 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Interpretable Medical Image Classification using Prototype Learning and Privileged Information
Oct 24, 2023
Interpretability is often an essential requirement in medical imaging. Advanced deep learning methods are required to address this need for explainability and high performance. In this work, we investigate whether additional information available during the training process can be used to create an understandable and powerful model. We propose an innovative solution called Proto-Caps that leverages the benefits of capsule networks, prototype learning and the use of privileged information. Evaluating the proposed solution on the LIDC-IDRI dataset shows that it combines increased interpretability with above state-of-the-art prediction performance. Compared to the explainable baseline model, our method achieves more than 6 % higher accuracy in predicting both malignancy (93.0 %) and mean characteristic features of lung nodules. Simultaneously, the model provides case-based reasoning with prototype representations that allow visual validation of radiologist-defined attributes.
* MICCAI 2023 Medical Image Computing and Computer Assisted Intervention
DKiS: Decay weight invertible image steganography with private key
Nov 30, 2023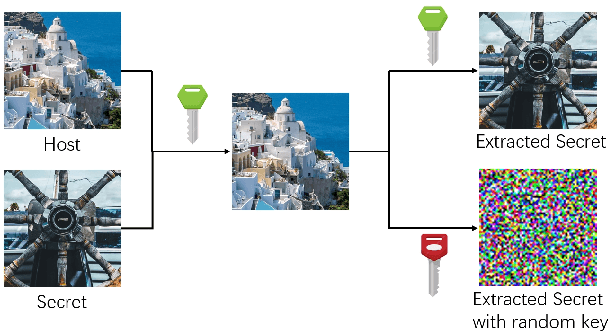
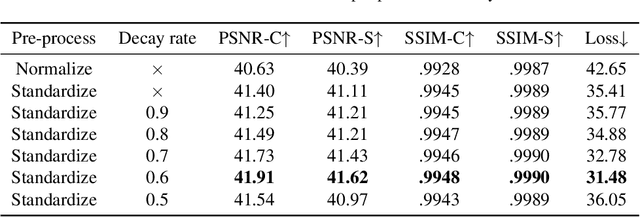
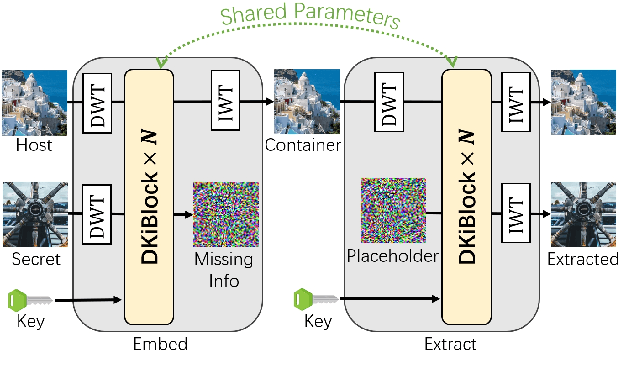

Image steganography, the practice of concealing information within another image, traditionally faces security challenges when its methods become publicly known. To counteract this, we introduce a novel private key-based image steganography technique. This approach ensures the security of hidden information, requiring a corresponding private key for access, irrespective of the public knowledge of the steganography method. We present experimental evidence demonstrating our method's effectiveness, showcasing its real-world applicability. Additionally, we identified a critical challenge in the invertible image steganography process: the transfer of non-essential, or `garbage', information from the secret to the host pipeline. To address this, we introduced the decay weight to control the information transfer, filtering out irrelevant data and enhancing the performance of image steganography. Our code is publicly accessible at https://github.com/yanghangAI/DKiS, and a practical demonstration is available at http://yanghang.site/hidekey.
Has Anything Changed? 3D Change Detection by 2D Segmentation Masks
Dec 02, 2023As capturing devices become common, 3D scans of interior spaces are acquired on a daily basis. Through scene comparison over time, information about objects in the scene and their changes is inferred. This information is important for robots and AR and VR devices, in order to operate in an immersive virtual experience. We thus propose an unsupervised object discovery method that identifies added, moved, or removed objects without any prior knowledge of what objects exist in the scene. We model this problem as a combination of a 3D change detection and a 2D segmentation task. Our algorithm leverages generic 2D segmentation masks to refine an initial but incomplete set of 3D change detections. The initial changes, acquired through render-and-compare likely correspond to movable objects. The incomplete detections are refined through graph optimization, distilling the information of the 2D segmentation masks in the 3D space. Experiments on the 3Rscan dataset prove that our method outperforms competitive baselines, with SoTA results.
CoSeR: Bridging Image and Language for Cognitive Super-Resolution
Dec 02, 2023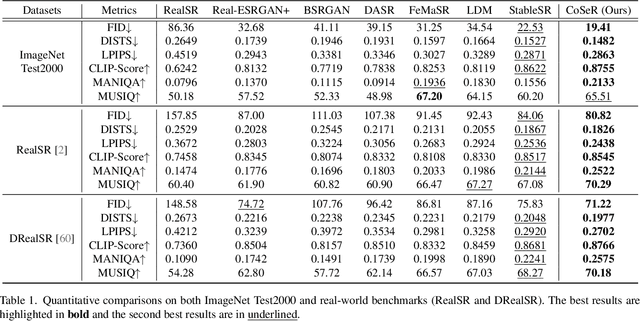
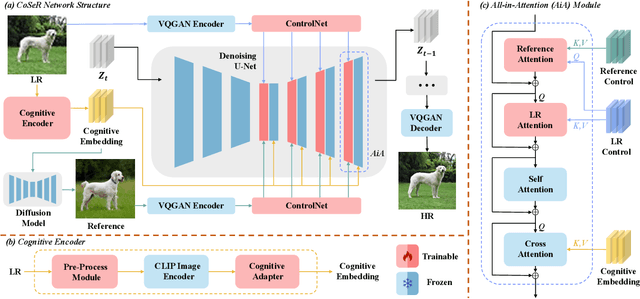
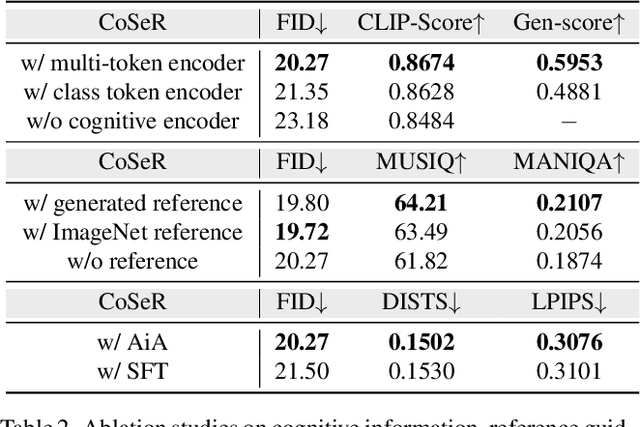
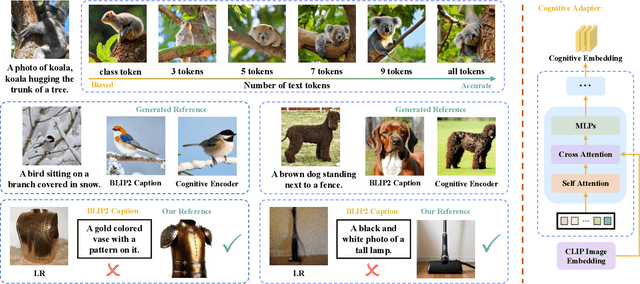
Existing super-resolution (SR) models primarily focus on restoring local texture details, often neglecting the global semantic information within the scene. This oversight can lead to the omission of crucial semantic details or the introduction of inaccurate textures during the recovery process. In our work, we introduce the Cognitive Super-Resolution (CoSeR) framework, empowering SR models with the capacity to comprehend low-resolution images. We achieve this by marrying image appearance and language understanding to generate a cognitive embedding, which not only activates prior information from large text-to-image diffusion models but also facilitates the generation of high-quality reference images to optimize the SR process. To further improve image fidelity, we propose a novel condition injection scheme called "All-in-Attention", consolidating all conditional information into a single module. Consequently, our method successfully restores semantically correct and photorealistic details, demonstrating state-of-the-art performance across multiple benchmarks. Code: https://github.com/VINHYU/CoSeR
Classification of retail products: From probabilistic ranking to neural networks
Dec 12, 2023Food retailing is now on an accelerated path to a success penetration into the digital market by new ways of value creation at all stages of the consumer decision process. One of the most important imperatives in this path is the availability of quality data to feed all the process in digital transformation. But the quality of data is not so obvious if we consider the variety of products and suppliers in the grocery market. Within this context of digital transformation of grocery industry, \textit{Midiadia} is Spanish data provider company that works on converting data from the retailers' products into knowledge with attributes and insights from the product labels, that is, maintaining quality data in a dynamic market with a high dispersion of products. Currently, they manually categorize products (groceries) according to the information extracted directly (text processing) from the product labelling and packaging. This paper introduces a solution to automatically categorize the constantly changing product catalogue into a 3-level food taxonomy. Our proposal studies three different approaches: a score-based ranking method, traditional machine learning algorithms, and deep neural networks. Thus, we provide four different classifiers that support a more efficient and less error-prone maintenance of groceries catalogues, the main asset of the company. Finally, we have compared the performance of these three alternatives, concluding that traditional machine learning algorithms perform better, but closely followed by the score-based approach.
* 17 pages, 8 figures, journal
Learned representation-guided diffusion models for large-image generation
Dec 12, 2023To synthesize high-fidelity samples, diffusion models typically require auxiliary data to guide the generation process. However, it is impractical to procure the painstaking patch-level annotation effort required in specialized domains like histopathology and satellite imagery; it is often performed by domain experts and involves hundreds of millions of patches. Modern-day self-supervised learning (SSL) representations encode rich semantic and visual information. In this paper, we posit that such representations are expressive enough to act as proxies to fine-grained human labels. We introduce a novel approach that trains diffusion models conditioned on embeddings from SSL. Our diffusion models successfully project these features back to high-quality histopathology and remote sensing images. In addition, we construct larger images by assembling spatially consistent patches inferred from SSL embeddings, preserving long-range dependencies. Augmenting real data by generating variations of real images improves downstream classifier accuracy for patch-level and larger, image-scale classification tasks. Our models are effective even on datasets not encountered during training, demonstrating their robustness and generalizability. Generating images from learned embeddings is agnostic to the source of the embeddings. The SSL embeddings used to generate a large image can either be extracted from a reference image, or sampled from an auxiliary model conditioned on any related modality (e.g. class labels, text, genomic data). As proof of concept, we introduce the text-to-large image synthesis paradigm where we successfully synthesize large pathology and satellite images out of text descriptions.
On the notion of Hallucinations from the lens of Bias and Validity in Synthetic CXR Images
Dec 12, 2023Medical imaging has revolutionized disease diagnosis, yet the potential is hampered by limited access to diverse and privacy-conscious datasets. Open-source medical datasets, while valuable, suffer from data quality and clinical information disparities. Generative models, such as diffusion models, aim to mitigate these challenges. At Stanford, researchers explored the utility of a fine-tuned Stable Diffusion model (RoentGen) for medical imaging data augmentation. Our work examines specific considerations to expand the Stanford research question, Could Stable Diffusion Solve a Gap in Medical Imaging Data? from the lens of bias and validity of the generated outcomes. We leveraged RoentGen to produce synthetic Chest-XRay (CXR) images and conducted assessments on bias, validity, and hallucinations. Diagnostic accuracy was evaluated by a disease classifier, while a COVID classifier uncovered latent hallucinations. The bias analysis unveiled disparities in classification performance among various subgroups, with a pronounced impact on the Female Hispanic subgroup. Furthermore, incorporating race and gender into input prompts exacerbated fairness issues in the generated images. The quality of synthetic images exhibited variability, particularly in certain disease classes, where there was more significant uncertainty compared to the original images. Additionally, we observed latent hallucinations, with approximately 42% of the images incorrectly indicating COVID, hinting at the presence of hallucinatory elements. These identifications provide new research directions towards interpretability of synthetic CXR images, for further understanding of associated risks and patient safety in medical applications.
SM70: A Large Language Model for Medical Devices
Dec 12, 2023We are introducing SM70, a 70 billion-parameter Large Language Model that is specifically designed for SpassMed's medical devices under the brand name 'JEE1' (pronounced as G1 and means 'Life'). This large language model provides more accurate and safe responses to medical-domain questions. To fine-tune SM70, we used around 800K data entries from the publicly available dataset MedAlpaca. The Llama2 70B open-sourced model served as the foundation for SM70, and we employed the QLoRA technique for fine-tuning. The evaluation is conducted across three benchmark datasets - MEDQA - USMLE, PUBMEDQA, and USMLE - each representing a unique aspect of medical knowledge and reasoning. The performance of SM70 is contrasted with other notable LLMs, including Llama2 70B, Clinical Camel 70 (CC70), GPT 3.5, GPT 4, and Med-Palm, to provide a comparative understanding of its capabilities within the medical domain. Our results indicate that SM70 outperforms several established models in these datasets, showcasing its proficiency in handling a range of medical queries, from fact-based questions derived from PubMed abstracts to complex clinical decision-making scenarios. The robust performance of SM70, particularly in the USMLE and PUBMEDQA datasets, suggests its potential as an effective tool in clinical decision support and medical information retrieval. Despite its promising results, the paper also acknowledges the areas where SM70 lags behind the most advanced model, GPT 4, thereby highlighting the need for further development, especially in tasks demanding extensive medical knowledge and intricate reasoning.
Adapting Short-Term Transformers for Action Detection in Untrimmed Videos
Dec 04, 2023Vision transformer (ViT) has shown high potential in video recognition, owing to its flexible design, adaptable self-attention mechanisms, and the efficacy of masked pre-training. Yet, it still remains unclear how to adapt these pre-trained short-term ViTs for temporal action detection (TAD) in untrimmed videos. The existing works treat them as off-the-shelf feature extractors for each short trimmed snippet without capturing the fine-grained relation among different snippets in a broader temporal context. To mitigate this issue, this paper focuses on designing a new mechanism for adapting these pre-trained ViT models as a unified long-form video transformer to fully unleash its modeling power in capturing inter-snippet relation, while still keeping low computation overhead and memory consumption for efficient TAD. To this end, we design effective cross-snippet propagation modules to gradually exchange short-term video information among different snippets from two levels. For inner-backbone information propagation, we introduce a cross-snippet propagation strategy to enable multi-snippet temporal feature interaction inside the backbone. For post-backbone information propagation, we propose temporal transformer layers for further clip-level modeling. With the plain ViT-B pre-trained with VideoMAE, our end-to-end temporal action detector (ViT-TAD) yields a very competitive performance to previous temporal action detectors, riching up to 69.0 average mAP on THUMOS14, 37.12 average mAP on ActivityNet-1.3 and 17.20 average mAP on FineAction.
Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE 2023): Workshop and Shared Task Report
Dec 02, 2023We provide a summary of the sixth edition of the CASE workshop that is held in the scope of RANLP 2023. The workshop consists of regular papers, three keynotes, working papers of shared task participants, and shared task overview papers. This workshop series has been bringing together all aspects of event information collection across technical and social science fields. In addition to contributing to the progress in text based event extraction, the workshop provides a space for the organization of a multimodal event information collection task.