 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Auto DP-SGD: Dual Improvements of Privacy and Accuracy via Automatic Clipping Threshold and Noise Multiplier Estimation
Dec 05, 2023
DP-SGD has emerged as a popular method to protect personally identifiable information in deep learning applications. Unfortunately, DP-SGD's per-sample gradient clipping and uniform noise addition during training can significantly degrade model utility. To enhance the model's utility, researchers proposed various adaptive DP-SGD methods. However, we examine and discover that these techniques result in greater privacy leakage or lower accuracy than the traditional DP-SGD method, or a lack of evaluation on a complex data set such as CIFAR100. To address these limitations, we propose an Auto DP-SGD. Our method automates clipping threshold estimation based on the DL model's gradient norm and scales the gradients of each training sample without losing gradient information. This helps to improve the algorithm's utility while using a less privacy budget. To further improve accuracy, we introduce automatic noise multiplier decay mechanisms to decrease the noise multiplier after every epoch. Finally, we develop closed-form mathematical expressions using tCDP accountant for automatic noise multiplier and automatic clipping threshold estimation. Through extensive experimentation, we demonstrate that Auto DP-SGD outperforms existing SOTA DP-SGD methods in privacy and accuracy on various benchmark datasets. We also show that privacy can be improved by lowering the scale factor and using learning rate schedulers without significantly reducing accuracy. Specifically, Auto DP-SGD, when used with a step noise multiplier, improves accuracy by 3.20, 1.57, 6.73, and 1.42 for the MNIST, CIFAR10, CIFAR100, and AG News Corpus datasets, respectively. Furthermore, it obtains a substantial reduction in the privacy budget of 94.9, 79.16, 67.36, and 53.37 for the corresponding data sets.
TokenCompose: Grounding Diffusion with Token-level Supervision
Dec 06, 2023We present TokenCompose, a Latent Diffusion Model for text-to-image generation that achieves enhanced consistency between user-specified text prompts and model-generated images. Despite its tremendous success, the standard denoising process in the Latent Diffusion Model takes text prompts as conditions only, absent explicit constraint for the consistency between the text prompts and the image contents, leading to unsatisfactory results for composing multiple object categories. TokenCompose aims to improve multi-category instance composition by introducing the token-wise consistency terms between the image content and object segmentation maps in the finetuning stage. TokenCompose can be applied directly to the existing training pipeline of text-conditioned diffusion models without extra human labeling information. By finetuning Stable Diffusion, the model exhibits significant improvements in multi-category instance composition and enhanced photorealism for its generated images.
Markov Chain Monte Carlo Data Association for Sets of Trajectories
Dec 06, 2023This paper considers a batch solution to the multi-object tracking problem based on sets of trajectories. Specifically, we present two offline implementations of the trajectory Poisson multi-Bernoulli mixture (TPMBM) filter for batch data based on Markov chain Monte Carlo (MCMC) sampling of the data association hypotheses. In contrast to online TPMBM implementations, the proposed offline implementations solve a large-scale, multi-scan data association problem across the entire time interval of interest, and therefore they can fully exploit all the measurement information available. Furthermore, by leveraging the efficient hypothesis structure of TPMBM filters, the proposed implementations compare favorably with other MCMC-based multi-object tracking algorithms. Simulation results show that the TPMBM implementation using the Metropolis-Hastings algorithm presents state-of-the-art multiple trajectory estimation performance.
Privacy Preserving Multi-Agent Reinforcement Learning in Supply Chains
Dec 09, 2023This paper addresses privacy concerns in multi-agent reinforcement learning (MARL), specifically within the context of supply chains where individual strategic data must remain confidential. Organizations within the supply chain are modeled as agents, each seeking to optimize their own objectives while interacting with others. As each organization's strategy is contingent on neighboring strategies, maintaining privacy of state and action-related information is crucial. To tackle this challenge, we propose a game-theoretic, privacy-preserving mechanism, utilizing a secure multi-party computation (MPC) framework in MARL settings. Our major contribution is the successful implementation of a secure MPC framework, SecFloat on EzPC, to solve this problem. However, simply implementing policy gradient methods such as MADDPG operations using SecFloat, while conceptually feasible, would be programmatically intractable. To overcome this hurdle, we devise a novel approach that breaks down the forward and backward pass of the neural network into elementary operations compatible with SecFloat , creating efficient and secure versions of the MADDPG algorithm. Furthermore, we present a learning mechanism that carries out floating point operations in a privacy-preserving manner, an important feature for successful learning in MARL framework. Experiments reveal that there is on average 68.19% less supply chain wastage in 2 PC compared to no data share, while also giving on average 42.27% better average cumulative revenue for each player. This work paves the way for practical, privacy-preserving MARL, promising significant improvements in secure computation within supply chain contexts and broadly.
Better Neural PDE Solvers Through Data-Free Mesh Movers
Dec 09, 2023Recently, neural networks have been extensively employed to solve partial differential equations (PDEs) in physical system modeling. While major studies focus on learning system evolution on predefined static mesh discretizations, some methods utilize reinforcement learning or supervised learning techniques to create adaptive and dynamic meshes, due to the dynamic nature of these systems. However, these approaches face two primary challenges: (1) the need for expensive optimal mesh data, and (2) the change of the solution space's degree of freedom and topology during mesh refinement. To address these challenges, this paper proposes a neural PDE solver with a neural mesh adapter. To begin with, we introduce a novel data-free neural mesh adaptor, called Data-free Mesh Mover (DMM), with two main innovations. Firstly, it is an operator that maps the solution to adaptive meshes and is trained using the Monge-Ampere equation without optimal mesh data. Secondly, it dynamically changes the mesh by moving existing nodes rather than adding or deleting nodes and edges. Theoretical analysis shows that meshes generated by DMM have the lowest interpolation error bound. Based on DMM, to efficiently and accurately model dynamic systems, we develop a moving mesh based neural PDE solver (MM-PDE) that embeds the moving mesh with a two-branch architecture and a learnable interpolation framework to preserve information within the data. Empirical experiments demonstrate that our method generates suitable meshes and considerably enhances accuracy when modeling widely considered PDE systems.
LLMs may Dominate Information Access: Neural Retrievers are Biased Towards LLM-Generated Texts
Oct 31, 2023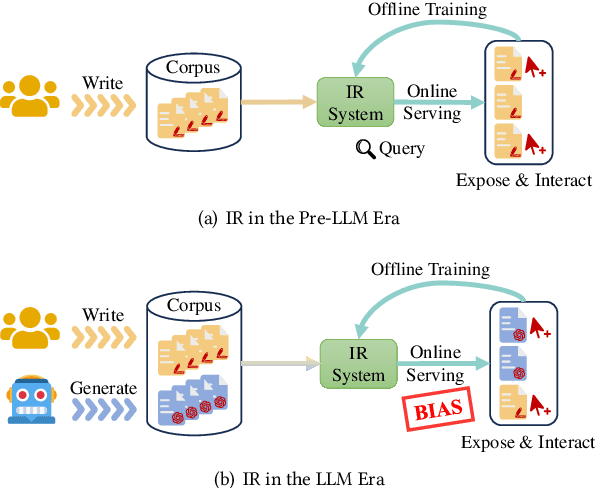
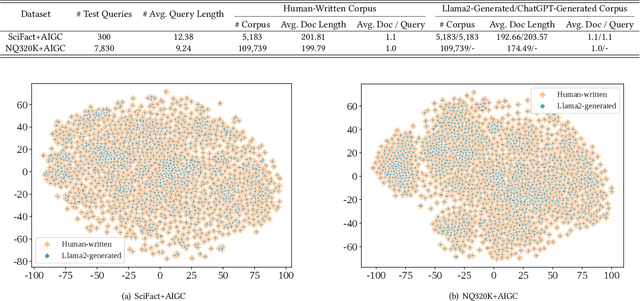
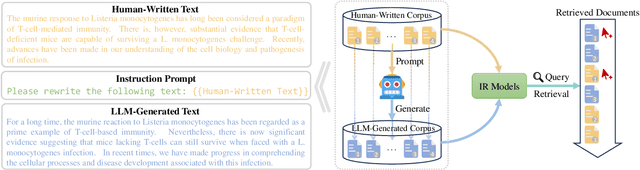
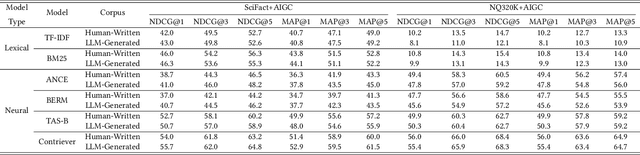
Recently, the emergence of large language models (LLMs) has revolutionized the paradigm of information retrieval (IR) applications, especially in web search. With their remarkable capabilities in generating human-like texts, LLMs have created enormous texts on the Internet. As a result, IR systems in the LLMs era are facing a new challenge: the indexed documents now are not only written by human beings but also automatically generated by the LLMs. How these LLM-generated documents influence the IR systems is a pressing and still unexplored question. In this work, we conduct a quantitative evaluation of different IR models in scenarios where both human-written and LLM-generated texts are involved. Surprisingly, our findings indicate that neural retrieval models tend to rank LLM-generated documents higher.We refer to this category of biases in neural retrieval models towards the LLM-generated text as the \textbf{source bias}. Moreover, we discover that this bias is not confined to the first-stage neural retrievers, but extends to the second-stage neural re-rankers. Then, we provide an in-depth analysis from the perspective of text compression and observe that neural models can better understand the semantic information of LLM-generated text, which is further substantiated by our theoretical analysis.We also discuss the potential server concerns stemming from the observed source bias and hope our findings can serve as a critical wake-up call to the IR community and beyond. To facilitate future explorations of IR in the LLM era, the constructed two new benchmarks and codes will later be available at \url{https://github.com/KID-22/LLM4IR-Bias}.
DistNet2D: Leveraging long-range temporal information for efficient segmentation and tracking
Oct 30, 2023Extracting long tracks and lineages from videomicroscopy requires an extremely low error rate, which is challenging on complex datasets of dense or deforming cells. Leveraging temporal context is key to overcome this challenge. We propose DistNet2D, a new deep neural network (DNN) architecture for 2D cell segmentation and tracking that leverages both mid- and long-term temporal context. DistNet2D considers seven frames at the input and uses a post-processing procedure that exploits information from the entire movie to correct segmentation errors. DistNet2D outperforms two recent methods on two experimental datasets, one containing densely packed bacterial cells and the other containing eukaryotic cells. It has been integrated into an ImageJ-based graphical user interface for 2D data visualization, curation, and training. Finally, we demonstrate the performance of DistNet2D on correlating the size and shape of cells with their transport properties over large statistics, for both bacterial and eukaryotic cells.
Better Together: Enhancing Generative Knowledge Graph Completion with Language Models and Neighborhood Information
Nov 02, 2023Real-world Knowledge Graphs (KGs) often suffer from incompleteness, which limits their potential performance. Knowledge Graph Completion (KGC) techniques aim to address this issue. However, traditional KGC methods are computationally intensive and impractical for large-scale KGs, necessitating the learning of dense node embeddings and computing pairwise distances. Generative transformer-based language models (e.g., T5 and recent KGT5) offer a promising solution as they can predict the tail nodes directly. In this study, we propose to include node neighborhoods as additional information to improve KGC methods based on language models. We examine the effects of this imputation and show that, on both inductive and transductive Wikidata subsets, our method outperforms KGT5 and conventional KGC approaches. We also provide an extensive analysis of the impact of neighborhood on model prediction and show its importance. Furthermore, we point the way to significantly improve KGC through more effective neighborhood selection.
CHAIN: Exploring Global-Local Spatio-Temporal Information for Improved Self-Supervised Video Hashing
Oct 29, 2023Compressing videos into binary codes can improve retrieval speed and reduce storage overhead. However, learning accurate hash codes for video retrieval can be challenging due to high local redundancy and complex global dependencies between video frames, especially in the absence of labels. Existing self-supervised video hashing methods have been effective in designing expressive temporal encoders, but have not fully utilized the temporal dynamics and spatial appearance of videos due to less challenging and unreliable learning tasks. To address these challenges, we begin by utilizing the contrastive learning task to capture global spatio-temporal information of videos for hashing. With the aid of our designed augmentation strategies, which focus on spatial and temporal variations to create positive pairs, the learning framework can generate hash codes that are invariant to motion, scale, and viewpoint. Furthermore, we incorporate two collaborative learning tasks, i.e., frame order verification and scene change regularization, to capture local spatio-temporal details within video frames, thereby enhancing the perception of temporal structure and the modeling of spatio-temporal relationships. Our proposed Contrastive Hashing with Global-Local Spatio-temporal Information (CHAIN) outperforms state-of-the-art self-supervised video hashing methods on four video benchmark datasets. Our codes will be released.
INSPECT: Intrinsic and Systematic Probing Evaluation for Code Transformers
Dec 08, 2023Pre-trained models of source code have recently been successfully applied to a wide variety of Software Engineering tasks; they have also seen some practical adoption in practice, e.g. for code completion. Yet, we still know very little about what these pre-trained models learn about source code. In this article, we use probing--simple diagnostic tasks that do not further train the models--to discover to what extent pre-trained models learn about specific aspects of source code. We use an extensible framework to define 15 probing tasks that exercise surface, syntactic, structural and semantic characteristics of source code. We probe 8 pre-trained source code models, as well as a natural language model (BERT) as our baseline. We find that models that incorporate some structural information (such as GraphCodeBERT) have a better representation of source code characteristics. Surprisingly, we find that for some probing tasks, BERT is competitive with the source code models, indicating that there are ample opportunities to improve source-code specific pre-training on the respective code characteristics. We encourage other researchers to evaluate their models with our probing task suite, so that they may peer into the hidden layers of the models and identify what intrinsic code characteristics are encoded.