 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Ego-Motion Aware Target Prediction Module for Robust Multi-Object Tracking
Apr 03, 2024
Multi-object tracking (MOT) is a prominent task in computer vision with application in autonomous driving, responsible for the simultaneous tracking of multiple object trajectories. Detection-based multi-object tracking (DBT) algorithms detect objects using an independent object detector and predict the imminent location of each target. Conventional prediction methods in DBT utilize Kalman Filter(KF) to extrapolate the target location in the upcoming frames by supposing a constant velocity motion model. These methods are especially hindered in autonomous driving applications due to dramatic camera motion or unavailable detections. Such limitations lead to tracking failures manifested by numerous identity switches and disrupted trajectories. In this paper, we introduce a novel KF-based prediction module called the Ego-motion Aware Target Prediction (EMAP) module by focusing on the integration of camera motion and depth information with object motion models. Our proposed method decouples the impact of camera rotational and translational velocity from the object trajectories by reformulating the Kalman Filter. This reformulation enables us to reject the disturbances caused by camera motion and maximizes the reliability of the object motion model. We integrate our module with four state-of-the-art base MOT algorithms, namely OC-SORT, Deep OC-SORT, ByteTrack, and BoT-SORT. In particular, our evaluation on the KITTI MOT dataset demonstrates that EMAP remarkably drops the number of identity switches (IDSW) of OC-SORT and Deep OC-SORT by 73% and 21%, respectively. At the same time, it elevates other performance metrics such as HOTA by more than 5%. Our source code is available at https://github.com/noyzzz/EMAP.
Leveraging CLIP for Inferring Sensitive Information and Improving Model Fairness
Mar 15, 2024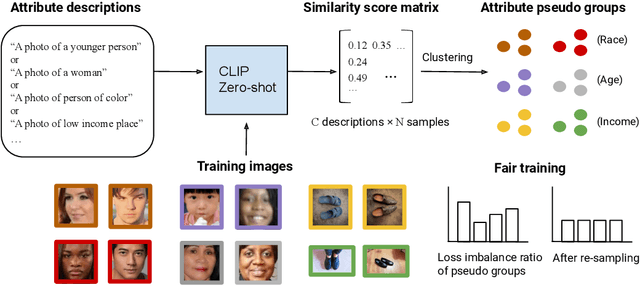

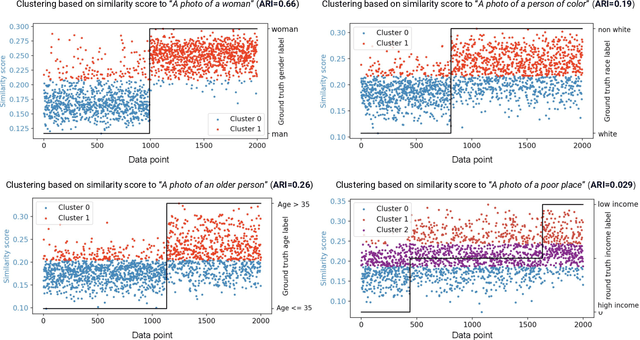

Performance disparities across sub-populations are known to exist in deep learning-based vision recognition models, but previous work has largely addressed such fairness concerns assuming knowledge of sensitive attribute labels. To overcome this reliance, previous strategies have involved separate learning structures to expose and adjust for disparities. In this work, we explore a new paradigm that does not require sensitive attribute labels, and evades the need for extra training by leveraging the vision-language model, CLIP, as a rich knowledge source to infer sensitive information. We present sample clustering based on similarity derived from image and attribute-specified language embeddings and assess their correspondence to true attribute distribution. We train a target model by re-sampling and augmenting under-performed clusters. Extensive experiments on multiple benchmark bias datasets show clear fairness gains of the model over existing baselines, which indicate that CLIP can extract discriminative sensitive information prompted by language, and used to promote model fairness.
Query-driven Relevant Paragraph Extraction from Legal Judgments
Mar 31, 2024Legal professionals often grapple with navigating lengthy legal judgements to pinpoint information that directly address their queries. This paper focus on this task of extracting relevant paragraphs from legal judgements based on the query. We construct a specialized dataset for this task from the European Court of Human Rights (ECtHR) using the case law guides. We assess the performance of current retrieval models in a zero-shot way and also establish fine-tuning benchmarks using various models. The results highlight the significant gap between fine-tuned and zero-shot performance, emphasizing the challenge of handling distribution shift in the legal domain. We notice that the legal pre-training handles distribution shift on the corpus side but still struggles on query side distribution shift, with unseen legal queries. We also explore various Parameter Efficient Fine-Tuning (PEFT) methods to evaluate their practicality within the context of information retrieval, shedding light on the effectiveness of different PEFT methods across diverse configurations with pre-training and model architectures influencing the choice of PEFT method.
Performance Evaluation of RIS-Assisted Spatial Modulation for Downlink Transmission
Apr 01, 2024This paper explores the performance of reconfigurable intelligent surface (RIS) assisted spatial modulation (SM) downlink communication systems, focusing on the average bit error probability (ABEP). Notably, in scenarios with a large number of reflecting units, the composite channel can be approximated by a Gaussian distribution using the central limit theorem. The receiver utilizes a maximum likelihood detector to recover information in both spatial and symbol domains. In the proposed RIS-SM system, we analytically derive a closed-form expression for the union tight upper bound of ABEP, employing the Gaussian-Chebyshev quadrature method. The validity of these results is rigorously confirmed through exhaustive Monte Carlo simulations.
Task-priority Intermediated Hierarchical Distributed Policies: Reinforcement Learning of Adaptive Multi-robot Cooperative Transport
Apr 02, 2024Multi-robot cooperative transport is crucial in logistics, housekeeping, and disaster response. However, it poses significant challenges in environments where objects of various weights are mixed and the number of robots and objects varies. This paper presents Task-priority Intermediated Hierarchical Distributed Policies (TIHDP), a multi-agent Reinforcement Learning (RL) framework that addresses these challenges through a hierarchical policy structure. TIHDP consists of three layers: task allocation policy (higher layer), dynamic task priority (intermediate layer), and robot control policy (lower layer). Whereas the dynamic task priority layer can manipulate the priority of any object to be transported by receiving global object information and communicating with other robots, the task allocation and robot control policies are restricted by local observations/actions so that they are not affected by changes in the number of objects and robots. Through simulations and real-robot demonstrations, TIHDP shows promising adaptability and performance of the learned multi-robot cooperative transport, even in environments with varying numbers of robots and objects. Video is available at https://youtu.be/Rmhv5ovj0xM
LastResort at SemEval-2024 Task 3: Exploring Multimodal Emotion Cause Pair Extraction as Sequence Labelling Task
Apr 02, 2024Conversation is the most natural form of human communication, where each utterance can range over a variety of possible emotions. While significant work has been done towards the detection of emotions in text, relatively little work has been done towards finding the cause of the said emotions, especially in multimodal settings. SemEval 2024 introduces the task of Multimodal Emotion Cause Analysis in Conversations, which aims to extract emotions reflected in individual utterances in a conversation involving multiple modalities (textual, audio, and visual modalities) along with the corresponding utterances that were the cause for the emotion. In this paper, we propose models that tackle this task as an utterance labeling and a sequence labeling problem and perform a comparative study of these models, involving baselines using different encoders, using BiLSTM for adding contextual information of the conversation, and finally adding a CRF layer to try to model the inter-dependencies between adjacent utterances more effectively. In the official leaderboard for the task, our architecture was ranked 8th, achieving an F1-score of 0.1759 on the leaderboard.
Energy-Optimized Planning in Non-Uniform Wind Fields with Fixed-Wing Aerial Vehicles
Apr 02, 2024Fixed-wing small uncrewed aerial vehicles (sUAVs) possess the capability to remain airborne for extended durations and traverse vast distances. However, their operation is susceptible to wind conditions, particularly in regions of complex terrain where high wind speeds may push the aircraft beyond its operational limitations, potentially raising safety concerns. Moreover, wind impacts the energy required to follow a path, especially in locations where the wind direction and speed are not favorable. Incorporating wind information into mission planning is essential to ensure both safety and energy efficiency. In this paper, we propose a sampling-based planner using the kinematic Dubins aircraft paths with respect to the ground, to plan energy-efficient paths in non-uniform wind fields. We study the planner characteristics with synthetic and real-world wind data and compare its performance against baseline cost and path formulations. We demonstrate that the energy-optimized planner effectively utilizes updrafts to minimize energy consumption, albeit at the expense of increased travel time. The ground-relative path formulation facilitates the generation of safe trajectories onboard sUAVs within reasonable computational timeframes.
Polarity Calibration for Opinion Summarization
Apr 02, 2024Opinion summarization is automatically generating summaries from a variety of subjective information, such as product reviews or political opinions. The challenge of opinions summarization lies in presenting divergent or even conflicting opinions. We conduct an analysis of previous summarization models, which reveals their inclination to amplify the polarity bias, emphasizing the majority opinions while ignoring the minority opinions. To address this issue and make the summarizer express both sides of opinions, we introduce the concept of polarity calibration, which aims to align the polarity of output summary with that of input text. Specifically, we develop a reinforcement training approach for polarity calibration. This approach feeds the polarity distance between output summary and input text as reward into the summarizer, and also balance polarity calibration with content preservation and language naturality. We evaluate our Polarity Calibration model (PoCa) on two types of opinions summarization tasks: summarizing product reviews and political opinions articles. Automatic and human evaluation demonstrate that our approach can mitigate the polarity mismatch between output summary and input text, as well as maintain the content semantic and language quality.
Entity Disambiguation via Fusion Entity Decoding
Apr 02, 2024Entity disambiguation (ED), which links the mentions of ambiguous entities to their referent entities in a knowledge base, serves as a core component in entity linking (EL). Existing generative approaches demonstrate improved accuracy compared to classification approaches under the standardized ZELDA benchmark. Nevertheless, generative approaches suffer from the need for large-scale pre-training and inefficient generation. Most importantly, entity descriptions, which could contain crucial information to distinguish similar entities from each other, are often overlooked. We propose an encoder-decoder model to disambiguate entities with more detailed entity descriptions. Given text and candidate entities, the encoder learns interactions between the text and each candidate entity, producing representations for each entity candidate. The decoder then fuses the representations of entity candidates together and selects the correct entity. Our experiments, conducted on various entity disambiguation benchmarks, demonstrate the strong and robust performance of this model, particularly +1.5% in the ZELDA benchmark compared with GENRE. Furthermore, we integrate this approach into the retrieval/reader framework and observe +1.5% improvements in end-to-end entity linking in the GERBIL benchmark compared with EntQA.
Multi-Robot Collaborative Navigation with Formation Adaptation
Apr 02, 2024Multi-robot collaborative navigation is an essential ability where teamwork and synchronization are keys. In complex and uncertain environments, adaptive formation is vital, as rigid formations prove to be inadequate. The ability of robots to dynamically adjust their formation enables navigation through unpredictable spaces, maintaining cohesion, and effectively responding to environmental challenges. In this paper, we introduce a novel approach that uses bi-level learning framework. Specifically, we use graph learning at a high level for group coordination and reinforcement learning for individual navigation. We innovate by integrating a spring-damper model within the reinforcement learning reward mechanism, addressing the rigidity of traditional formation control methods. During execution, our approach enables a team of robots to successfully navigate challenging environments, maintain a desired formation shape, and dynamically adjust their formation scale based on environmental information. We conduct extensive experiments to evaluate our approach across three distinct formation scenarios in multi-robot navigation: circle, line, and wedge. Experimental results show that our approach achieves promising results and scalability on multi-robot navigation with formation adaptation.