 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
Dec 03, 2023
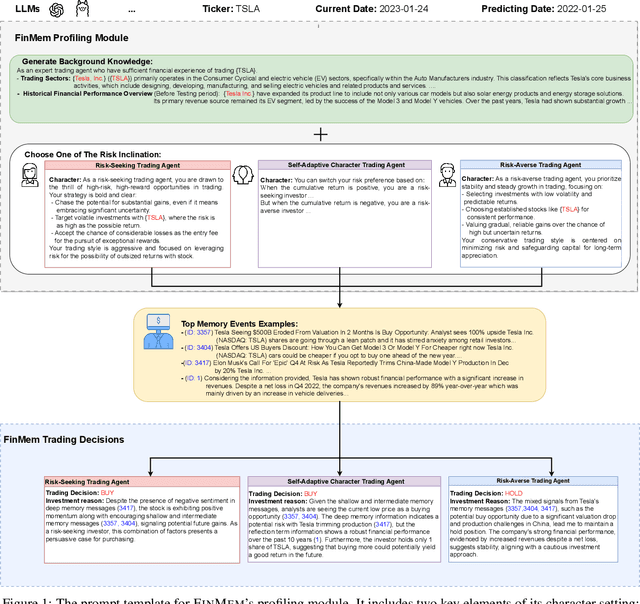
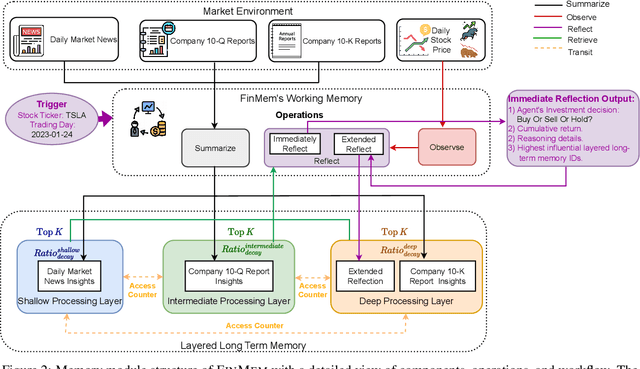
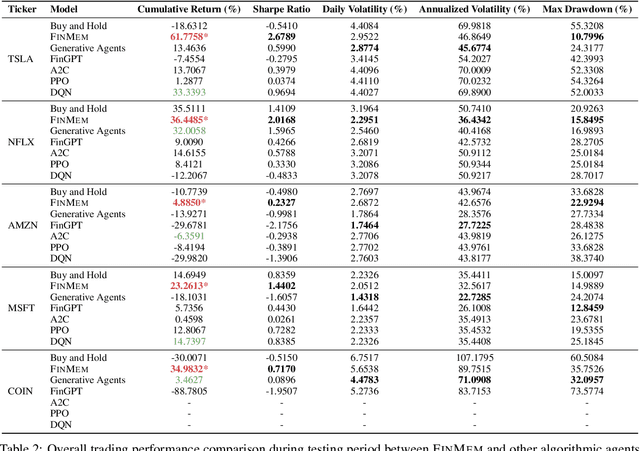

Recent advancements in Large Language Models (LLMs) have exhibited notable efficacy in question-answering (QA) tasks across diverse domains. Their prowess in integrating extensive web knowledge has fueled interest in developing LLM-based autonomous agents. While LLMs are efficient in decoding human instructions and deriving solutions by holistically processing historical inputs, transitioning to purpose-driven agents requires a supplementary rational architecture to process multi-source information, establish reasoning chains, and prioritize critical tasks. Addressing this, we introduce \textsc{FinMem}, a novel LLM-based agent framework devised for financial decision-making. It encompasses three core modules: Profiling, to customize the agent's characteristics; Memory, with layered message processing, to aid the agent in assimilating hierarchical financial data; and Decision-making, to convert insights gained from memories into investment decisions. Notably, \textsc{FinMem}'s memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. Its adjustable cognitive span allows for the retention of critical information beyond human perceptual limits, thereby enhancing trading outcomes. This framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. We first compare \textsc{FinMem} with various algorithmic agents on a scalable real-world financial dataset, underscoring its leading trading performance in stocks. We then fine-tuned the agent's perceptual span and character setting to achieve a significantly enhanced trading performance. Collectively, \textsc{FinMem} presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
ContextSeg: Sketch Semantic Segmentation by Querying the Context with Attention
Nov 28, 2023Sketch semantic segmentation is a well-explored and pivotal problem in computer vision involving the assignment of pre-defined part labels to individual strokes. This paper presents ContextSeg - a simple yet highly effective approach to tackling this problem with two stages. In the first stage, to better encode the shape and positional information of strokes, we propose to predict an extra dense distance field in an autoencoder network to reinforce structural information learning. In the second stage, we treat an entire stroke as a single entity and label a group of strokes within the same semantic part using an auto-regressive Transformer with the default attention mechanism. By group-based labeling, our method can fully leverage the context information when making decisions for the remaining groups of strokes. Our method achieves the best segmentation accuracy compared with state-of-the-art approaches on two representative datasets and has been extensively evaluated demonstrating its superior performance. Additionally, we offer insights into solving part imbalance in training data and the preliminary experiment on cross-category training, which can inspire future research in this field.
Unify Change Point Detection and Segment Classification in a Regression Task for Transportation Mode Identification
Dec 08, 2023Identifying travelers' transportation modes is important in transportation science and location-based services. It's appealing for researchers to leverage GPS trajectory data to infer transportation modes with the popularity of GPS-enabled devices, e.g., smart phones. Existing studies frame this problem as classification task. The dominant two-stage studies divide the trip into single-one mode segments first and then categorize these segments. The over segmentation strategy and inevitable error propagation bring difficulties to classification stage and make optimizing the whole system hard. The recent one-stage works throw out trajectory segmentation entirely to avoid these by directly conducting point-wise classification for the trip, whereas leaving predictions dis-continuous. To solve above-mentioned problems, inspired by YOLO and SSD in object detection, we propose to reframe change point detection and segment classification as a unified regression task instead of the existing classification task. We directly regress coordinates of change points and classify associated segments. In this way, our method divides the trip into segments under a supervised manner and leverage more contextual information, obtaining predictions with high accuracy and continuity. Two frameworks, TrajYOLO and TrajSSD, are proposed to solve the regression task and various feature extraction backbones are exploited. Exhaustive experiments on GeoLife dataset show that the proposed method has competitive overall identification accuracy of 0.853 when distinguishing five modes: walk, bike, bus, car, train. As for change point detection, our method increases precision at the cost of drop in recall. All codes are available at https://github.com/RadetzkyLi/TrajYOLO-SSD.
Visual Encoders for Data-Efficient Imitation Learning in Modern Video Games
Dec 04, 2023Video games have served as useful benchmarks for the decision making community, but going beyond Atari games towards training agents in modern games has been prohibitively expensive for the vast majority of the research community. Recent progress in the research, development and open release of large vision models has the potential to amortize some of these costs across the community. However, it is currently unclear which of these models have learnt representations that retain information critical for sequential decision making. Towards enabling wider participation in the research of gameplaying agents in modern games, we present a systematic study of imitation learning with publicly available visual encoders compared to the typical, task-specific, end-to-end training approach in Minecraft, Minecraft Dungeons and Counter-Strike: Global Offensive.
Exploring a Hybrid Deep Learning Framework to Automatically Discover Topic and Sentiment in COVID-19 Tweets
Dec 02, 2023COVID-19 has created a major public health problem worldwide and other problems such as economic crisis, unemployment, mental distress, etc. The pandemic is deadly in the world and involves many people not only with infection but also with problems, stress, wonder, fear, resentment, and hatred. Twitter is a highly influential social media platform and a significant source of health-related information, news, opinion and public sentiment where information is shared by both citizens and government sources. Therefore an effective analysis of COVID-19 tweets is essential for policymakers to make wise decisions. However, it is challenging to identify interesting and useful content from major streams of text to understand people's feelings about the important topics of the COVID-19 tweets. In this paper, we propose a new \textit{framework} for analyzing topic-based sentiments by extracting key topics with significant labels and classifying positive, negative, or neutral tweets on each topic to quickly find common topics of public opinion and COVID-19-related attitudes. While building our model, we take into account hybridization of BiLSTM and GRU structures for sentiment analysis to achieve our goal. The experimental results show that our topic identification method extracts better topic labels and the sentiment analysis approach using our proposed hybrid deep learning model achieves the highest accuracy compared to traditional models.
Adaptive Multi-Modality Prompt Learning
Nov 30, 2023Although current prompt learning methods have successfully been designed to effectively reuse the large pre-trained models without fine-tuning their large number of parameters, they still have limitations to be addressed, i.e., without considering the adverse impact of meaningless patches in every image and without simultaneously considering in-sample generalization and out-of-sample generalization. In this paper, we propose an adaptive multi-modality prompt learning to address the above issues. To do this, we employ previous text prompt learning and propose a new image prompt learning. The image prompt learning achieves in-sample and out-of-sample generalization, by first masking meaningless patches and then padding them with the learnable parameters and the information from texts. Moreover, each of the prompts provides auxiliary information to each other, further strengthening these two kinds of generalization. Experimental results on real datasets demonstrate that our method outperforms SOTA methods, in terms of different downstream tasks.
End-to-End Retrieval with Learned Dense and Sparse Representations Using Lucene
Nov 30, 2023The bi-encoder architecture provides a framework for understanding machine-learned retrieval models based on dense and sparse vector representations. Although these representations capture parametric realizations of the same underlying conceptual framework, their respective implementations of top-$k$ similarity search require the coordination of different software components (e.g., inverted indexes, HNSW indexes, and toolkits for neural inference), often knitted together in complex architectures. In this work, we ask the following question: What's the simplest design, in terms of requiring the fewest changes to existing infrastructure, that can support end-to-end retrieval with modern dense and sparse representations? The answer appears to be that Lucene is sufficient, as we demonstrate in Anserini, a toolkit for reproducible information retrieval research. That is, effective retrieval with modern single-vector neural models can be efficiently performed directly in Java on the CPU. We examine the implications of this design for information retrieval researchers pushing the state of the art as well as for software engineers building production search systems.
QIENet: Quantitative irradiance estimation network using recurrent neural network based on satellite remote sensing data
Dec 01, 2023Global horizontal irradiance (GHI) plays a vital role in estimating solar energy resources, which are used to generate sustainable green energy. In order to estimate GHI with high spatial resolution, a quantitative irradiance estimation network, named QIENet, is proposed. Specifically, the temporal and spatial characteristics of remote sensing data of the satellite Himawari-8 are extracted and fused by recurrent neural network (RNN) and convolution operation, respectively. Not only remote sensing data, but also GHI-related time information (hour, day, and month) and geographical information (altitude, longitude, and latitude), are used as the inputs of QIENet. The satellite spectral channels B07 and B11 - B15 and time are recommended as model inputs for QIENet according to the spatial distributions of annual solar energy. Meanwhile, QIENet is able to capture the impact of various clouds on hourly GHI estimates. More importantly, QIENet does not overestimate ground observations and can also reduce RMSE by 27.51%/18.00%, increase R2 by 20.17%/9.42%, and increase r by 8.69%/3.54% compared with ERA5/NSRDB. Furthermore, QIENet is capable of providing a high-fidelity hourly GHI database with spatial resolution 0.02{\deg} * 0.02{\deg}(approximately 2km * 2km) for many applied energy fields.
Towards Redundancy-Free Sub-networks in Continual Learning
Dec 01, 2023Catastrophic Forgetting (CF) is a prominent issue in continual learning. Parameter isolation addresses this challenge by masking a sub-network for each task to mitigate interference with old tasks. However, these sub-networks are constructed relying on weight magnitude, which does not necessarily correspond to the importance of weights, resulting in maintaining unimportant weights and constructing redundant sub-networks. To overcome this limitation, inspired by information bottleneck, which removes redundancy between adjacent network layers, we propose \textbf{\underline{I}nformation \underline{B}ottleneck \underline{M}asked sub-network (IBM)} to eliminate redundancy within sub-networks. Specifically, IBM accumulates valuable information into essential weights to construct redundancy-free sub-networks, not only effectively mitigating CF by freezing the sub-networks but also facilitating new tasks training through the transfer of valuable knowledge. Additionally, IBM decomposes hidden representations to automate the construction process and make it flexible. Extensive experiments demonstrate that IBM consistently outperforms state-of-the-art methods. Notably, IBM surpasses the state-of-the-art parameter isolation method with a 70\% reduction in the number of parameters within sub-networks and an 80\% decrease in training time.
Towards Top-Down Reasoning: An Explainable Multi-Agent Approach for Visual Question Answering
Nov 29, 2023Recently, Vision Language Models (VLMs) have gained significant attention, exhibiting notable advancements across various tasks by leveraging extensive image-text paired data. However, prevailing VLMs often treat Visual Question Answering (VQA) as perception tasks, employing black-box models that overlook explicit modeling of relationships between different questions within the same visual scene. Moreover, the existing VQA methods that rely on Knowledge Bases (KBs) might frequently encounter biases from limited data and face challenges in relevant information indexing. Attempt to overcome these limitations, this paper introduces an explainable multi-agent collaboration framework by tapping into knowledge embedded in Large Language Models (LLMs) trained on extensive corpora. Inspired by human cognition, our framework uncovers latent information within the given question by employing three agents, i.e., Seeker, Responder, and Integrator, to perform a top-down reasoning process. The Seeker agent generates relevant issues related to the original question. The Responder agent, based on VLM, handles simple VQA tasks and provides candidate answers. The Integrator agent combines information from the Seeker agent and the Responder agent to produce the final VQA answer. Through the above collaboration mechanism, our framework explicitly constructs a multi-view knowledge base for a specific image scene, reasoning answers in a top-down processing manner. We extensively evaluate our method on diverse VQA datasets and VLMs, demonstrating its broad applicability and interpretability with comprehensive experimental results.