 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SAM-Assisted Remote Sensing Imagery Semantic Segmentation with Object and Boundary Constraints
Dec 05, 2023
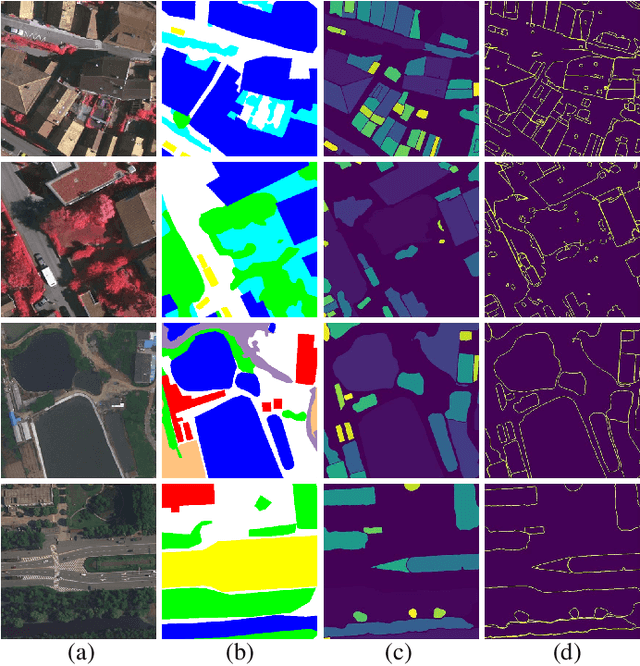
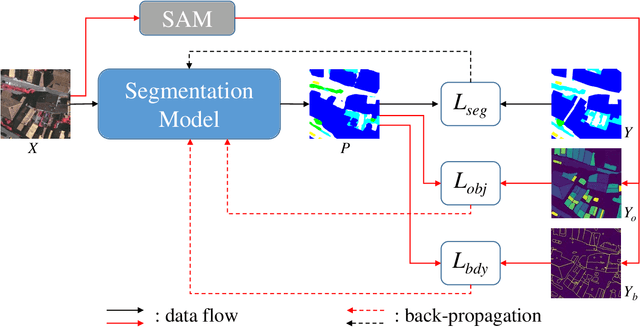

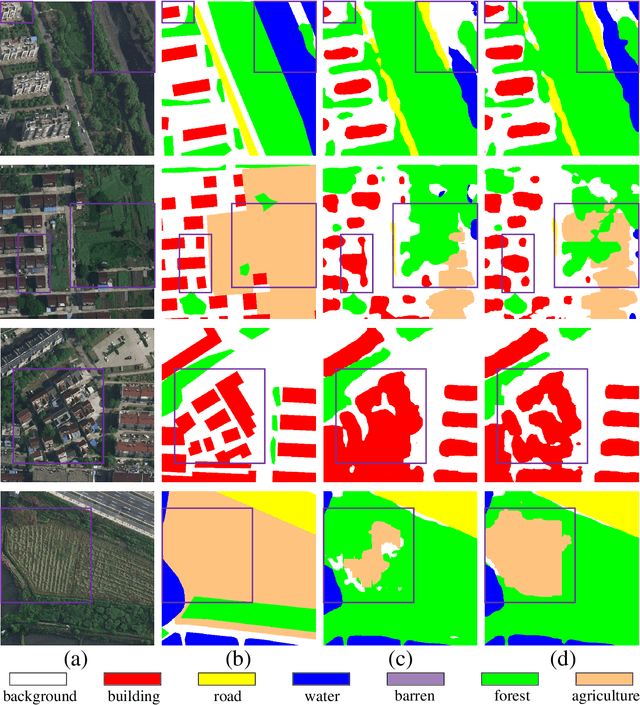
Semantic segmentation of remote sensing imagery plays a pivotal role in extracting precise information for diverse down-stream applications. Recent development of the Segment Anything Model (SAM), an advanced general-purpose segmentation model, has revolutionized this field, presenting new avenues for accurate and efficient segmentation. However, SAM is limited to generating segmentation results without class information. Consequently, the utilization of such a powerful general vision model for semantic segmentation in remote sensing images has become a focal point of research. In this paper, we present a streamlined framework aimed at leveraging the raw output of SAM by exploiting two novel concepts called SAM-Generated Object (SGO) and SAM-Generated Boundary (SGB). More specifically, we propose a novel object loss and further introduce a boundary loss as augmentative components to aid in model optimization in a general semantic segmentation framework. Taking into account the content characteristics of SGO, we introduce the concept of object consistency to leverage segmented regions lacking semantic information. By imposing constraints on the consistency of predicted values within objects, the object loss aims to enhance semantic segmentation performance. Furthermore, the boundary loss capitalizes on the distinctive features of SGB by directing the model's attention to the boundary information of the object. Experimental results on two well-known datasets, namely ISPRS Vaihingen and LoveDA Urban, demonstrate the effectiveness of our proposed method. The source code for this work will be accessible at https://github.com/sstary/SSRS.
Robust End-to-End Diarization with Domain Adaptive Training and Multi-Task Learning
Dec 12, 2023Due to the scarcity of publicly available diarization data, the model performance can be improved by training a single model with data from different domains. In this work, we propose to incorporate domain information to train a single end-to-end diarization model for multiple domains. First, we employ domain adaptive training with parameter-efficient adapters for on-the-fly model reconfiguration. Second, we introduce an auxiliary domain classification task to make the diarization model more domain-aware. For seen domains, the combination of our proposed methods reduces the absolute DER from 17.66% to 16.59% when compared with the baseline. During inference, adapters from ground-truth domains are not available for unseen domains. We demonstrate our model exhibits a stronger generalizability to unseen domains when adapters are removed. For two unseen domains, this improves the DER performance from 39.91% to 23.09% and 25.32% to 18.76% over the baseline, respectively.
CSI-Based Cross-Domain Activity Recognition via Zero-Shot Prototypical Networks
Dec 12, 2023The cross-domain capability of wireless sensing is currently one of the major challenges on human activity recognition (HAR) based on the channel state information (CSI) of wireless signals. The difficulty of labeling samples from new domains has encouraged the use of few and zero shot strategies. In this context, prototype networks have attracted attention due to their reasonable cross-domain transferability. This paper presents a novel zero-shot prototype recurrent convolutional network that implements a zero-shot learning strategy for HAR via CSI. This method extracts the prototypes from an available source domain to classify unseen and unlabeled data from the target domain for the same or similar classes. The experiments have been developed using three datasets with real measurements, and the results include an inter-datasets evaluation. Overall, the results improve the state of the art and make it a promising solution for cross-domain HAR.
Adversarial Estimation of Topological Dimension with Harmonic Score Maps
Dec 11, 2023Quantification of the number of variables needed to locally explain complex data is often the first step to better understanding it. Existing techniques from intrinsic dimension estimation leverage statistical models to glean this information from samples within a neighborhood. However, existing methods often rely on well-picked hyperparameters and ample data as manifold dimension and curvature increases. Leveraging insight into the fixed point of the score matching objective as the score map is regularized by its Dirichlet energy, we show that it is possible to retrieve the topological dimension of the manifold learned by the score map. We then introduce a novel method to measure the learned manifold's topological dimension (i.e., local intrinsic dimension) using adversarial attacks, thereby generating useful interpretations of the learned manifold.
Foundational propositions of hesitant fuzzy sets and parameter reductions of hesitant fuzzy information systems
Nov 07, 2023Hesitant fuzzy sets are widely used in the instances of uncertainty and hesitation. The inclusion relationship is an important and foundational definition for sets. Hesitant fuzzy set, as a kind of set, needs explicit definition of inclusion relationship. Base on the hesitant fuzzy membership degree of discrete form, several kinds of inclusion relationships for hesitant fuzzy sets are proposed. And then some foundational propositions of hesitant fuzzy sets and the families of hesitant fuzzy sets are presented. Finally, some foundational propositions of hesitant fuzzy information systems with respect to parameter reductions are put forward, and an example and an algorithm are given to illustrate the processes of parameter reductions.
Arabic Mini-ClimateGPT : A Climate Change and Sustainability Tailored Arabic LLM
Dec 14, 2023

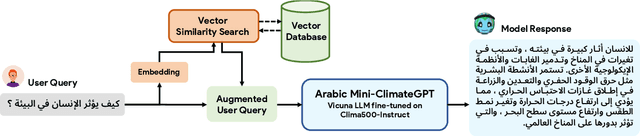
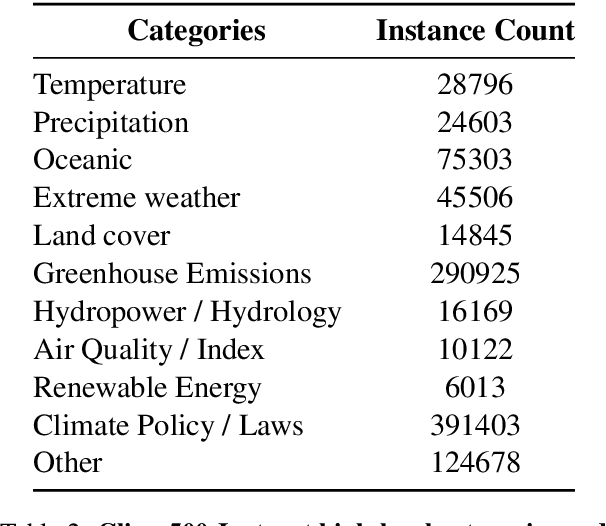
Climate change is one of the most significant challenges we face together as a society. Creating awareness and educating policy makers the wide-ranging impact of climate change is an essential step towards a sustainable future. Recently, Large Language Models (LLMs) like ChatGPT and Bard have shown impressive conversational abilities and excel in a wide variety of NLP tasks. While these models are close-source, recently alternative open-source LLMs such as Stanford Alpaca and Vicuna have shown promising results. However, these open-source models are not specifically tailored for climate related domain specific information and also struggle to generate meaningful responses in other languages such as, Arabic. To this end, we propose a light-weight Arabic Mini-ClimateGPT that is built on an open-source LLM and is specifically fine-tuned on a conversational-style instruction tuning curated Arabic dataset Clima500-Instruct with over 500k instructions about climate change and sustainability. Further, our model also utilizes a vector embedding based retrieval mechanism during inference. We validate our proposed model through quantitative and qualitative evaluations on climate-related queries. Our model surpasses the baseline LLM in 88.3% of cases during ChatGPT-based evaluation. Furthermore, our human expert evaluation reveals an 81.6% preference for our model's responses over multiple popular open-source models. Our open-source demos, code-base and models are available here https://github.com/mbzuai-oryx/ClimateGPT.
* Accepted to EMNLP 2023 (Findings)
Entity-Augmented Code Generation
Dec 14, 2023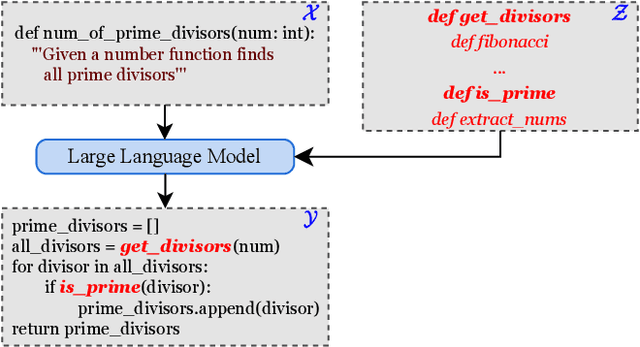
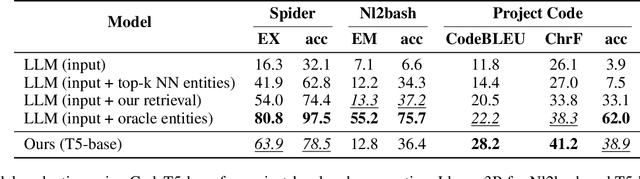

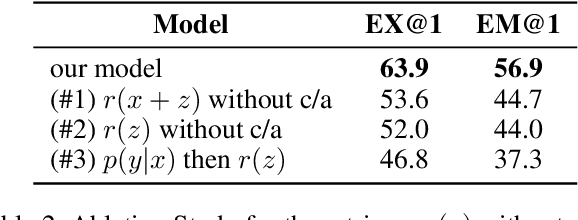
The current state-of-the-art large language models (LLMs) are effective in generating high-quality text and encapsulating a broad spectrum of world knowledge. However, these models often hallucinate during generation and are not designed to utilize external information sources. To enable requests to the external knowledge bases, also called knowledge grounding, retrieval-augmented LLMs were introduced. For now, their applications have largely involved Open Domain Question Answering, Abstractive Question Answering, and such. In this paper, we broaden the scope of retrieval-augmented LLMs by venturing into a new task - code generation using external entities. For this task, we collect and publish a new dataset for project-level code generation, where the model should reuse functions defined in the project during generation. As we show, existing retrieval-augmented LLMs fail to assign relevance scores between similar entity names, and to mitigate it, they expand entity names with description context and append it to the input. In practice, due to the limited context size they can not accommodate the indefinitely large context of the whole project. To solve this issue, we propose a novel end-to-end trainable architecture with an scalable entity retriever injected directly into the LLM decoder. We demonstrate that our model can outperform common baselines in several scenarios, including project-level code generation, as well as Bash and SQL scripting.
General Object Foundation Model for Images and Videos at Scale
Dec 14, 2023We present GLEE in this work, an object-level foundation model for locating and identifying objects in images and videos. Through a unified framework, GLEE accomplishes detection, segmentation, tracking, grounding, and identification of arbitrary objects in the open world scenario for various object perception tasks. Adopting a cohesive learning strategy, GLEE acquires knowledge from diverse data sources with varying supervision levels to formulate general object representations, excelling in zero-shot transfer to new data and tasks. Specifically, we employ an image encoder, text encoder, and visual prompter to handle multi-modal inputs, enabling to simultaneously solve various object-centric downstream tasks while maintaining state-of-the-art performance. Demonstrated through extensive training on over five million images from diverse benchmarks, GLEE exhibits remarkable versatility and improved generalization performance, efficiently tackling downstream tasks without the need for task-specific adaptation. By integrating large volumes of automatically labeled data, we further enhance its zero-shot generalization capabilities. Additionally, GLEE is capable of being integrated into Large Language Models, serving as a foundational model to provide universal object-level information for multi-modal tasks. We hope that the versatility and universality of our method will mark a significant step in the development of efficient visual foundation models for AGI systems. The model and code will be released at https://glee-vision.github.io .
Local Conditional Controlling for Text-to-Image Diffusion Models
Dec 14, 2023Diffusion models have exhibited impressive prowess in the text-to-image task. Recent methods add image-level controls, e.g., edge and depth maps, to manipulate the generation process together with text prompts to obtain desired images. This controlling process is globally operated on the entire image, which limits the flexibility of control regions. In this paper, we introduce a new simple yet practical task setting: local control. It focuses on controlling specific local areas according to user-defined image conditions, where the rest areas are only conditioned by the original text prompt. This manner allows the users to flexibly control the image generation in a fine-grained way. However, it is non-trivial to achieve this goal. The naive manner of directly adding local conditions may lead to the local control dominance problem. To mitigate this problem, we propose a training-free method that leverages the updates of noised latents and parameters in the cross-attention map during the denosing process to promote concept generation in non-control areas. Moreover, we use feature mask constraints to mitigate the degradation of synthesized image quality caused by information differences inside and outside the local control area. Extensive experiments demonstrate that our method can synthesize high-quality images to the prompt under local control conditions. Code is available at https://github.com/YibooZhao/Local-Control.
Factorization Vision Transformer: Modeling Long Range Dependency with Local Window Cost
Dec 14, 2023Transformers have astounding representational power but typically consume considerable computation which is quadratic with image resolution. The prevailing Swin transformer reduces computational costs through a local window strategy. However, this strategy inevitably causes two drawbacks: (1) the local window-based self-attention hinders global dependency modeling capability; (2) recent studies point out that local windows impair robustness. To overcome these challenges, we pursue a preferable trade-off between computational cost and performance. Accordingly, we propose a novel factorization self-attention mechanism (FaSA) that enjoys both the advantages of local window cost and long-range dependency modeling capability. By factorizing the conventional attention matrix into sparse sub-attention matrices, FaSA captures long-range dependencies while aggregating mixed-grained information at a computational cost equivalent to the local window-based self-attention. Leveraging FaSA, we present the factorization vision transformer (FaViT) with a hierarchical structure. FaViT achieves high performance and robustness, with linear computational complexity concerning input image spatial resolution. Extensive experiments have shown FaViT's advanced performance in classification and downstream tasks. Furthermore, it also exhibits strong model robustness to corrupted and biased data and hence demonstrates benefits in favor of practical applications. In comparison to the baseline model Swin-T, our FaViT-B2 significantly improves classification accuracy by 1% and robustness by 7%, while reducing model parameters by 14%. Our code will soon be publicly available at https://github.com/q2479036243/FaViT.