 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CoSeR: Bridging Image and Language for Cognitive Super-Resolution
Nov 29, 2023
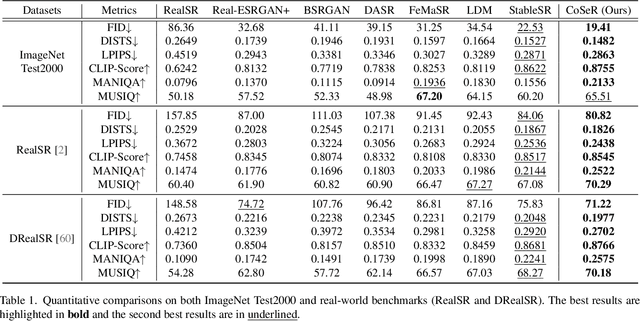
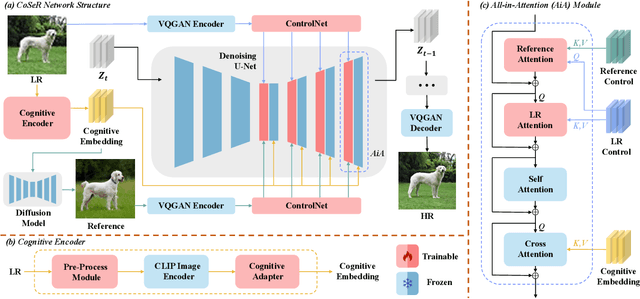
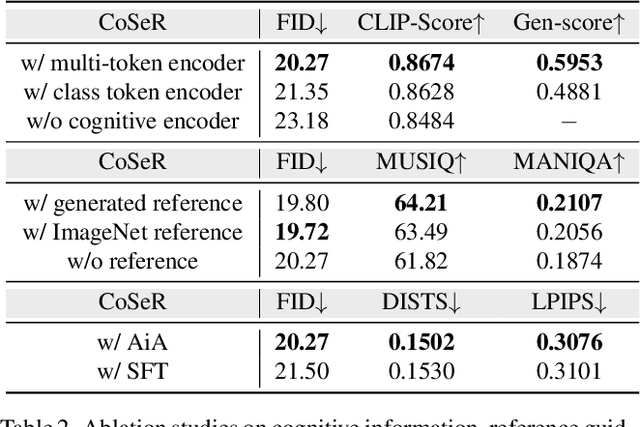
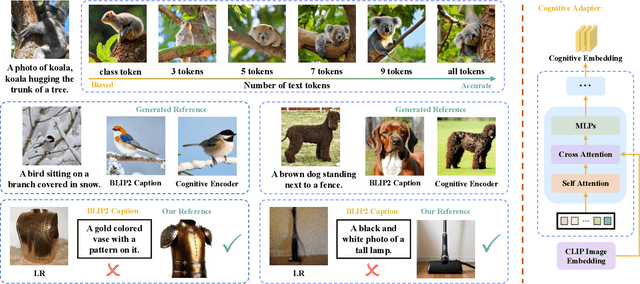
Existing super-resolution (SR) models primarily focus on restoring local texture details, often neglecting the global semantic information within the scene. This oversight can lead to the omission of crucial semantic details or the introduction of inaccurate textures during the recovery process. In our work, we introduce the Cognitive Super-Resolution (CoSeR) framework, empowering SR models with the capacity to comprehend low-resolution images. We achieve this by marrying image appearance and language understanding to generate a cognitive embedding, which not only activates prior information from large text-to-image diffusion models but also facilitates the generation of high-quality reference images to optimize the SR process. To further improve image fidelity, we propose a novel condition injection scheme called "All-in-Attention", consolidating all conditional information into a single module. Consequently, our method successfully restores semantically correct and photorealistic details, demonstrating state-of-the-art performance across multiple benchmarks. Code: https://github.com/VINHYU/CoSeR
$Q_{bias}$ -- A Dataset on Media Bias in Search Queries and Query Suggestions
Nov 29, 2023This publication describes the motivation and generation of $Q_{bias}$, a large dataset of Google and Bing search queries, a scraping tool and dataset for biased news articles, as well as language models for the investigation of bias in online search. Web search engines are a major factor and trusted source in information search, especially in the political domain. However, biased information can influence opinion formation and lead to biased opinions. To interact with search engines, users formulate search queries and interact with search query suggestions provided by the search engines. A lack of datasets on search queries inhibits research on the subject. We use $Q_{bias}$ to evaluate different approaches to fine-tuning transformer-based language models with the goal of producing models capable of biasing text with left and right political stance. Additionally to this work we provided datasets and language models for biasing texts that allow further research on bias in online information search.
RESIN-EDITOR: A Schema-guided Hierarchical Event Graph Visualizer and Editor
Dec 05, 2023

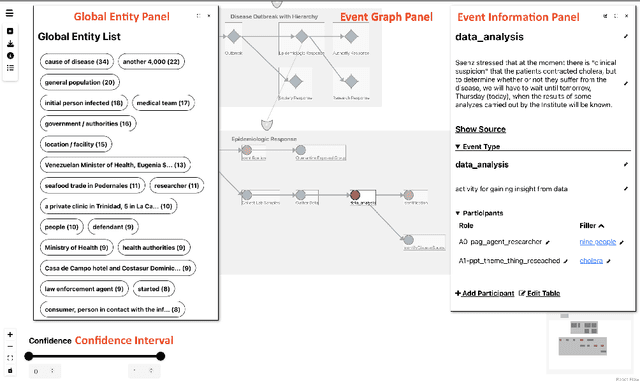
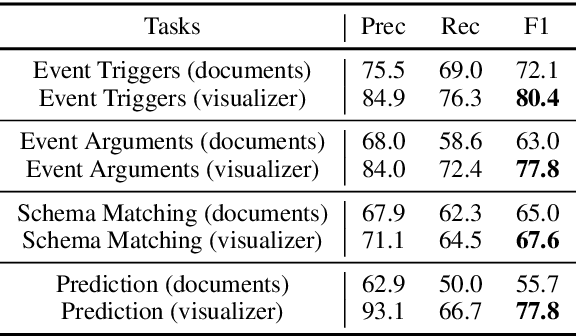
In this paper, we present RESIN-EDITOR, an interactive event graph visualizer and editor designed for analyzing complex events. Our RESIN-EDITOR system allows users to render and freely edit hierarchical event graphs extracted from multimedia and multi-document news clusters with guidance from human-curated event schemas. RESIN-EDITOR's unique features include hierarchical graph visualization, comprehensive source tracing, and interactive user editing, which is more powerful and versatile than existing Information Extraction (IE) visualization tools. In our evaluation of RESIN-EDITOR, we demonstrate ways in which our tool is effective in understanding complex events and enhancing system performance. The source code, a video demonstration, and a live website for RESIN-EDITOR have been made publicly available.
Beyond Isolation: Multi-Agent Synergy for Improving Knowledge Graph Construction
Dec 05, 2023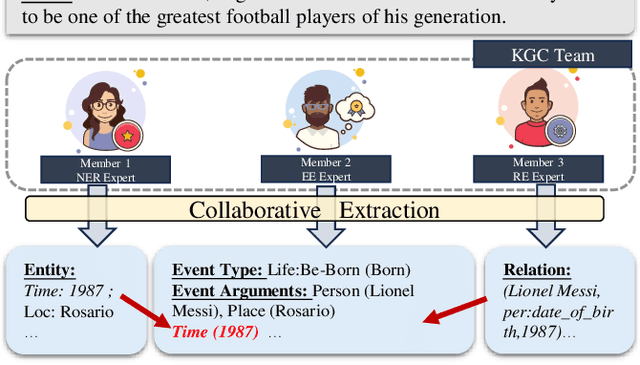


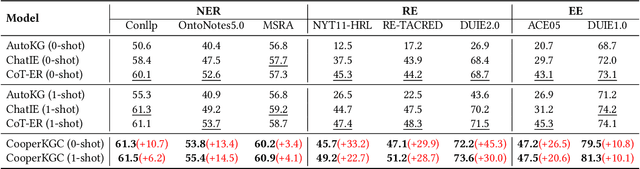
Knowledge graph construction (KGC) is a multifaceted undertaking involving the extraction of entities, relations, and events. Traditionally, large language models (LLMs) have been viewed as solitary task-solving agents in this complex landscape. However, this paper challenges this paradigm by introducing a novel framework, CooperKGC. Departing from the conventional approach, CooperKGC establishes a collaborative processing network, assembling a KGC collaboration team capable of concurrently addressing entity, relation, and event extraction tasks. Our experiments unequivocally demonstrate that fostering collaboration and information interaction among diverse agents within CooperKGC yields superior results compared to individual cognitive processes operating in isolation. Importantly, our findings reveal that the collaboration facilitated by CooperKGC enhances knowledge selection, correction, and aggregation capabilities across multiple rounds of interactions.
INSPECT: Intrinsic and Systematic Probing Evaluation for Code Transformers
Dec 08, 2023Pre-trained models of source code have recently been successfully applied to a wide variety of Software Engineering tasks; they have also seen some practical adoption in practice, e.g. for code completion. Yet, we still know very little about what these pre-trained models learn about source code. In this article, we use probing--simple diagnostic tasks that do not further train the models--to discover to what extent pre-trained models learn about specific aspects of source code. We use an extensible framework to define 15 probing tasks that exercise surface, syntactic, structural and semantic characteristics of source code. We probe 8 pre-trained source code models, as well as a natural language model (BERT) as our baseline. We find that models that incorporate some structural information (such as GraphCodeBERT) have a better representation of source code characteristics. Surprisingly, we find that for some probing tasks, BERT is competitive with the source code models, indicating that there are ample opportunities to improve source-code specific pre-training on the respective code characteristics. We encourage other researchers to evaluate their models with our probing task suite, so that they may peer into the hidden layers of the models and identify what intrinsic code characteristics are encoded.
Synthesizing Traffic Datasets using Graph Neural Networks
Dec 08, 2023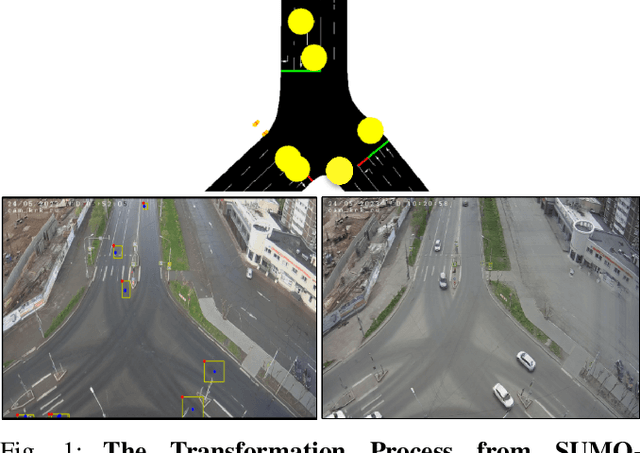
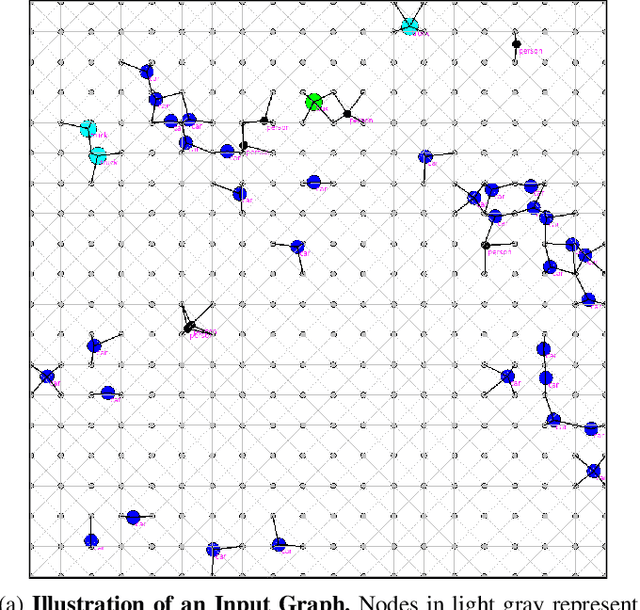
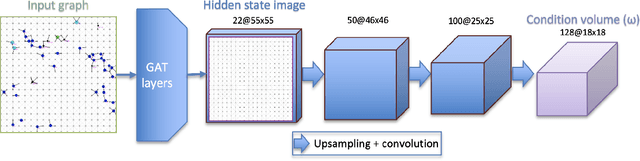
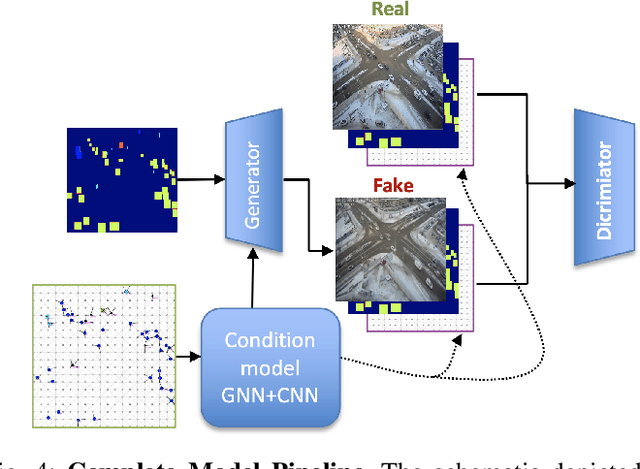
Traffic congestion in urban areas presents significant challenges, and Intelligent Transportation Systems (ITS) have sought to address these via automated and adaptive controls. However, these systems often struggle to transfer simulated experiences to real-world scenarios. This paper introduces a novel methodology for bridging this `sim-real' gap by creating photorealistic images from 2D traffic simulations and recorded junction footage. We propose a novel image generation approach, integrating a Conditional Generative Adversarial Network with a Graph Neural Network (GNN) to facilitate the creation of realistic urban traffic images. We harness GNNs' ability to process information at different levels of abstraction alongside segmented images for preserving locality data. The presented architecture leverages the power of SPADE and Graph ATtention (GAT) network models to create images based on simulated traffic scenarios. These images are conditioned by factors such as entity positions, colors, and time of day. The uniqueness of our approach lies in its ability to effectively translate structured and human-readable conditions, encoded as graphs, into realistic images. This advancement contributes to applications requiring rich traffic image datasets, from data augmentation to urban traffic solutions. We further provide an application to test the model's capabilities, including generating images with manually defined positions for various entities.
Beyond Transduction: A Survey on Inductive, Few Shot, and Zero Shot Link Prediction in Knowledge Graphs
Dec 08, 2023Knowledge graphs (KGs) comprise entities interconnected by relations of different semantic meanings. KGs are being used in a wide range of applications. However, they inherently suffer from incompleteness, i.e. entities or facts about entities are missing. Consequently, a larger body of works focuses on the completion of missing information in KGs, which is commonly referred to as link prediction (LP). This task has traditionally and extensively been studied in the transductive setting, where all entities and relations in the testing set are observed during training. Recently, several works have tackled the LP task under more challenging settings, where entities and relations in the test set may be unobserved during training, or appear in only a few facts. These works are known as inductive, few-shot, and zero-shot link prediction. In this work, we conduct a systematic review of existing works in this area. A thorough analysis leads us to point out the undesirable existence of diverging terminologies and task definitions for the aforementioned settings, which further limits the possibility of comparison between recent works. We consequently aim at dissecting each setting thoroughly, attempting to reveal its intrinsic characteristics. A unifying nomenclature is ultimately proposed to refer to each of them in a simple and consistent manner.
Modeling Risk in Reinforcement Learning: A Literature Mapping
Dec 08, 2023Safe reinforcement learning deals with mitigating or avoiding unsafe situations by reinforcement learning (RL) agents. Safe RL approaches are based on specific risk representations for particular problems or domains. In order to analyze agent behaviors, compare safe RL approaches, and effectively transfer techniques between application domains, it is necessary to understand the types of risk specific to safe RL problems. We performed a systematic literature mapping with the objective to characterize risk in safe RL. Based on the obtained results, we present definitions, characteristics, and types of risk that hold on multiple application domains. Our literature mapping covers literature from the last 5 years (2017-2022), from a variety of knowledge areas (AI, finance, engineering, medicine) where RL approaches emphasize risk representation and management. Our mapping covers 72 papers filtered systematically from over thousands of papers on the topic. Our proposed notion of risk covers a variety of representations, disciplinary differences, common training exercises, and types of techniques. We encourage researchers to include explicit and detailed accounts of risk in future safe RL research reports, using this mapping as a starting point. With this information, researchers and practitioners could draw stronger conclusions on the effectiveness of techniques on different problems.
NeuSD: Surface Completion with Multi-View Text-to-Image Diffusion
Dec 07, 2023We present a novel method for 3D surface reconstruction from multiple images where only a part of the object of interest is captured. Our approach builds on two recent developments: surface reconstruction using neural radiance fields for the reconstruction of the visible parts of the surface, and guidance of pre-trained 2D diffusion models in the form of Score Distillation Sampling (SDS) to complete the shape in unobserved regions in a plausible manner. We introduce three components. First, we suggest employing normal maps as a pure geometric representation for SDS instead of color renderings which are entangled with the appearance information. Second, we introduce the freezing of the SDS noise during training which results in more coherent gradients and better convergence. Third, we propose Multi-View SDS as a way to condition the generation of the non-observable part of the surface without fine-tuning or making changes to the underlying 2D Stable Diffusion model. We evaluate our approach on the BlendedMVS dataset demonstrating significant qualitative and quantitative improvements over competing methods.
Graph Metanetworks for Processing Diverse Neural Architectures
Dec 07, 2023Neural networks efficiently encode learned information within their parameters. Consequently, many tasks can be unified by treating neural networks themselves as input data. When doing so, recent studies demonstrated the importance of accounting for the symmetries and geometry of parameter spaces. However, those works developed architectures tailored to specific networks such as MLPs and CNNs without normalization layers, and generalizing such architectures to other types of networks can be challenging. In this work, we overcome these challenges by building new metanetworks - neural networks that take weights from other neural networks as input. Put simply, we carefully build graphs representing the input neural networks and process the graphs using graph neural networks. Our approach, Graph Metanetworks (GMNs), generalizes to neural architectures where competing methods struggle, such as multi-head attention layers, normalization layers, convolutional layers, ResNet blocks, and group-equivariant linear layers. We prove that GMNs are expressive and equivariant to parameter permutation symmetries that leave the input neural network functions unchanged. We validate the effectiveness of our method on several metanetwork tasks over diverse neural network architectures.