 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decoupling Degradation and Content Processing for Adverse Weather Image Restoration
Dec 08, 2023
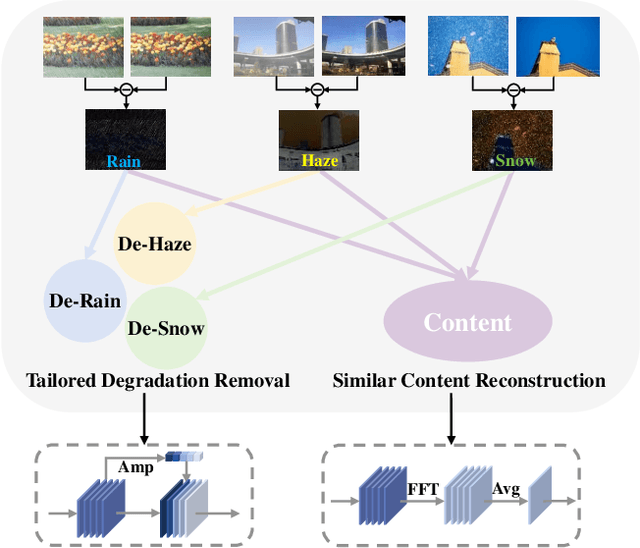
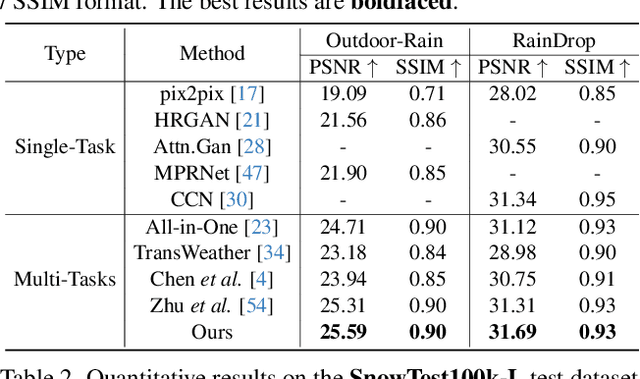
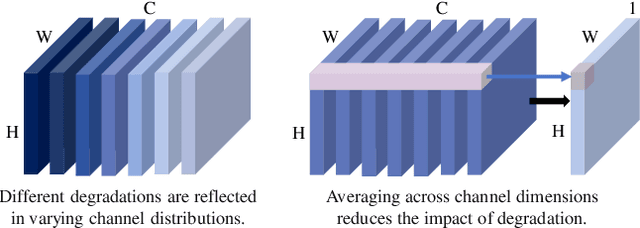
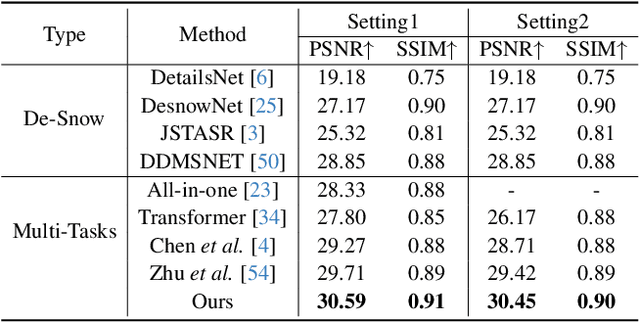
Adverse weather image restoration strives to recover clear images from those affected by various weather types, such as rain, haze, and snow. Each weather type calls for a tailored degradation removal approach due to its unique impact on images. Conversely, content reconstruction can employ a uniform approach, as the underlying image content remains consistent. Although previous techniques can handle multiple weather types within a single network, they neglect the crucial distinction between these two processes, limiting the quality of restored images. This work introduces a novel adverse weather image restoration method, called DDCNet, which decouples the degradation removal and content reconstruction process at the feature level based on their channel statistics. Specifically, we exploit the unique advantages of the Fourier transform in both these two processes: (1) the degradation information is mainly located in the amplitude component of the Fourier domain, and (2) the Fourier domain contains global information. The former facilitates channel-dependent degradation removal operation, allowing the network to tailor responses to various adverse weather types; the latter, by integrating Fourier's global properties into channel-independent content features, enhances network capacity for consistent global content reconstruction. We further augment the degradation removal process with a degradation mapping loss function. Extensive experiments demonstrate our method achieves state-of-the-art performance in multiple adverse weather removal benchmarks.
A Novel Framework Based on Variational Quantum Algorithms: Revolutionizing Image Classification
Dec 13, 2023Image classification is a crucial task in machine learning. In recent years, this field has witnessed rapid development, with a series of image classification models being proposed and achieving state-of-the-art (SOTA) results. Parallelly, with the advancement of quantum technologies, quantum machine learning has attracted a lot of interest. In particular, a class of algorithms known as variational quantum algorithms (VQAs) has been extensively studied to improve the performance of classical machine learning. In this paper, we propose a novel image classification framework using VQAs. The major advantage of our framework is the elimination of the need for the global pooling operation typically performed at the end of classical image classification models. While global pooling can help to reduce computational complexity, it often results in a significant loss of information. By removing the global pooling module before the output layer, our approach allows for effectively capturing more discriminative features and fine-grained details in images, leading to improved classification performance. Moreover, employing VQAs enables our framework to have fewer parameters compared to the classical framework, even in the absence of global pooling, which makes it more advantageous in preventing overfitting. We apply our method to different SOTA image classification models and demonstrate the superiority of the proposed quantum architecture over its classical counterpart through a series of experiments on public datasets.
Event-driven Real-time Retrieval in Web Search
Dec 04, 2023Information retrieval in real-time search presents unique challenges distinct from those encountered in classical web search. These challenges are particularly pronounced due to the rapid change of user search intent, which is influenced by the occurrence and evolution of breaking news events, such as earthquakes, elections, and wars. Previous dense retrieval methods, which primarily focused on static semantic representation, lack the capacity to capture immediate search intent, leading to inferior performance in retrieving the most recent event-related documents in time-sensitive scenarios. To address this issue, this paper expands the query with event information that represents real-time search intent. The Event information is then integrated with the query through a cross-attention mechanism, resulting in a time-context query representation. We further enhance the model's capacity for event representation through multi-task training. Since publicly available datasets such as MS-MARCO do not contain any event information on the query side and have few time-sensitive queries, we design an automatic data collection and annotation pipeline to address this issue, which includes ModelZoo-based Coarse Annotation and LLM-driven Fine Annotation processes. In addition, we share the training tricks such as two-stage training and hard negative sampling. Finally, we conduct a set of offline experiments on a million-scale production dataset to evaluate our approach and deploy an A/B testing in a real online system to verify the performance. Extensive experimental results demonstrate that our proposed approach significantly outperforms existing state-of-the-art baseline methods.
Beyond Line of Sight Defense Communication Systems: Recent Advances and Future Challenges
Dec 11, 2023Beyond Line of Sight (BLOS) communication stands as an indispensable element within defense communication strategies, facilitating information exchange in scenarios where traditional Line of Sight (LOS) methodologies encounter obstruction. This article delves into the forefront of technologies driving BLOS communication, emphasizing advanced systems like phantom networks, nanonetworks, aerial relays, and satellite-based defense communication. Moreover, we present a practical use case of UAV path planning using optimization techniques amidst radar-threat war zones that add concrete relevance, underscoring the tangible applications of BLOS defense communication systems. Additionally, we present several future research directions for BLOS communication in defense systems, such as resilience enhancement, the integration of heterogeneous networks, management of contested spectrums, advancements in multimedia communication, adaptive methodologies, and the burgeoning domain of the Internet of Military Things (IoMT). This exploration of BLOS technologies and their applications lays the groundwork for synergistic collaboration between industry and academia, fostering innovation in defense communication paradigms.
Relevant Intrinsic Feature Enhancement Network for Few-Shot Semantic Segmentation
Dec 11, 2023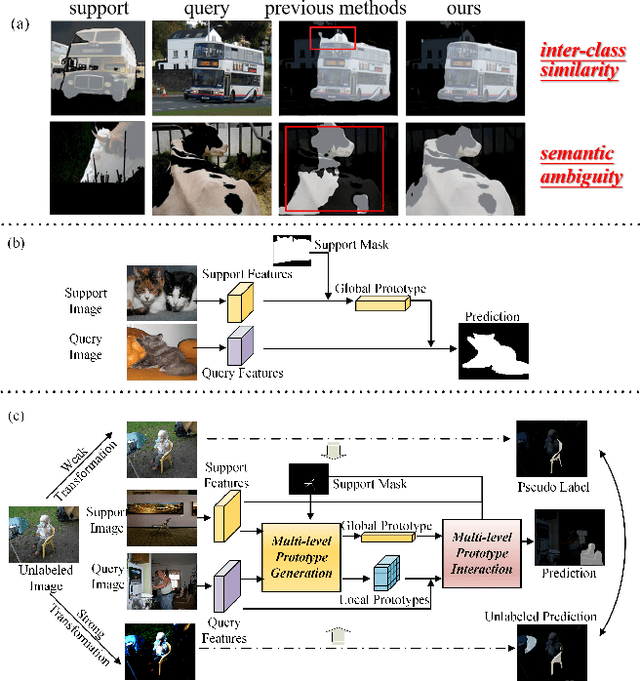
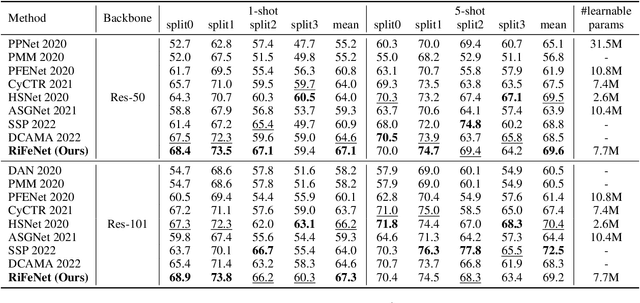
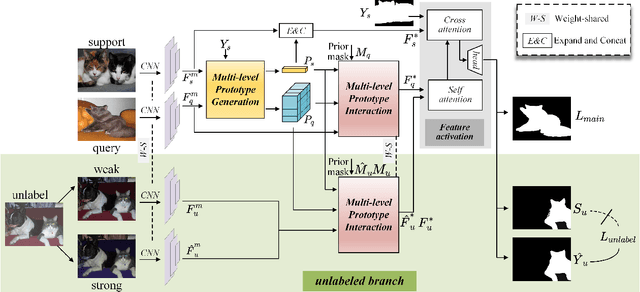
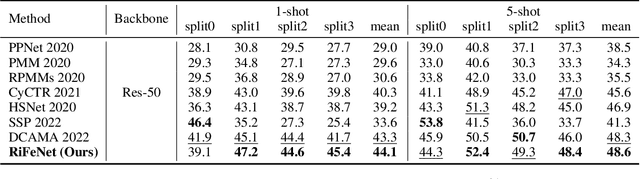
For few-shot semantic segmentation, the primary task is to extract class-specific intrinsic information from limited labeled data. However, the semantic ambiguity and inter-class similarity of previous methods limit the accuracy of pixel-level foreground-background classification. To alleviate these issues, we propose the Relevant Intrinsic Feature Enhancement Network (RiFeNet). To improve the semantic consistency of foreground instances, we propose an unlabeled branch as an efficient data utilization method, which teaches the model how to extract intrinsic features robust to intra-class differences. Notably, during testing, the proposed unlabeled branch is excluded without extra unlabeled data and computation. Furthermore, we extend the inter-class variability between foreground and background by proposing a novel multi-level prototype generation and interaction module. The different-grained complementarity between global and local prototypes allows for better distinction between similar categories. The qualitative and quantitative performance of RiFeNet surpasses the state-of-the-art methods on PASCAL-5i and COCO benchmarks.
TPRNN: A Top-Down Pyramidal Recurrent Neural Network for Time Series Forecasting
Dec 11, 2023Time series refer to a series of data points indexed in time order, which can be found in various fields, e.g., transportation, healthcare, and finance. Accurate time series forecasting can enhance optimization planning and decision-making support. Time series have multi-scale characteristics, i.e., different temporal patterns at different scales, which presents a challenge for time series forecasting. In this paper, we propose TPRNN, a Top-down Pyramidal Recurrent Neural Network for time series forecasting. We first construct subsequences of different scales from the input, forming a pyramid structure. Then by executing a multi-scale information interaction module from top to bottom, we model both the temporal dependencies of each scale and the influences of subsequences of different scales, resulting in a complete modeling of multi-scale temporal patterns in time series. Experiments on seven real-world datasets demonstrate that TPRNN has achieved the state-of-the-art performance with an average improvement of 8.13% in MSE compared to the best baseline.
SemiSAM: Exploring SAM for Enhancing Semi-Supervised Medical Image Segmentation with Extremely Limited Annotations
Dec 11, 2023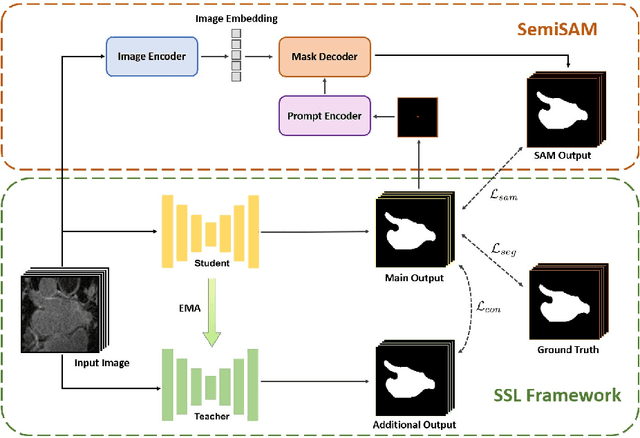
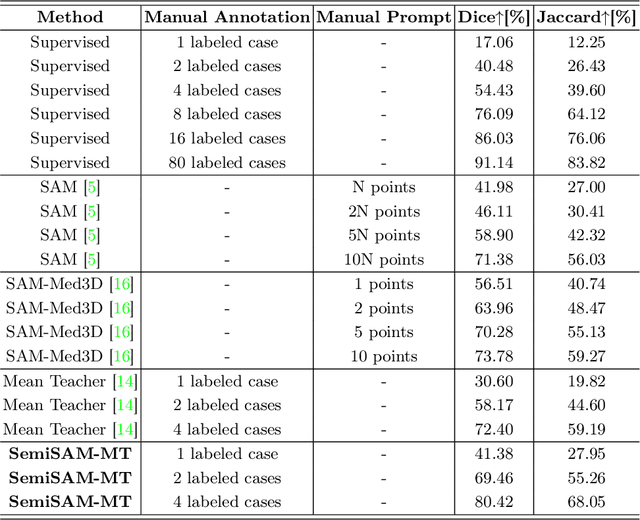
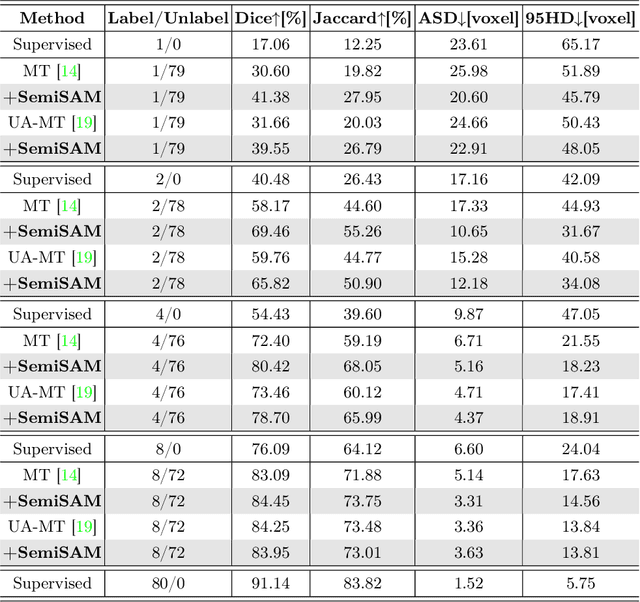
Semi-supervised learning has attracted much attention due to its less dependence on acquiring abundant annotations from experts compared to fully supervised methods, which is especially important for medical image segmentation which typically requires intensive pixel/voxel-wise labeling by domain experts. Although semi-supervised methods can improve the performance by utilizing unlabeled data, there are still gaps between fully supervised methods under extremely limited annotation scenarios. In this paper, we propose a simple yet efficient strategy to explore the usage of the Segment Anything Model (SAM) for enhancing semi-supervised medical image segmentation. Concretely, the segmentation model trained with domain knowledge provides information for localization and generating input prompts to the SAM. Then the generated pseudo-labels of SAM are utilized as additional supervision to assist in the learning procedure of the semi-supervised framework. Experimental results demonstrate that SAM's assistance significantly enhances the performance of existing semi-supervised frameworks, especially when only one or a few labeled images are available.
Decoupling SQL Query Hardness Parsing for Text-to-SQL
Dec 11, 2023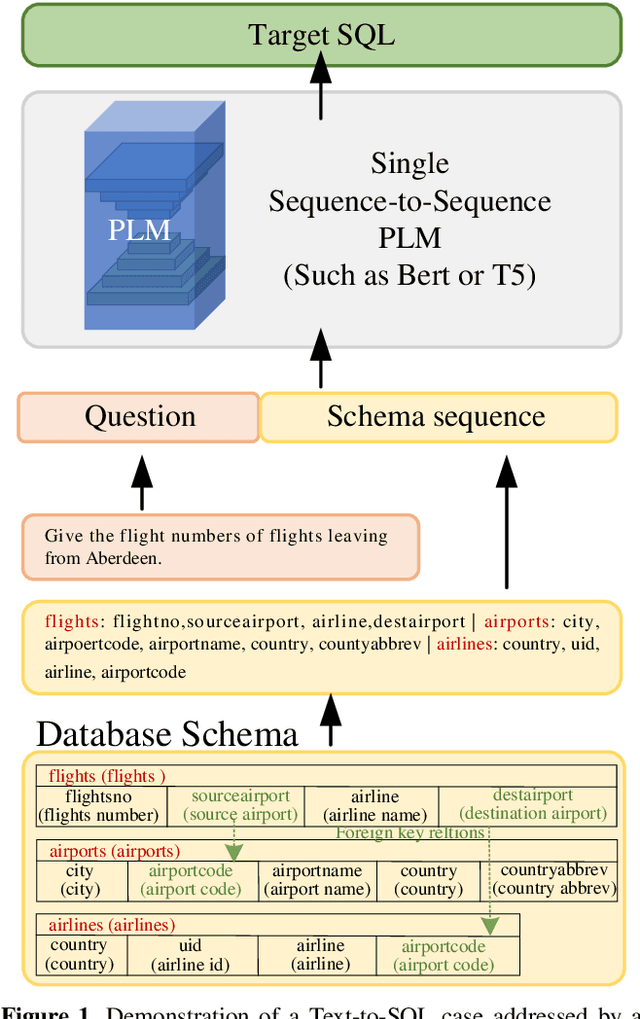


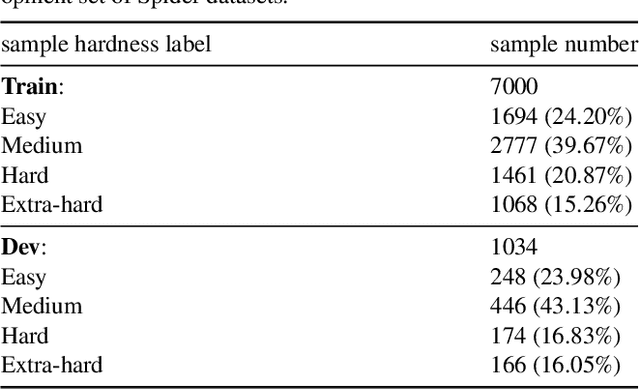
The fundamental goal of the Text-to-SQL task is to translate natural language question into SQL query. Current research primarily emphasizes the information coupling between natural language questions and schemas, and significant progress has been made in this area. The natural language questions as the primary task requirements source determines the hardness of correspond SQL queries, the correlation between the two always be ignored. However, when the correlation between questions and queries was decoupled, it may simplify the task. In this paper, we introduce an innovative framework for Text-to-SQL based on decoupling SQL query hardness parsing. This framework decouples the Text-to-SQL task based on query hardness by analyzing questions and schemas, simplifying the multi-hardness task into a single-hardness challenge. This greatly reduces the parsing pressure on the language model. We evaluate our proposed framework and achieve a new state-of-the-art performance of fine-turning methods on Spider dev.
Oracle Character Recognition using Unsupervised Discriminative Consistency Network
Dec 11, 2023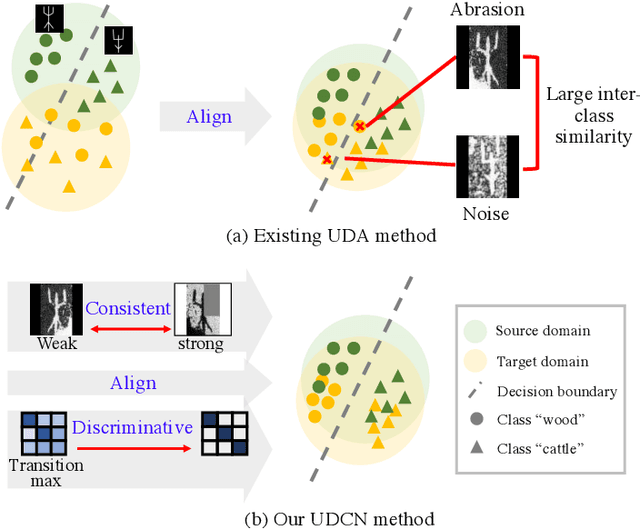
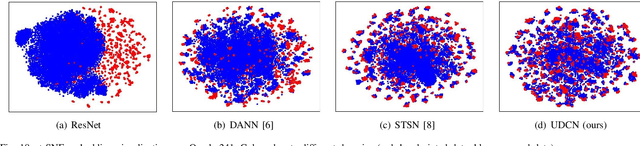
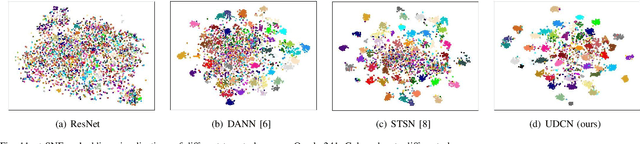

Ancient history relies on the study of ancient characters. However, real-world scanned oracle characters are difficult to collect and annotate, posing a major obstacle for oracle character recognition (OrCR). Besides, serious abrasion and inter-class similarity also make OrCR more challenging. In this paper, we propose a novel unsupervised domain adaptation method for OrCR, which enables to transfer knowledge from labeled handprinted oracle characters to unlabeled scanned data. We leverage pseudo-labeling to incorporate the semantic information into adaptation and constrain augmentation consistency to make the predictions of scanned samples consistent under different perturbations, leading to the model robustness to abrasion, stain and distortion. Simultaneously, an unsupervised transition loss is proposed to learn more discriminative features on the scanned domain by optimizing both between-class and within-class transition probability. Extensive experiments show that our approach achieves state-of-the-art result on Oracle-241 dataset and substantially outperforms the recently proposed structure-texture separation network by 15.1%.
The irruption of cryptocurrencies into Twitter cashtags: a classifying solution
Dec 14, 2023There is a consensus about the good sensing characteristics of Twitter to mine and uncover knowledge in financial markets, being considered a relevant feeder for taking decisions about buying or holding stock shares and even for detecting stock manipulation. Although Twitter hashtags allow to aggregate topic-related content, a specific mechanism for financial information also exists: Cashtag. However, the irruption of cryptocurrencies has resulted in a significant degradation on the cashtag-based aggregation of posts. Unfortunately, Twitter' users may use homonym tickers to refer to cryptocurrencies and to companies in stock markets, which means that filtering by cashtag may result on both posts referring to stock companies and cryptocurrencies. This research proposes automated classifiers to distinguish conflicting cashtags and, so, their container tweets by analyzing the distinctive features of tweets referring to stock companies and cryptocurrencies. As experiment, this paper analyses the interference between cryptocurrencies and company tickers in the London Stock Exchange (LSE), specifically, companies in the main and alternative market indices FTSE-100 and AIM-100. Heuristic-based as well as supervised classifiers are proposed and their advantages and drawbacks, including their ability to self-adapt to Twitter usage changes, are discussed. The experiment confirms a significant distortion in collected data when colliding or homonym cashtags exist, i.e., the same \$ acronym to refer to company tickers and cryptocurrencies. According to our results, the distinctive features of posts including cryptocurrencies or company tickers support accurate classification of colliding tweets (homonym cashtags) and Independent Models, as the most detached classifiers from training data, have the potential to be trans-applicability (in different stock markets) while retaining performance.