 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Integrated Drill Boom Hole-Seeking Control via Reinforcement Learning
Dec 04, 2023
Intelligent drill boom hole-seeking is a promising technology for enhancing drilling efficiency, mitigating potential safety hazards, and relieving human operators. Most existing intelligent drill boom control methods rely on a hierarchical control framework based on inverse kinematics. However, these methods are generally time-consuming due to the computational complexity of inverse kinematics and the inefficiency of the sequential execution of multiple joints. To tackle these challenges, this study proposes an integrated drill boom control method based on Reinforcement Learning (RL). We develop an integrated drill boom control framework that utilizes a parameterized policy to directly generate control inputs for all joints at each time step, taking advantage of joint posture and target hole information. By formulating the hole-seeking task as a Markov decision process, contemporary mainstream RL algorithms can be directly employed to learn a hole-seeking policy, thus eliminating the need for inverse kinematics solutions and promoting cooperative multi-joint control. To enhance the drilling accuracy throughout the entire drilling process, we devise a state representation that combines Denavit-Hartenberg joint information and preview hole-seeking discrepancy data. Simulation results show that the proposed method significantly outperforms traditional methods in terms of hole-seeking accuracy and time efficiency.
BioCLIP: A Vision Foundation Model for the Tree of Life
Dec 04, 2023

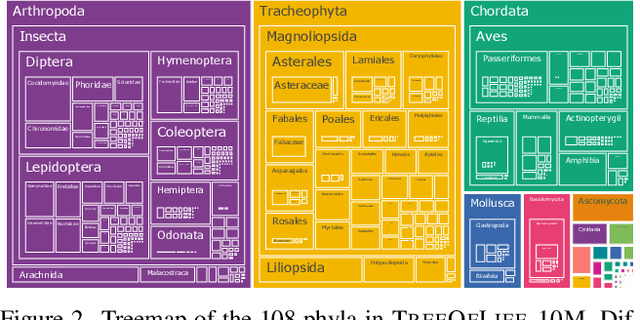

Images of the natural world, collected by a variety of cameras, from drones to individual phones, are increasingly abundant sources of biological information. There is an explosion of computational methods and tools, particularly computer vision, for extracting biologically relevant information from images for science and conservation. Yet most of these are bespoke approaches designed for a specific task and are not easily adaptable or extendable to new questions, contexts, and datasets. A vision model for general organismal biology questions on images is of timely need. To approach this, we curate and release TreeOfLife-10M, the largest and most diverse ML-ready dataset of biology images. We then develop BioCLIP, a foundation model for the tree of life, leveraging the unique properties of biology captured by TreeOfLife-10M, namely the abundance and variety of images of plants, animals, and fungi, together with the availability of rich structured biological knowledge. We rigorously benchmark our approach on diverse fine-grained biology classification tasks, and find that BioCLIP consistently and substantially outperforms existing baselines (by 17% to 20% absolute). Intrinsic evaluation reveals that BioCLIP has learned a hierarchical representation conforming to the tree of life, shedding light on its strong generalizability. Our code, models and data will be made available at https://github.com/Imageomics/bioclip.
Keyword-optimized Template Insertion for Clinical Information Extraction via Prompt-based Learning
Oct 31, 2023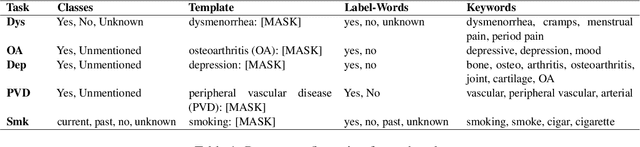
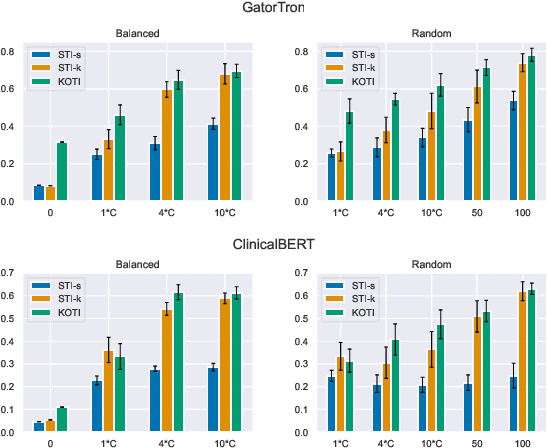
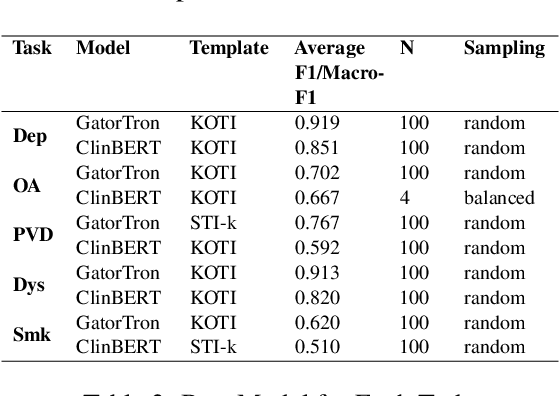

Clinical note classification is a common clinical NLP task. However, annotated data-sets are scarse. Prompt-based learning has recently emerged as an effective method to adapt pre-trained models for text classification using only few training examples. A critical component of prompt design is the definition of the template (i.e. prompt text). The effect of template position, however, has been insufficiently investigated. This seems particularly important in the clinical setting, where task-relevant information is usually sparse in clinical notes. In this study we develop a keyword-optimized template insertion method (KOTI) and show how optimizing position can improve performance on several clinical tasks in a zero-shot and few-shot training setting.
ALSTER: A Local Spatio-Temporal Expert for Online 3D Semantic Reconstruction
Dec 03, 2023We propose an online 3D semantic segmentation method that incrementally reconstructs a 3D semantic map from a stream of RGB-D frames. Unlike offline methods, ours is directly applicable to scenarios with real-time constraints, such as robotics or mixed reality. To overcome the inherent challenges of online methods, we make two main contributions. First, to effectively extract information from the input RGB-D video stream, we jointly estimate geometry and semantic labels per frame in 3D. A key focus of our approach is to reason about semantic entities both in the 2D input and the local 3D domain to leverage differences in spatial context and network architectures. Our method predicts 2D features using an off-the-shelf segmentation network. The extracted 2D features are refined by a lightweight 3D network to enable reasoning about the local 3D structure. Second, to efficiently deal with an infinite stream of input RGB-D frames, a subsequent network serves as a temporal expert predicting the incremental scene updates by leveraging 2D, 3D, and past information in a learned manner. These updates are then integrated into a global scene representation. Using these main contributions, our method can enable scenarios with real-time constraints and can scale to arbitrary scene sizes by processing and updating the scene only in a local region defined by the new measurement. Our experiments demonstrate improved results compared to existing online methods that purely operate in local regions and show that complementary sources of information can boost the performance. We provide a thorough ablation study on the benefits of different architectural as well as algorithmic design decisions. Our method yields competitive results on the popular ScanNet benchmark and SceneNN dataset.
Zero-Shot Point Cloud Registration
Dec 08, 2023
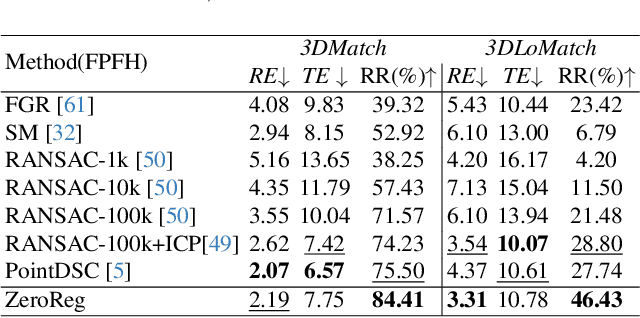
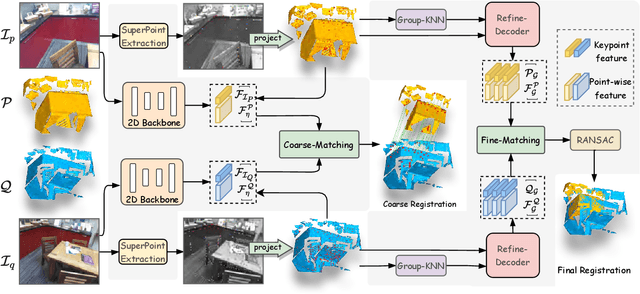
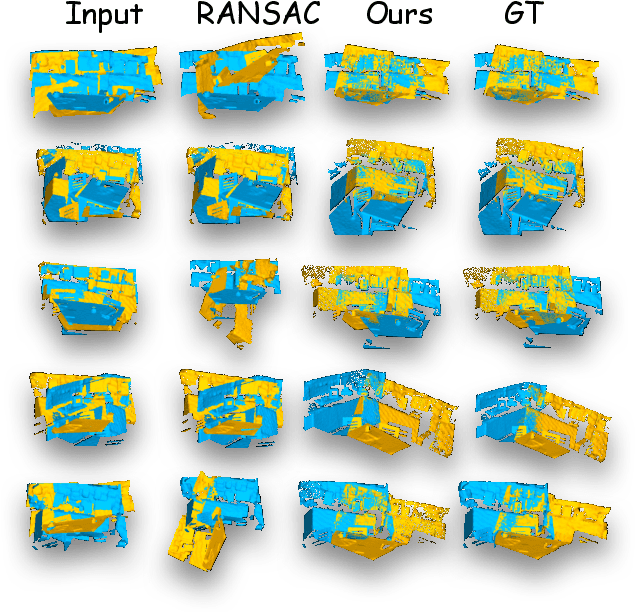
Learning-based point cloud registration approaches have significantly outperformed their traditional counterparts. However, they typically require extensive training on specific datasets. In this paper, we propose , the first zero-shot point cloud registration approach that eliminates the need for training on point cloud datasets. The cornerstone of ZeroReg is the novel transfer of image features from keypoints to the point cloud, enriched by aggregating information from 3D geometric neighborhoods. Specifically, we extract keypoints and features from 2D image pairs using a frozen pretrained 2D backbone. These features are then projected in 3D, and patches are constructed by searching for neighboring points. We integrate the geometric and visual features of each point using our novel parameter-free geometric decoder. Subsequently, the task of determining correspondences between point clouds is formulated as an optimal transport problem. Extensive evaluations of ZeroReg demonstrate its competitive performance against both traditional and learning-based methods. On benchmarks such as 3DMatch, 3DLoMatch, and ScanNet, ZeroReg achieves impressive Recall Ratios (RR) of over 84%, 46%, and 75%, respectively.
ControlRoom3D: Room Generation using Semantic Proxy Rooms
Dec 08, 2023Manually creating 3D environments for AR/VR applications is a complex process requiring expert knowledge in 3D modeling software. Pioneering works facilitate this process by generating room meshes conditioned on textual style descriptions. Yet, many of these automatically generated 3D meshes do not adhere to typical room layouts, compromising their plausibility, e.g., by placing several beds in one bedroom. To address these challenges, we present ControlRoom3D, a novel method to generate high-quality room meshes. Central to our approach is a user-defined 3D semantic proxy room that outlines a rough room layout based on semantic bounding boxes and a textual description of the overall room style. Our key insight is that when rendered to 2D, this 3D representation provides valuable geometric and semantic information to control powerful 2D models to generate 3D consistent textures and geometry that aligns well with the proxy room. Backed up by an extensive study including quantitative metrics and qualitative user evaluations, our method generates diverse and globally plausible 3D room meshes, thus empowering users to design 3D rooms effortlessly without specialized knowledge.
Quantitative perfusion maps using a novelty spatiotemporal convolutional neural network
Dec 08, 2023Dynamic susceptibility contrast magnetic resonance imaging (DSC-MRI) is widely used to evaluate acute ischemic stroke to distinguish salvageable tissue and infarct core. For this purpose, traditional methods employ deconvolution techniques, like singular value decomposition, which are known to be vulnerable to noise, potentially distorting the derived perfusion parameters. However, deep learning technology could leverage it, which can accurately estimate clinical perfusion parameters compared to traditional clinical approaches. Therefore, this study presents a perfusion parameters estimation network that considers spatial and temporal information, the Spatiotemporal Network (ST-Net), for the first time. The proposed network comprises a designed physical loss function to enhance model performance further. The results indicate that the network can accurately estimate perfusion parameters, including cerebral blood volume (CBV), cerebral blood flow (CBF), and time to maximum of the residual function (Tmax). The structural similarity index (SSIM) mean values for CBV, CBF, and Tmax parameters were 0.952, 0.943, and 0.863, respectively. The DICE score for the hypo-perfused region reached 0.859, demonstrating high consistency. The proposed model also maintains time efficiency, closely approaching the performance of commercial gold-standard software.
Critical Analysis of 5G Networks Traffic Intrusion using PCA, t-SNE and UMAP Visualization and Classifying Attacks
Dec 08, 2023Networks, threat models, and malicious actors are advancing quickly. With the increased deployment of the 5G networks, the security issues of the attached 5G physical devices have also increased. Therefore, artificial intelligence based autonomous end-to-end security design is needed that can deal with incoming threats by detecting network traffic anomalies. To address this requirement, in this research, we used a recently published 5G traffic dataset, 5G-NIDD, to detect network traffic anomalies using machine and deep learning approaches. First, we analyzed the dataset using three visualization techniques: t-Distributed Stochastic Neighbor Embedding (t-SNE), Uniform Manifold Approximation and Projection (UMAP), and Principal Component Analysis (PCA). Second, we reduced the data dimensionality using mutual information and PCA techniques. Third, we solve the class imbalance issue by inserting synthetic records of minority classes. Last, we performed classification using six different classifiers and presented the evaluation metrics. We received the best results when K-Nearest Neighbors classifier was used: accuracy (97.2%), detection rate (96.7%), and false positive rate (2.2%).
SiCP: Simultaneous Individual and Cooperative Perception for 3D Object Detection in Connected and Automated Vehicles
Dec 08, 2023Cooperative perception for connected and automated vehicles is traditionally achieved through the fusion of feature maps from two or more vehicles. However, the absence of feature maps shared from other vehicles can lead to a significant decline in object detection performance for cooperative perception models compared to standalone 3D detection models. This drawback impedes the adoption of cooperative perception as vehicle resources are often insufficient to concurrently employ two perception models. To tackle this issue, we present Simultaneous Individual and Cooperative Perception (SiCP), a generic framework that supports a wide range of the state-of-the-art standalone perception backbones and enhances them with a novel Dual-Perception Network (DP-Net) designed to facilitate both individual and cooperative perception. In addition to its lightweight nature with only 0.13M parameters, DP-Net is robust and retains crucial gradient information during feature map fusion. As demonstrated in a comprehensive evaluation on the OPV2V dataset, thanks to DP-Net, SiCP surpasses state-of-the-art cooperative perception solutions while preserving the performance of standalone perception solutions.
MIDDAG: Where Does Our News Go? Investigating Information Diffusion via Community-Level Information Pathways
Oct 04, 2023We present MIDDAG, an intuitive, interactive system that visualizes the information propagation paths on social media triggered by COVID-19-related news articles accompanied by comprehensive insights including user/community susceptibility level, as well as events and popular opinions raised by the crowd while propagating the information. Besides discovering information flow patterns among users, we construct communities among users and develop the propagation forecasting capability, enabling tracing and understanding of how information is disseminated at a higher level.