 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Text Attribute Control via Closed-Loop Disentanglement
Dec 01, 2023
Changing an attribute of a text without changing the content usually requires to first disentangle the text into irrelevant attributes and content representations. After that, in the inference phase, the representation of one attribute is tuned to a different value, expecting that the corresponding attribute of the text can also be changed accordingly. The usual way of disentanglement is to add some constraints on the latent space of an encoder-decoder architecture, including adversarial-based constraints and mutual-information-based constraints. However, the previous semi-supervised processes of attribute change are usually not enough to guarantee the success of attribute change and content preservation. In this paper, we propose a novel approach to achieve a robust control of attributes while enhancing content preservation. In this approach, we use a semi-supervised contrastive learning method to encourage the disentanglement of attributes in latent spaces. Differently from previous works, we re-disentangle the reconstructed sentence and compare the re-disentangled latent space with the original latent space, which makes a closed-loop disentanglement process. This also helps content preservation. In addition, the contrastive learning method is also able to replace the role of minimizing mutual information and adversarial training in the disentanglement process, which alleviates the computation cost. We conducted experiments on three text datasets, including the Yelp Service review dataset, the Amazon Product review dataset, and the GoEmotions dataset. The experimental results show the effectiveness of our model.
Revisiting the Optimality of Word Lengths
Dec 06, 2023Zipf (1935) posited that wordforms are optimized to minimize utterances' communicative costs. Under the assumption that cost is given by an utterance's length, he supported this claim by showing that words' lengths are inversely correlated with their frequencies. Communicative cost, however, can be operationalized in different ways. Piantadosi et al. (2011) claim that cost should be measured as the distance between an utterance's information rate and channel capacity, which we dub the channel capacity hypothesis (CCH) here. Following this logic, they then proposed that a word's length should be proportional to the expected value of its surprisal (negative log-probability in context). In this work, we show that Piantadosi et al.'s derivation does not minimize CCH's cost, but rather a lower bound, which we term CCH-lower. We propose a novel derivation, suggesting an improved way to minimize CCH's cost. Under this method, we find that a language's word lengths should instead be proportional to the surprisal's expectation plus its variance-to-mean ratio. Experimentally, we compare these three communicative cost functions: Zipf's, CCH-lower , and CCH. Across 13 languages and several experimental settings, we find that length is better predicted by frequency than either of the other hypotheses. In fact, when surprisal's expectation, or expectation plus variance-to-mean ratio, is estimated using better language models, it leads to worse word length predictions. We take these results as evidence that Zipf's longstanding hypothesis holds.
Iteratively Learn Diverse Strategies with State Distance Information
Oct 23, 2023
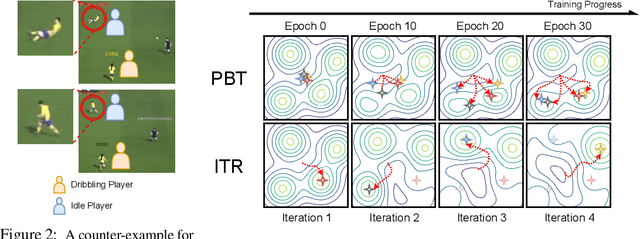
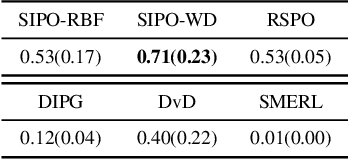

In complex reinforcement learning (RL) problems, policies with similar rewards may have substantially different behaviors. It remains a fundamental challenge to optimize rewards while also discovering as many diverse strategies as possible, which can be crucial in many practical applications. Our study examines two design choices for tackling this challenge, i.e., diversity measure and computation framework. First, we find that with existing diversity measures, visually indistinguishable policies can still yield high diversity scores. To accurately capture the behavioral difference, we propose to incorporate the state-space distance information into the diversity measure. In addition, we examine two common computation frameworks for this problem, i.e., population-based training (PBT) and iterative learning (ITR). We show that although PBT is the precise problem formulation, ITR can achieve comparable diversity scores with higher computation efficiency, leading to improved solution quality in practice. Based on our analysis, we further combine ITR with two tractable realizations of the state-distance-based diversity measures and develop a novel diversity-driven RL algorithm, State-based Intrinsic-reward Policy Optimization (SIPO), with provable convergence properties. We empirically examine SIPO across three domains from robot locomotion to multi-agent games. In all of our testing environments, SIPO consistently produces strategically diverse and human-interpretable policies that cannot be discovered by existing baselines.
Cooperative Dual Attention for Audio-Visual Speech Enhancement with Facial Cues
Nov 24, 2023In this work, we focus on leveraging facial cues beyond the lip region for robust Audio-Visual Speech Enhancement (AVSE). The facial region, encompassing the lip region, reflects additional speech-related attributes such as gender, skin color, nationality, etc., which contribute to the effectiveness of AVSE. However, static and dynamic speech-unrelated attributes also exist, causing appearance changes during speech. To address these challenges, we propose a Dual Attention Cooperative Framework, DualAVSE, to ignore speech-unrelated information, capture speech-related information with facial cues, and dynamically integrate it with the audio signal for AVSE. Specifically, we introduce a spatial attention-based visual encoder to capture and enhance visual speech information beyond the lip region, incorporating global facial context and automatically ignoring speech-unrelated information for robust visual feature extraction. Additionally, a dynamic visual feature fusion strategy is introduced by integrating a temporal-dimensional self-attention module, enabling the model to robustly handle facial variations. The acoustic noise in the speaking process is variable, impacting audio quality. Therefore, a dynamic fusion strategy for both audio and visual features is introduced to address this issue. By integrating cooperative dual attention in the visual encoder and audio-visual fusion strategy, our model effectively extracts beneficial speech information from both audio and visual cues for AVSE. Thorough analysis and comparison on different datasets, including normal and challenging cases with unreliable or absent visual information, consistently show our model outperforming existing methods across multiple metrics.
Information-Theoretic Generalization Analysis for Topology-aware Heterogeneous Federated Edge Learning over Noisy Channels
Oct 25, 2023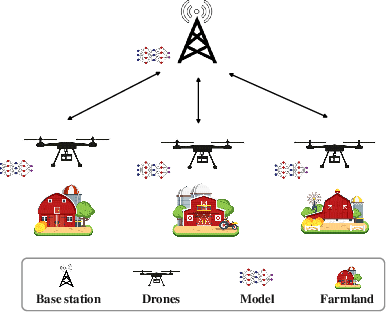
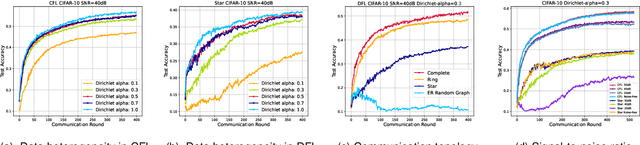
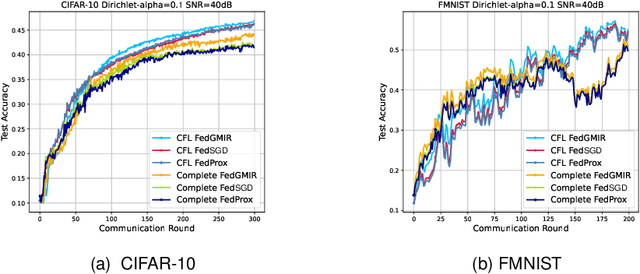
With the rapid growth of edge intelligence, the deployment of federated learning (FL) over wireless networks has garnered increasing attention, which is called Federated Edge Learning (FEEL). In FEEL, both mobile devices transmitting model parameters over noisy channels and collecting data in diverse environments pose challenges to the generalization of trained models. Moreover, devices can engage in decentralized FL via Device-to-Device communication while the communication topology of connected devices also impacts the generalization of models. Most recent theoretical studies overlook the incorporation of all these effects into FEEL when developing generalization analyses. In contrast, our work presents an information-theoretic generalization analysis for topology-aware FEEL in the presence of data heterogeneity and noisy channels. Additionally, we propose a novel regularization method called Federated Global Mutual Information Reduction (FedGMIR) to enhance the performance of models based on our analysis. Numerical results validate our theoretical findings and provide evidence for the effectiveness of the proposed method.
BIOCLIP: A Vision Foundation Model for the Tree of Life
Nov 30, 2023

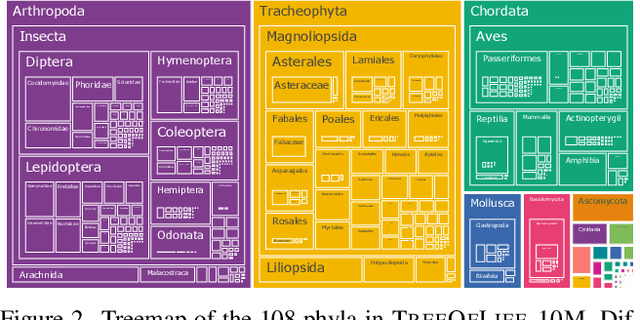

Images of the natural world, collected by a variety of cameras, from drones to individual phones, are increasingly abundant sources of biological information. There is an explosion of computational methods and tools, particularly computer vision, for extracting biologically relevant information from images for science and conservation. Yet most of these are bespoke approaches designed for a specific task and are not easily adaptable or extendable to new questions, contexts, and datasets. A vision model for general organismal biology questions on images is of timely need. To approach this, we curate and release TreeOfLife-10M, the largest and most diverse ML-ready dataset of biology images. We then develop BioCLIP, a foundation model for the tree of life, leveraging the unique properties of biology captured by TreeOfLife-10M, namely the abundance and variety of images of plants, animals, and fungi, together with the availability of rich structured biological knowledge. We rigorously benchmark our approach on diverse fine-grained biology classification tasks, and find that BioCLIP consistently and substantially outperforms existing baselines (by 17% to 20% absolute). Intrinsic evaluation reveals that BioCLIP has learned a hierarchical representation conforming to the tree of life, shedding light on its strong generalizability. Our code, models and data will be made available at https://github.com/Imageomics/bioclip.
Channel-Feedback-Free Transmission for Downlink FD-RAN: A Radio Map based Complex-valued Precoding Network Approach
Nov 30, 2023As the demand for high-quality services proliferates, an innovative network architecture, the fully-decoupled RAN (FD-RAN), has emerged for more flexible spectrum resource utilization and lower network costs. However, with the decoupling of uplink base stations and downlink base stations in FD-RAN, the traditional transmission mechanism, which relies on real-time channel feedback, is not suitable as the receiver is not able to feedback accurate and timely channel state information to the transmitter. This paper proposes a novel transmission scheme without relying on physical layer channel feedback. Specifically, we design a radio map based complex-valued precoding network~(RMCPNet) model, which outputs the base station precoding based on user location. RMCPNet comprises multiple subnets, with each subnet responsible for extracting unique modal features from diverse input modalities. Furthermore, the multi-modal embeddings derived from these distinct subnets are integrated within the information fusion layer, culminating in a unified representation. We also develop a specific RMCPNet training algorithm that employs the negative spectral efficiency as the loss function. We evaluate the performance of the proposed scheme on the public DeepMIMO dataset and show that RMCPNet can achieve 16\% and 76\% performance improvements over the conventional real-valued neural network and statistical codebook approach, respectively.
DEVIAS: Learning Disentangled Video Representations of Action and Scene for Holistic Video Understanding
Nov 30, 2023When watching a video, humans can naturally extract human actions from the surrounding scene context, even when action-scene combinations are unusual. However, unlike humans, video action recognition models often learn scene-biased action representations from the spurious correlation in training data, leading to poor performance in out-of-context scenarios. While scene-debiased models achieve improved performance in out-of-context scenarios, they often overlook valuable scene information in the data. Addressing this challenge, we propose Disentangled VIdeo representations of Action and Scene (DEVIAS), which aims to achieve holistic video understanding. Disentangled action and scene representations with our method could provide flexibility to adjust the emphasis on action or scene information depending on downstream task and dataset characteristics. Disentangled action and scene representations could be beneficial for both in-context and out-of-context video understanding. To this end, we employ slot attention to learn disentangled action and scene representations with a single model, along with auxiliary tasks that further guide slot attention. We validate the proposed method on both in-context datasets: UCF-101 and Kinetics-400, and out-of-context datasets: SCUBA and HAT. Our proposed method shows favorable performance across different datasets compared to the baselines, demonstrating its effectiveness in diverse video understanding scenarios.
Reasoning with the Theory of Mind for Pragmatic Semantic Communication
Nov 30, 2023In this paper, a pragmatic semantic communication framework that enables effective goal-oriented information sharing between two-intelligent agents is proposed. In particular, semantics is defined as the causal state that encapsulates the fundamental causal relationships and dependencies among different features extracted from data. The proposed framework leverages the emerging concept in machine learning (ML) called theory of mind (ToM). It employs a dynamic two-level (wireless and semantic) feedback mechanism to continuously fine-tune neural network components at the transmitter. Thanks to the ToM, the transmitter mimics the actual mental state of the receiver's reasoning neural network operating semantic interpretation. Then, the estimated mental state at the receiver is dynamically updated thanks to the proposed dynamic two-level feedback mechanism. At the lower level, conventional channel quality metrics are used to optimize the channel encoding process based on the wireless communication channel's quality, ensuring an efficient mapping of semantic representations to a finite constellation. Additionally, a semantic feedback level is introduced, providing information on the receiver's perceived semantic effectiveness with minimal overhead. Numerical evaluations demonstrate the framework's ability to achieve efficient communication with a reduced amount of bits while maintaining the same semantics, outperforming conventional systems that do not exploit the ToM-based reasoning.
Design and Performance Analysis of Index Modulation Empowered AFDM System
Dec 02, 2023In this letter, we incorporate index modulation (IM) into affine frequency division multiplexing (AFDM), called AFDM-IM, to enhance the bit error rate (BER) and energy efficiency (EE) performance. In this scheme, the information bits are conveyed not only by $M$-ary constellation symbols, but also by the activation of the chirp subcarriers (SCs) indices, which are determined based on the incoming bit streams. Then, two power allocation strategies, namely power reallocation (PR) strategy and power saving (PS) strategy, are proposed to enhance BER and EE performance, respectively. Furthermore, the average bit error probability (ABEP) is theoretically analyzed. Simulation results demonstrate that the proposed AFDM-IM scheme achieves better BER performance than the conventional AFDM scheme.