net v2, a new robust and efficient U-Net variant for medical image segmentation. It aims to augment the infusion of semantic information into low-level features while simultaneously refining high-level features with finer details. For an input image, we begin by extracting multi-level features with a deep neural network encoder. Next, we enhance the feature map of each level by infusing semantic information from higher-level features and integrating finer details from lower-level features through Hadamard product. Our novel skip connections empower features of all the levels with enriched semantic characteristics and intricate details. The improved features are subsequently transmitted to the decoder for further processing and segmentation. Our method can be seamlessly integrated into any Encoder-Decoder network. We evaluate our method on several public medical image segmentation datasets for skin lesion segmentation and polyp segmentation, and the experimental results demonstrate the segmentation accuracy of our new method over state-of-the-art methods, while preserving memory and computational efficiency. Code is available at: https://github.com/yaoppeng/U-Net\_v2
Using Ornstein-Uhlenbeck Process to understand Denoising Diffusion Probabilistic Model and its Noise Schedules
Nov 29, 2023The aim of this short note is to show that Denoising Diffusion Probabilistic Model DDPM, a non-homogeneous discrete-time Markov process, can be represented by a time-homogeneous continuous-time Markov process observed at non-uniformly sampled discrete times. Surprisingly, this continuous-time Markov process is the well-known and well-studied Ornstein-Ohlenbeck (OU) process, which was developed in 1930's for studying Brownian particles in Harmonic potentials. We establish the formal equivalence between DDPM and the OU process using its analytical solution. We further demonstrate that the design problem of the noise scheduler for non-homogeneous DDPM is equivalent to designing observation times for the OU process. We present several heuristic designs for observation times based on principled quantities such as auto-variance and Fisher Information and connect them to ad hoc noise schedules for DDPM. Interestingly, we show that the Fisher-Information-motivated schedule corresponds exactly the cosine schedule, which was developed without any theoretical foundation but is the current state-of-the-art noise schedule.
DiffusionPCR: Diffusion Models for Robust Multi-Step Point Cloud Registration
Dec 05, 2023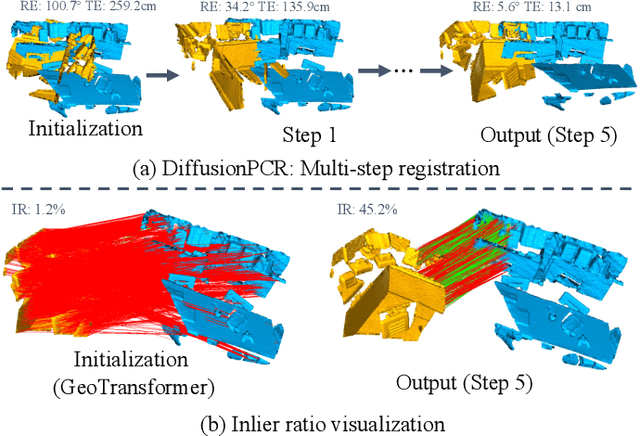
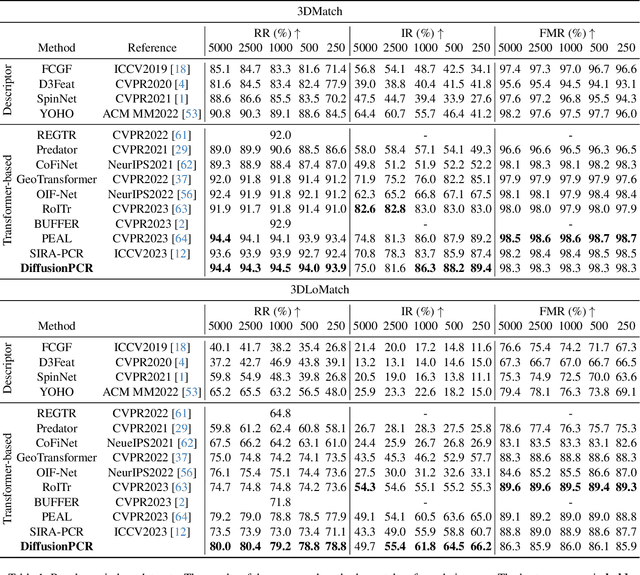
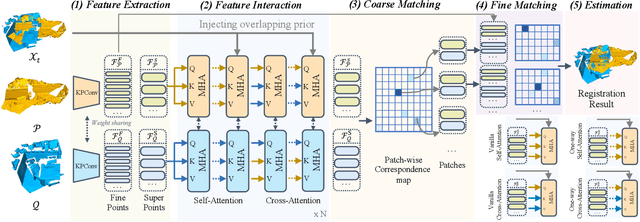
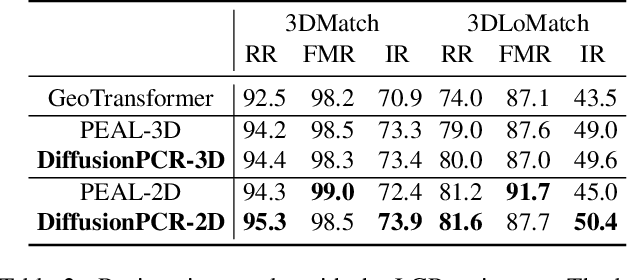
Point Cloud Registration (PCR) estimates the relative rigid transformation between two point clouds. We propose formulating PCR as a denoising diffusion probabilistic process, mapping noisy transformations to the ground truth. However, using diffusion models for PCR has nontrivial challenges, such as adapting a generative model to a discriminative task and leveraging the estimated nonlinear transformation from the previous step. Instead of training a diffusion model to directly map pure noise to ground truth, we map the predictions of an off-the-shelf PCR model to ground truth. The predictions of off-the-shelf models are often imperfect, especially in challenging cases where the two points clouds have low overlap, and thus could be seen as noisy versions of the real rigid transformation. In addition, we transform the rotation matrix into a spherical linear space for interpolation between samples in the forward process, and convert rigid transformations into auxiliary information to implicitly exploit last-step estimations in the reverse process. As a result, conditioned on time step, the denoising model adapts to the increasing accuracy across steps and refines registrations. Our extensive experiments showcase the effectiveness of our DiffusionPCR, yielding state-of-the-art registration recall rates (95.3%/81.6%) on 3DMatch and 3DLoMatch. The code will be made public upon publication.
Generating Visually Realistic Adversarial Patch
Dec 05, 2023Deep neural networks (DNNs) are vulnerable to various types of adversarial examples, bringing huge threats to security-critical applications. Among these, adversarial patches have drawn increasing attention due to their good applicability to fool DNNs in the physical world. However, existing works often generate patches with meaningless noise or patterns, making it conspicuous to humans. To address this issue, we explore how to generate visually realistic adversarial patches to fool DNNs. Firstly, we analyze that a high-quality adversarial patch should be realistic, position irrelevant, and printable to be deployed in the physical world. Based on this analysis, we propose an effective attack called VRAP, to generate visually realistic adversarial patches. Specifically, VRAP constrains the patch in the neighborhood of a real image to ensure the visual reality, optimizes the patch at the poorest position for position irrelevance, and adopts Total Variance loss as well as gamma transformation to make the generated patch printable without losing information. Empirical evaluations on the ImageNet dataset demonstrate that the proposed VRAP exhibits outstanding attack performance in the digital world. Moreover, the generated adversarial patches can be disguised as the scrawl or logo in the physical world to fool the deep models without being detected, bringing significant threats to DNNs-enabled applications.
On the Initialization of Graph Neural Networks
Dec 05, 2023Graph Neural Networks (GNNs) have displayed considerable promise in graph representation learning across various applications. The core learning process requires the initialization of model weight matrices within each GNN layer, which is typically accomplished via classic initialization methods such as Xavier initialization. However, these methods were originally motivated to stabilize the variance of hidden embeddings and gradients across layers of Feedforward Neural Networks (FNNs) and Convolutional Neural Networks (CNNs) to avoid vanishing gradients and maintain steady information flow. In contrast, within the GNN context classical initializations disregard the impact of the input graph structure and message passing on variance. In this paper, we analyze the variance of forward and backward propagation across GNN layers and show that the variance instability of GNN initializations comes from the combined effect of the activation function, hidden dimension, graph structure and message passing. To better account for these influence factors, we propose a new initialization method for Variance Instability Reduction within GNN Optimization (Virgo), which naturally tends to equate forward and backward variances across successive layers. We conduct comprehensive experiments on 15 datasets to show that Virgo can lead to superior model performance and more stable variance at initialization on node classification, link prediction and graph classification tasks. Codes are in https://github.com/LspongebobJH/virgo_icml2023.
FedBayes: A Zero-Trust Federated Learning Aggregation to Defend Against Adversarial Attacks
Dec 04, 2023Federated learning has created a decentralized method to train a machine learning model without needing direct access to client data. The main goal of a federated learning architecture is to protect the privacy of each client while still contributing to the training of the global model. However, the main advantage of privacy in federated learning is also the easiest aspect to exploit. Without being able to see the clients' data, it is difficult to determine the quality of the data. By utilizing data poisoning methods, such as backdoor or label-flipping attacks, or by sending manipulated information about their data back to the server, malicious clients are able to corrupt the global model and degrade performance across all clients within a federation. Our novel aggregation method, FedBayes, mitigates the effect of a malicious client by calculating the probabilities of a client's model weights given to the prior model's weights using Bayesian statistics. Our results show that this approach negates the effects of malicious clients and protects the overall federation.