 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
General Object Foundation Model for Images and Videos at Scale
Dec 14, 2023
We present GLEE in this work, an object-level foundation model for locating and identifying objects in images and videos. Through a unified framework, GLEE accomplishes detection, segmentation, tracking, grounding, and identification of arbitrary objects in the open world scenario for various object perception tasks. Adopting a cohesive learning strategy, GLEE acquires knowledge from diverse data sources with varying supervision levels to formulate general object representations, excelling in zero-shot transfer to new data and tasks. Specifically, we employ an image encoder, text encoder, and visual prompter to handle multi-modal inputs, enabling to simultaneously solve various object-centric downstream tasks while maintaining state-of-the-art performance. Demonstrated through extensive training on over five million images from diverse benchmarks, GLEE exhibits remarkable versatility and improved generalization performance, efficiently tackling downstream tasks without the need for task-specific adaptation. By integrating large volumes of automatically labeled data, we further enhance its zero-shot generalization capabilities. Additionally, GLEE is capable of being integrated into Large Language Models, serving as a foundational model to provide universal object-level information for multi-modal tasks. We hope that the versatility and universality of our method will mark a significant step in the development of efficient visual foundation models for AGI systems. The model and code will be released at https://glee-vision.github.io .
Local Conditional Controlling for Text-to-Image Diffusion Models
Dec 14, 2023Diffusion models have exhibited impressive prowess in the text-to-image task. Recent methods add image-level controls, e.g., edge and depth maps, to manipulate the generation process together with text prompts to obtain desired images. This controlling process is globally operated on the entire image, which limits the flexibility of control regions. In this paper, we introduce a new simple yet practical task setting: local control. It focuses on controlling specific local areas according to user-defined image conditions, where the rest areas are only conditioned by the original text prompt. This manner allows the users to flexibly control the image generation in a fine-grained way. However, it is non-trivial to achieve this goal. The naive manner of directly adding local conditions may lead to the local control dominance problem. To mitigate this problem, we propose a training-free method that leverages the updates of noised latents and parameters in the cross-attention map during the denosing process to promote concept generation in non-control areas. Moreover, we use feature mask constraints to mitigate the degradation of synthesized image quality caused by information differences inside and outside the local control area. Extensive experiments demonstrate that our method can synthesize high-quality images to the prompt under local control conditions. Code is available at https://github.com/YibooZhao/Local-Control.
Factorization Vision Transformer: Modeling Long Range Dependency with Local Window Cost
Dec 14, 2023Transformers have astounding representational power but typically consume considerable computation which is quadratic with image resolution. The prevailing Swin transformer reduces computational costs through a local window strategy. However, this strategy inevitably causes two drawbacks: (1) the local window-based self-attention hinders global dependency modeling capability; (2) recent studies point out that local windows impair robustness. To overcome these challenges, we pursue a preferable trade-off between computational cost and performance. Accordingly, we propose a novel factorization self-attention mechanism (FaSA) that enjoys both the advantages of local window cost and long-range dependency modeling capability. By factorizing the conventional attention matrix into sparse sub-attention matrices, FaSA captures long-range dependencies while aggregating mixed-grained information at a computational cost equivalent to the local window-based self-attention. Leveraging FaSA, we present the factorization vision transformer (FaViT) with a hierarchical structure. FaViT achieves high performance and robustness, with linear computational complexity concerning input image spatial resolution. Extensive experiments have shown FaViT's advanced performance in classification and downstream tasks. Furthermore, it also exhibits strong model robustness to corrupted and biased data and hence demonstrates benefits in favor of practical applications. In comparison to the baseline model Swin-T, our FaViT-B2 significantly improves classification accuracy by 1% and robustness by 7%, while reducing model parameters by 14%. Our code will soon be publicly available at https://github.com/q2479036243/FaViT.
Proportional Representation in Metric Spaces and Low-Distortion Committee Selection
Dec 16, 2023We introduce a novel definition for a small set R of k points being "representative" of a larger set in a metric space. Given a set V (e.g., documents or voters) to represent, and a set C of possible representatives, our criterion requires that for any subset S comprising a theta fraction of V, the average distance of S to their best theta*k points in R should not be more than a factor gamma compared to their average distance to the best theta*k points among all of C. This definition is a strengthening of proportional fairness and core fairness, but - different from those notions - requires that large cohesive clusters be represented proportionally to their size. Since there are instances for which - unless gamma is polynomially large - no solutions exist, we study this notion in a resource augmentation framework, implicitly stating the constraints for a set R of size k as though its size were only k/alpha, for alpha > 1. Furthermore, motivated by the application to elections, we mostly focus on the "ordinal" model, where the algorithm does not learn the actual distances; instead, it learns only for each point v in V and each candidate pairs c, c' which of c, c' is closer to v. Our main result is that the Expanding Approvals Rule (EAR) of Aziz and Lee is (alpha, gamma) representative with gamma <= 1 + 6.71 * (alpha)/(alpha-1). Our results lead to three notable byproducts. First, we show that the EAR achieves constant proportional fairness in the ordinal model, giving the first positive result on metric proportional fairness with ordinal information. Second, we show that for the core fairness objective, the EAR achieves the same asymptotic tradeoff between resource augmentation and approximation as the recent results of Li et al., which used full knowledge of the metric. Finally, our results imply a very simple single-winner voting rule with metric distortion at most 44.
Virtual Quantum Markov Chains
Dec 04, 2023Quantum Markov chains generalize classical Markov chains for random variables to the quantum realm and exhibit unique inherent properties, making them an important feature in quantum information theory. In this work, we propose the concept of virtual quantum Markov chains (VQMCs), focusing on scenarios where subsystems retain classical information about global systems from measurement statistics. As a generalization of quantum Markov chains, VQMCs characterize states where arbitrary global shadow information can be recovered from subsystems through local quantum operations and measurements. We present an algebraic characterization for virtual quantum Markov chains and show that the virtual quantum recovery is fully determined by the block matrices of a quantum state on its subsystems. Notably, we find a distinction between two classes of tripartite entanglement by showing that the W state is a VQMC while the GHZ state is not. Furthermore, we establish semidefinite programs to determine the optimal sampling overhead and the robustness of virtual quantum Markov chains. We demonstrate the optimal sampling overhead is additive, indicating no free lunch to further reduce the sampling cost of recovery from parallel calls of the VQMC states. Our findings elucidate distinctions between quantum Markov chains and virtual quantum Markov chains, extending our understanding of quantum recovery to scenarios prioritizing classical information from measurement statistics.
All Rivers Run to the Sea: Private Learning with Asymmetric Flows
Dec 05, 2023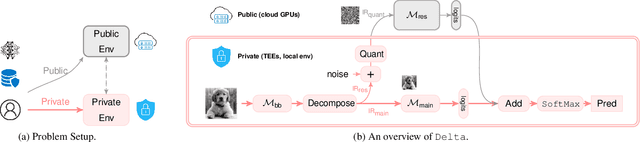

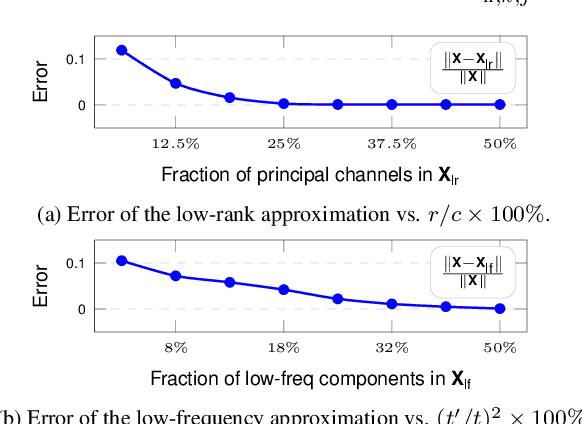

Data privacy is of great concern in cloud machine-learning service platforms, when sensitive data are exposed to service providers. While private computing environments (e.g., secure enclaves), and cryptographic approaches (e.g., homomorphic encryption) provide strong privacy protection, their computing performance still falls short compared to cloud GPUs. To achieve privacy protection with high computing performance, we propose Delta, a new private training and inference framework, with comparable model performance as non-private centralized training. Delta features two asymmetric data flows: the main information-sensitive flow and the residual flow. The main part flows into a small model while the residuals are offloaded to a large model. Specifically, Delta embeds the information-sensitive representations into a low-dimensional space while pushing the information-insensitive part into high-dimension residuals. To ensure privacy protection, the low-dimensional information-sensitive part is secured and fed to a small model in a private environment. On the other hand, the residual part is sent to fast cloud GPUs, and processed by a large model. To further enhance privacy and reduce the communication cost, Delta applies a random binary quantization technique along with a DP-based technique to the residuals before sharing them with the public platform. We theoretically show that Delta guarantees differential privacy in the public environment and greatly reduces the complexity in the private environment. We conduct empirical analyses on CIFAR-10, CIFAR-100 and ImageNet datasets and ResNet-18 and ResNet-34, showing that Delta achieves strong privacy protection, fast training, and inference without significantly compromising the model utility.
Deep Learning Enabled Semantic Communication Systems for Video Transmission
Dec 08, 2023Semantic communication has emerged as a promising approach for improving efficient transmission in the next generation of wireless networks. Inspired by the success of semantic communication in different areas, we aim to provide a new semantic communication scheme from the semantic level. In this paper, we propose a novel DL-based semantic communication system for video transmission, which compacts semantic-related information to improve transmission efficiency. In particular, we utilize the Bi-optical flow to estimate residual information of inter-frame details. We also propose a feature choice module and a feature fusion module to drop semantically redundant features while paying more attention to the important semantic-related content. We employ a frame prediction module to reconstruct semantic features of the prediction frame from the received signal at the receiver. To enhance the system's robustness, we propose a noise attention module that assigns different importance weights to the extracted features. Simulation results indicate that our proposed method outperforms existing approaches in terms of transmission efficiency, achieving about 33.3\% reduction in the number of transmitted symbols while improving the peak signal-to-noise ratio (PSNR) performance by an average of 0.56dB.
Empirical Validation of Conformal Prediction for Trustworthy Skin Lesions Classification
Dec 12, 2023Uncertainty quantification is a pivotal field that contributes to the realization of reliable and robust systems. By providing complementary information, it becomes instrumental in fortifying safe decisions, particularly within high-risk applications. Nevertheless, a comprehensive understanding of the advantages and limitations inherent in various methods within the medical imaging field necessitates further research coupled with in-depth analysis. In this paper, we explore Conformal Prediction, an emerging distribution-free uncertainty quantification technique, along with Monte Carlo Dropout and Evidential Deep Learning methods. Our comprehensive experiments provide a comparative performance analysis for skin lesion classification tasks across the three quantification methods. Furthermore, We present insights into the effectiveness of each method in handling Out-of-Distribution samples from domain-shifted datasets. Based on our experimental findings, our conclusion highlights the robustness and consistent performance of conformal prediction across diverse conditions. This positions it as the preferred choice for decision-making in safety-critical applications.
MMICT: Boosting Multi-Modal Fine-Tuning with In-Context Examples
Dec 12, 2023Although In-Context Learning (ICL) brings remarkable performance gains to Large Language Models (LLMs), the improvements remain lower than fine-tuning on downstream tasks. This paper introduces Multi-Modal In-Context Tuning (MMICT), a novel multi-modal fine-tuning paradigm that boosts multi-modal fine-tuning by fully leveraging the promising ICL capability of multi-modal LLMs (MM-LLMs). We propose the Multi-Modal Hub (M-Hub), a unified module that captures various multi-modal features according to different inputs and objectives. Based on M-Hub, MMICT enables MM-LLMs to learn from in-context visual-guided textual features and subsequently generate outputs conditioned on the textual-guided visual features. Moreover, leveraging the flexibility of M-Hub, we design a variety of in-context demonstrations. Extensive experiments on a diverse range of downstream multi-modal tasks demonstrate that MMICT significantly outperforms traditional fine-tuning strategy and the vanilla ICT method that directly takes the concatenation of all information from different modalities as input.
From Knowledge Representation to Knowledge Organization and Back
Dec 12, 2023Knowledge Representation (KR) and facet-analytical Knowledge Organization (KO) have been the two most prominent methodologies of data and knowledge modelling in the Artificial Intelligence community and the Information Science community, respectively. KR boasts of a robust and scalable ecosystem of technologies to support knowledge modelling while, often, underemphasizing the quality of its models (and model-based data). KO, on the other hand, is less technology-driven but has developed a robust framework of guiding principles (canons) for ensuring modelling (and model-based data) quality. This paper elucidates both the KR and facet-analytical KO methodologies in detail and provides a functional mapping between them. Out of the mapping, the paper proposes an integrated KO-enriched KR methodology with all the standard components of a KR methodology plus the guiding canons of modelling quality provided by KO. The practical benefits of the methodological integration has been exemplified through a prominent case study of KR-based image annotation exercise.