 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-learning Canonical Space for Multi-view 3D Human Pose Estimation
Mar 29, 2024
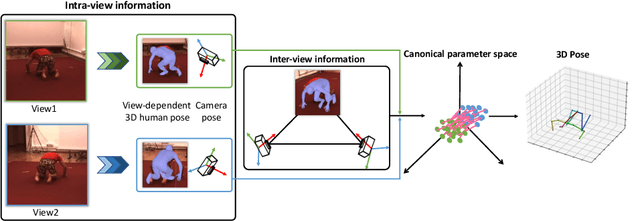
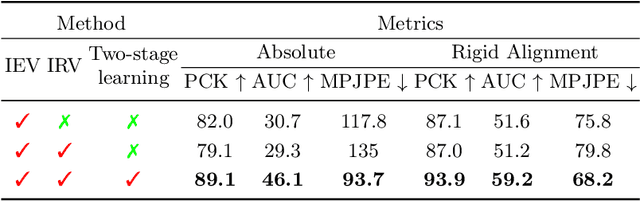
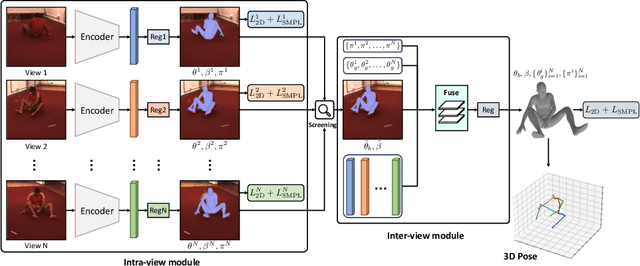
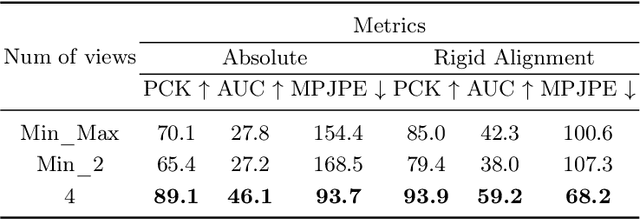
Multi-view 3D human pose estimation is naturally superior to single view one, benefiting from more comprehensive information provided by images of multiple views. The information includes camera poses, 2D/3D human poses, and 3D geometry. However, the accurate annotation of these information is hard to obtain, making it challenging to predict accurate 3D human pose from multi-view images. To deal with this issue, we propose a fully self-supervised framework, named cascaded multi-view aggregating network (CMANet), to construct a canonical parameter space to holistically integrate and exploit multi-view information. In our framework, the multi-view information is grouped into two categories: 1) intra-view information , 2) inter-view information. Accordingly, CMANet consists of two components: intra-view module (IRV) and inter-view module (IEV). IRV is used for extracting initial camera pose and 3D human pose of each view; IEV is to fuse complementary pose information and cross-view 3D geometry for a final 3D human pose. To facilitate the aggregation of the intra- and inter-view, we define a canonical parameter space, depicted by per-view camera pose and human pose and shape parameters ($\theta$ and $\beta$) of SMPL model, and propose a two-stage learning procedure. At first stage, IRV learns to estimate camera pose and view-dependent 3D human pose supervised by confident output of an off-the-shelf 2D keypoint detector. At second stage, IRV is frozen and IEV further refines the camera pose and optimizes the 3D human pose by implicitly encoding the cross-view complement and 3D geometry constraint, achieved by jointly fitting predicted multi-view 2D keypoints. The proposed framework, modules, and learning strategy are demonstrated to be effective by comprehensive experiments and CMANet is superior to state-of-the-art methods in extensive quantitative and qualitative analysis.
Ego-Motion Aware Target Prediction Module for Robust Multi-Object Tracking
Apr 03, 2024Multi-object tracking (MOT) is a prominent task in computer vision with application in autonomous driving, responsible for the simultaneous tracking of multiple object trajectories. Detection-based multi-object tracking (DBT) algorithms detect objects using an independent object detector and predict the imminent location of each target. Conventional prediction methods in DBT utilize Kalman Filter(KF) to extrapolate the target location in the upcoming frames by supposing a constant velocity motion model. These methods are especially hindered in autonomous driving applications due to dramatic camera motion or unavailable detections. Such limitations lead to tracking failures manifested by numerous identity switches and disrupted trajectories. In this paper, we introduce a novel KF-based prediction module called the Ego-motion Aware Target Prediction (EMAP) module by focusing on the integration of camera motion and depth information with object motion models. Our proposed method decouples the impact of camera rotational and translational velocity from the object trajectories by reformulating the Kalman Filter. This reformulation enables us to reject the disturbances caused by camera motion and maximizes the reliability of the object motion model. We integrate our module with four state-of-the-art base MOT algorithms, namely OC-SORT, Deep OC-SORT, ByteTrack, and BoT-SORT. In particular, our evaluation on the KITTI MOT dataset demonstrates that EMAP remarkably drops the number of identity switches (IDSW) of OC-SORT and Deep OC-SORT by 73% and 21%, respectively. At the same time, it elevates other performance metrics such as HOTA by more than 5%. Our source code is available at https://github.com/noyzzz/EMAP.
RESSA: Repair Sparse Vision-Language Models via Sparse Cross-Modality Adaptation
Apr 03, 2024Vision-Language Models (VLMs), integrating diverse information from multiple modalities, have shown remarkable success across various tasks. However, deploying VLMs, comprising large-scale vision and language models poses challenges in resource-constrained scenarios. While pruning followed by finetuning offers a potential solution to maintain performance with smaller model sizes, its application to VLMs remains relatively unexplored, presenting two main questions: how to distribute sparsity across different modality-specific models, and how to repair the performance of pruned sparse VLMs. To answer the first question, we conducted preliminary studies on VLM pruning and found that pruning vision models and language models with the same sparsity ratios contribute to nearly optimal performance. For the second question, unlike finetuning unimodal sparse models, sparse VLMs involve cross-modality interactions, requiring specialized techniques for post-pruning performance repair. Moreover, while parameter-efficient LoRA finetuning has been proposed to repair the performance of sparse models, a significant challenge of weights merging arises due to the incompatibility of dense LoRA modules with sparse models that destroy the sparsity of pruned models. To tackle these challenges, we propose to Repair Sparse Vision-Language Models via Sparse Cross-modality Adaptation (RESSA). RESSA utilizes cross-modality finetuning to enhance task-specific performance and facilitate knowledge distillation from original dense models. Additionally, we introduce SparseLoRA, which applies sparsity directly to LoRA weights, enabling seamless integration with sparse models. Our experimental results validate the effectiveness of RESSA, showcasing significant enhancements, such as an 11.3\% improvement under 2:4 sparsity and a remarkable 47.6\% enhancement under unstructured 70\% sparsity.
CAAP: Class-Dependent Automatic Data Augmentation Based On Adaptive Policies For Time Series
Apr 01, 2024Data Augmentation is a common technique used to enhance the performance of deep learning models by expanding the training dataset. Automatic Data Augmentation (ADA) methods are getting popular because of their capacity to generate policies for various datasets. However, existing ADA methods primarily focused on overall performance improvement, neglecting the problem of class-dependent bias that leads to performance reduction in specific classes. This bias poses significant challenges when deploying models in real-world applications. Furthermore, ADA for time series remains an underexplored domain, highlighting the need for advancements in this field. In particular, applying ADA techniques to vital signals like an electrocardiogram (ECG) is a compelling example due to its potential in medical domains such as heart disease diagnostics. We propose a novel deep learning-based approach called Class-dependent Automatic Adaptive Policies (CAAP) framework to overcome the notable class-dependent bias problem while maintaining the overall improvement in time-series data augmentation. Specifically, we utilize the policy network to generate effective sample-wise policies with balanced difficulty through class and feature information extraction. Second, we design the augmentation probability regulation method to minimize class-dependent bias. Third, we introduce the information region concepts into the ADA framework to preserve essential regions in the sample. Through a series of experiments on real-world ECG datasets, we demonstrate that CAAP outperforms representative methods in achieving lower class-dependent bias combined with superior overall performance. These results highlight the reliability of CAAP as a promising ADA method for time series modeling that fits for the demands of real-world applications.
ECoDepth: Effective Conditioning of Diffusion Models for Monocular Depth Estimation
Apr 01, 2024In the absence of parallax cues, a learning-based single image depth estimation (SIDE) model relies heavily on shading and contextual cues in the image. While this simplicity is attractive, it is necessary to train such models on large and varied datasets, which are difficult to capture. It has been shown that using embeddings from pre-trained foundational models, such as CLIP, improves zero shot transfer in several applications. Taking inspiration from this, in our paper we explore the use of global image priors generated from a pre-trained ViT model to provide more detailed contextual information. We argue that the embedding vector from a ViT model, pre-trained on a large dataset, captures greater relevant information for SIDE than the usual route of generating pseudo image captions, followed by CLIP based text embeddings. Based on this idea, we propose a new SIDE model using a diffusion backbone which is conditioned on ViT embeddings. Our proposed design establishes a new state-of-the-art (SOTA) for SIDE on NYUv2 dataset, achieving Abs Rel error of 0.059(14% improvement) compared to 0.069 by the current SOTA (VPD). And on KITTI dataset, achieving Sq Rel error of 0.139 (2% improvement) compared to 0.142 by the current SOTA (GEDepth). For zero-shot transfer with a model trained on NYUv2, we report mean relative improvement of (20%, 23%, 81%, 25%) over NeWCRFs on (Sun-RGBD, iBims1, DIODE, HyperSim) datasets, compared to (16%, 18%, 45%, 9%) by ZoeDepth. The project page is available at https://ecodepth-iitd.github.io
MosquitoFusion: A Multiclass Dataset for Real-Time Detection of Mosquitoes, Swarms, and Breeding Sites Using Deep Learning
Apr 01, 2024In this paper, we present an integrated approach to real-time mosquito detection using our multiclass dataset (MosquitoFusion) containing 1204 diverse images and leverage cutting-edge technologies, specifically computer vision, to automate the identification of Mosquitoes, Swarms, and Breeding Sites. The pre-trained YOLOv8 model, trained on this dataset, achieved a mean Average Precision (mAP@50) of 57.1%, with precision at 73.4% and recall at 50.5%. The integration of Geographic Information Systems (GIS) further enriches the depth of our analysis, providing valuable insights into spatial patterns. The dataset and code are available at https://github.com/faiyazabdullah/MosquitoFusion.
ASAP: Interpretable Analysis and Summarization of AI-generated Image Patterns at Scale
Apr 03, 2024Generative image models have emerged as a promising technology to produce realistic images. Despite potential benefits, concerns grow about its misuse, particularly in generating deceptive images that could raise significant ethical, legal, and societal issues. Consequently, there is growing demand to empower users to effectively discern and comprehend patterns of AI-generated images. To this end, we developed ASAP, an interactive visualization system that automatically extracts distinct patterns of AI-generated images and allows users to interactively explore them via various views. To uncover fake patterns, ASAP introduces a novel image encoder, adapted from CLIP, which transforms images into compact "distilled" representations, enriched with information for differentiating authentic and fake images. These representations generate gradients that propagate back to the attention maps of CLIP's transformer block. This process quantifies the relative importance of each pixel to image authenticity or fakeness, exposing key deceptive patterns. ASAP enables the at scale interactive analysis of these patterns through multiple, coordinated visualizations. This includes a representation overview with innovative cell glyphs to aid in the exploration and qualitative evaluation of fake patterns across a vast array of images, as well as a pattern view that displays authenticity-indicating patterns in images and quantifies their impact. ASAP supports the analysis of cutting-edge generative models with the latest architectures, including GAN-based models like proGAN and diffusion models like the latent diffusion model. We demonstrate ASAP's usefulness through two usage scenarios using multiple fake image detection benchmark datasets, revealing its ability to identify and understand hidden patterns in AI-generated images, especially in detecting fake human faces produced by diffusion-based techniques.
Energy-Optimized Planning in Non-Uniform Wind Fields with Fixed-Wing Aerial Vehicles
Apr 02, 2024Fixed-wing small uncrewed aerial vehicles (sUAVs) possess the capability to remain airborne for extended durations and traverse vast distances. However, their operation is susceptible to wind conditions, particularly in regions of complex terrain where high wind speeds may push the aircraft beyond its operational limitations, potentially raising safety concerns. Moreover, wind impacts the energy required to follow a path, especially in locations where the wind direction and speed are not favorable. Incorporating wind information into mission planning is essential to ensure both safety and energy efficiency. In this paper, we propose a sampling-based planner using the kinematic Dubins aircraft paths with respect to the ground, to plan energy-efficient paths in non-uniform wind fields. We study the planner characteristics with synthetic and real-world wind data and compare its performance against baseline cost and path formulations. We demonstrate that the energy-optimized planner effectively utilizes updrafts to minimize energy consumption, albeit at the expense of increased travel time. The ground-relative path formulation facilitates the generation of safe trajectories onboard sUAVs within reasonable computational timeframes.
Event-assisted Low-Light Video Object Segmentation
Apr 02, 2024In the realm of video object segmentation (VOS), the challenge of operating under low-light conditions persists, resulting in notably degraded image quality and compromised accuracy when comparing query and memory frames for similarity computation. Event cameras, characterized by their high dynamic range and ability to capture motion information of objects, offer promise in enhancing object visibility and aiding VOS methods under such low-light conditions. This paper introduces a pioneering framework tailored for low-light VOS, leveraging event camera data to elevate segmentation accuracy. Our approach hinges on two pivotal components: the Adaptive Cross-Modal Fusion (ACMF) module, aimed at extracting pertinent features while fusing image and event modalities to mitigate noise interference, and the Event-Guided Memory Matching (EGMM) module, designed to rectify the issue of inaccurate matching prevalent in low-light settings. Additionally, we present the creation of a synthetic LLE-DAVIS dataset and the curation of a real-world LLE-VOS dataset, encompassing frames and events. Experimental evaluations corroborate the efficacy of our method across both datasets, affirming its effectiveness in low-light scenarios.
LastResort at SemEval-2024 Task 3: Exploring Multimodal Emotion Cause Pair Extraction as Sequence Labelling Task
Apr 02, 2024Conversation is the most natural form of human communication, where each utterance can range over a variety of possible emotions. While significant work has been done towards the detection of emotions in text, relatively little work has been done towards finding the cause of the said emotions, especially in multimodal settings. SemEval 2024 introduces the task of Multimodal Emotion Cause Analysis in Conversations, which aims to extract emotions reflected in individual utterances in a conversation involving multiple modalities (textual, audio, and visual modalities) along with the corresponding utterances that were the cause for the emotion. In this paper, we propose models that tackle this task as an utterance labeling and a sequence labeling problem and perform a comparative study of these models, involving baselines using different encoders, using BiLSTM for adding contextual information of the conversation, and finally adding a CRF layer to try to model the inter-dependencies between adjacent utterances more effectively. In the official leaderboard for the task, our architecture was ranked 8th, achieving an F1-score of 0.1759 on the leaderboard.