 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multimodal Misinformation Detection in a South African Social Media Environment
Dec 07, 2023
With the constant spread of misinformation on social media networks, a need has arisen to continuously assess the veracity of digital content. This need has inspired numerous research efforts on the development of misinformation detection (MD) models. However, many models do not use all information available to them and existing research contains a lack of relevant datasets to train the models, specifically within the South African social media environment. The aim of this paper is to investigate the transferability of knowledge of a MD model between different contextual environments. This research contributes a multimodal MD model capable of functioning in the South African social media environment, as well as introduces a South African misinformation dataset. The model makes use of multiple sources of information for misinformation detection, namely: textual and visual elements. It uses bidirectional encoder representations from transformers (BERT) as the textual encoder and a residual network (ResNet) as the visual encoder. The model is trained and evaluated on the Fakeddit dataset and a South African misinformation dataset. Results show that using South African samples in the training of the model increases model performance, in a South African contextual environment, and that a multimodal model retains significantly more knowledge than both the textual and visual unimodal models. Our study suggests that the performance of a misinformation detection model is influenced by the cultural nuances of its operating environment and multimodal models assist in the transferability of knowledge between different contextual environments. Therefore, local data should be incorporated into the training process of a misinformation detection model in order to optimize model performance.
Information Value: Measuring Utterance Predictability as Distance from Plausible Alternatives
Oct 20, 2023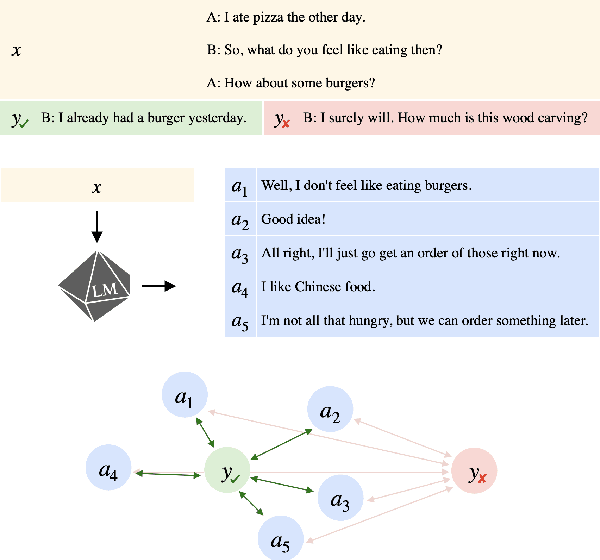
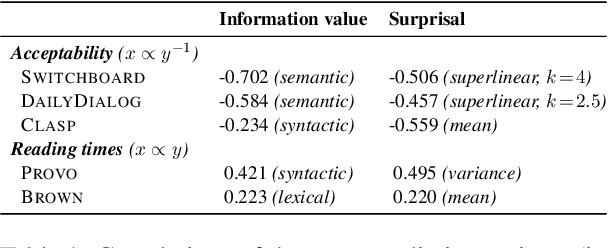
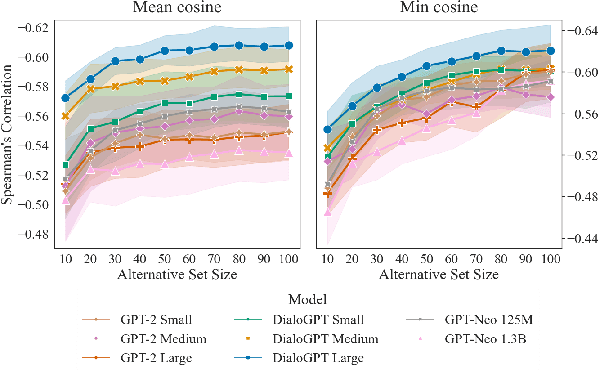
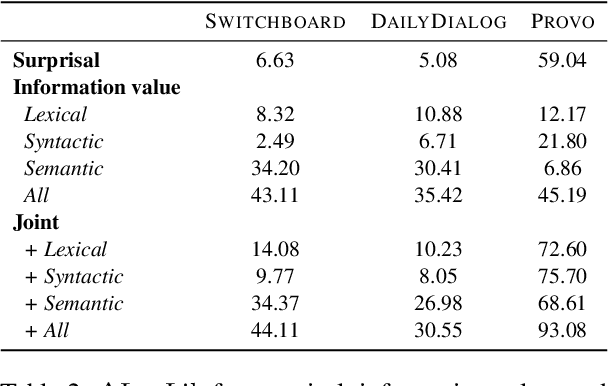
We present information value, a measure which quantifies the predictability of an utterance relative to a set of plausible alternatives. We introduce a method to obtain interpretable estimates of information value using neural text generators, and exploit their psychometric predictive power to investigate the dimensions of predictability that drive human comprehension behaviour. Information value is a stronger predictor of utterance acceptability in written and spoken dialogue than aggregates of token-level surprisal and it is complementary to surprisal for predicting eye-tracked reading times.
Fractional Chirp-Slope-Shift-Keying for SDR-based Search and Rescue Applications
Dec 08, 2023The use of modern software-defined radio (SDR) devices enables the implementation of efficient communication systems in numerous scenarios. Such technology comes especially handy in the context of search and rescue (SAR) systems, enabling the incorporation of additional communication data transmission into the otherwise sub-optimally used SAR bands at 121.5 and 243~MHz. In this work, we propose a novel low-complexity, energy-efficient modulation scheme that allows transmission of additional data within chirped homing signals, while still meeting the standards of international SAR systems such as COSPAS-SARSAT. The proposed method modulates information onto small deviations of the chirp slope with respect to the required unmodulated chirp, which can be easily detected at the receiver side using digital signal processing.
Vehicle Lane Change Prediction based on Knowledge Graph Embeddings and Bayesian Inference
Dec 11, 2023Prediction of vehicle lane change maneuvers has gained a lot of momentum in the last few years. Some recent works focus on predicting a vehicle's intention by predicting its trajectory first. This is not enough, as it ignores the context of the scene and the state of the surrounding vehicles (as they might be risky to the target vehicle). Other works assessed the risk made by the surrounding vehicles only by considering their existence around the target vehicle, or by considering the distance and relative velocities between them and the target vehicle as two separate numerical features. In this work, we propose a solution that leverages Knowledge Graphs (KGs) to anticipate lane changes based on linguistic contextual information in a way that goes well beyond the capabilities of current perception systems. Our solution takes the Time To Collision (TTC) with surrounding vehicles as input to assess the risk on the target vehicle. Moreover, our KG is trained on the HighD dataset using the TransE model to obtain the Knowledge Graph Embeddings (KGE). Then, we apply Bayesian inference on top of the KG using the embeddings learned during training. Finally, the model can predict lane changes two seconds ahead with 97.95% f1-score, which surpassed the state of the art, and three seconds before changing lanes with 93.60% f1-score.
Concrete Subspace Learning based Interference Elimination for Multi-task Model Fusion
Dec 11, 2023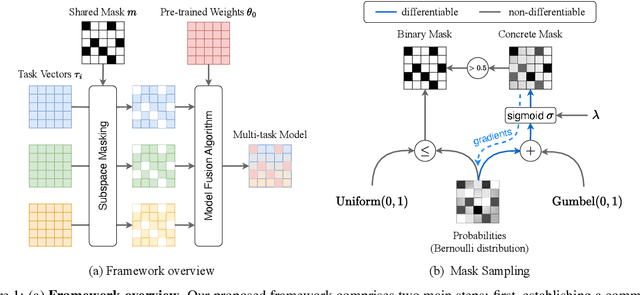
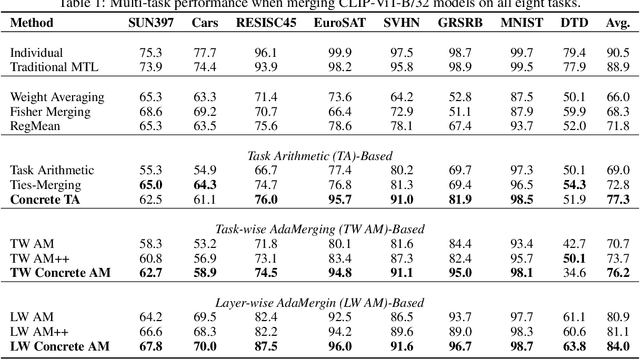
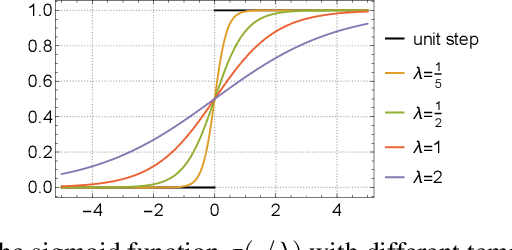

Merging models fine-tuned from a common, extensively pre-trained large model but specialized for different tasks has been demonstrated as a cheap and scalable strategy to construct a multi-task model that performs well across diverse tasks. Recent research, exemplified by task arithmetic, highlights that this multi-task model can be derived through arithmetic operations on task vectors. Nevertheless, current merging techniques frequently resolve potential conflicts among parameters from task-specific models by evaluating individual attributes, such as the parameters' magnitude or sign, overlooking their collective impact on the overall functionality of the model. In this work, we propose the CONtinuous relaxation of disCRETE (Concrete) subspace learning method to identify a common low-dimensional subspace and utilize its shared information to track the interference problem without sacrificing much performance. Specifically, we model the problem as a bi-level optimization problem and introduce a meta-learning framework to find the Concrete subspace mask through gradient-based techniques. At the upper level, we focus on learning a shared Concrete mask to identify the subspace, while at the inner level, model merging is performed to maximize the performance of the merged model. We conduct extensive experiments on both vision domain and language domain, and the results demonstrate the effectiveness of our method. The code is available at https://github.com/tanganke/subspace_fusion
Efficient and Effective Similarity Search over Bipartite Graphs
Dec 11, 2023
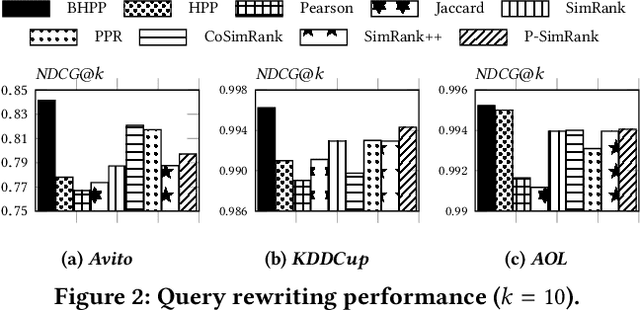
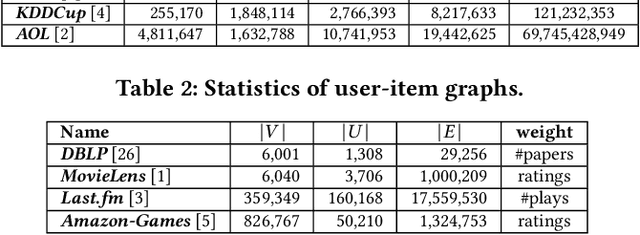
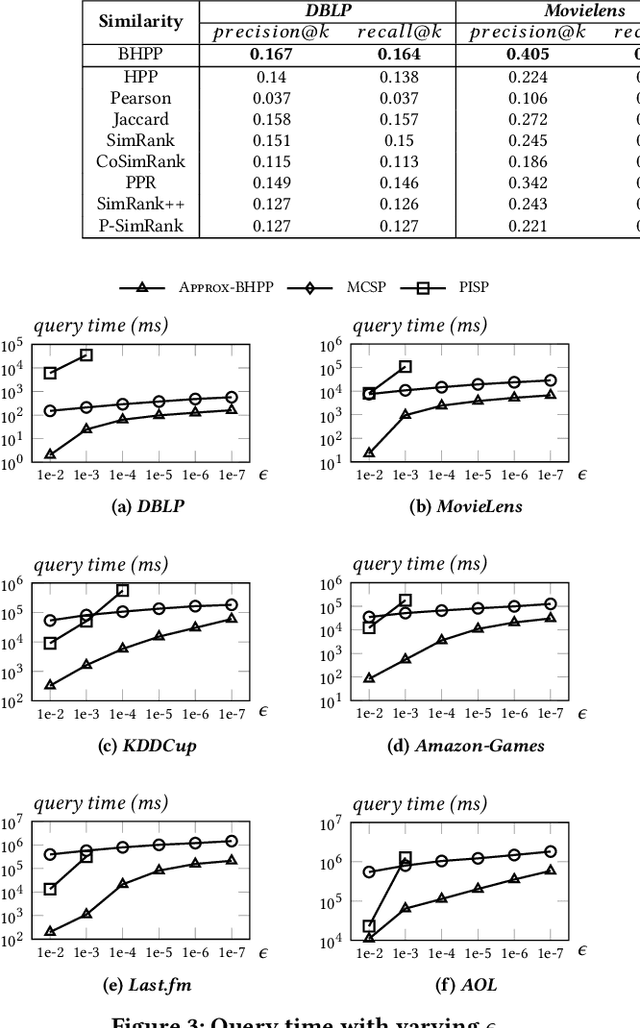
Similarity search over a bipartite graph aims to retrieve from the graph the nodes that are similar to each other, which finds applications in various fields such as online advertising, recommender systems etc. Existing similarity measures either (i) overlook the unique properties of bipartite graphs, or (ii) fail to capture high-order information between nodes accurately, leading to suboptimal result quality. Recently, Hidden Personalized PageRank (HPP) is applied to this problem and found to be more effective compared with prior similarity measures. However, existing solutions for HPP computation incur significant computational costs, rendering it inefficient especially on large graphs. In this paper, we first identify an inherent drawback of HPP and overcome it by proposing bidirectional HPP (BHPP). Then, we formulate similarity search over bipartite graphs as the problem of approximate BHPP computation, and present an efficient solution Approx-BHPP. Specifically, Approx-BHPP offers rigorous theoretical accuracy guarantees with optimal computational complexity by combining deterministic graph traversal with matrix operations in an optimized and non-trivial way. Moreover, our solution achieves significant gain in practical efficiency due to several carefully-designed optimizations. Extensive experiments, comparing BHPP against 8 existing similarity measures over 7 real bipartite graphs, demonstrate the effectiveness of BHPP on query rewriting and item recommendation. Moreover, Approx-BHPP outperforms baseline solutions often by up to orders of magnitude in terms of computational time on both small and large datasets.
VoxelKP: A Voxel-based Network Architecture for Human Keypoint Estimation in LiDAR Data
Dec 11, 2023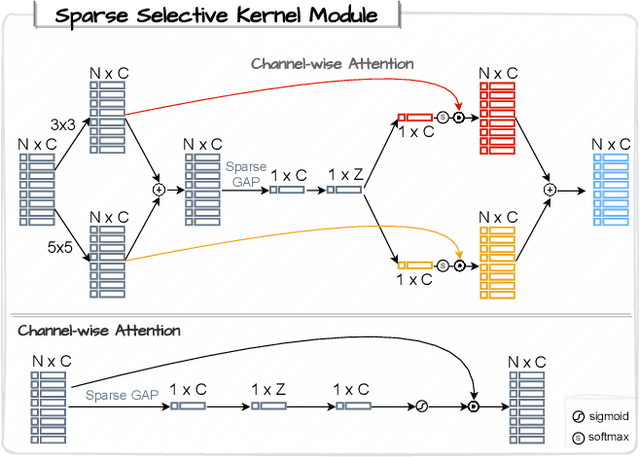
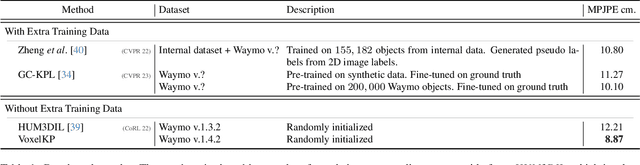
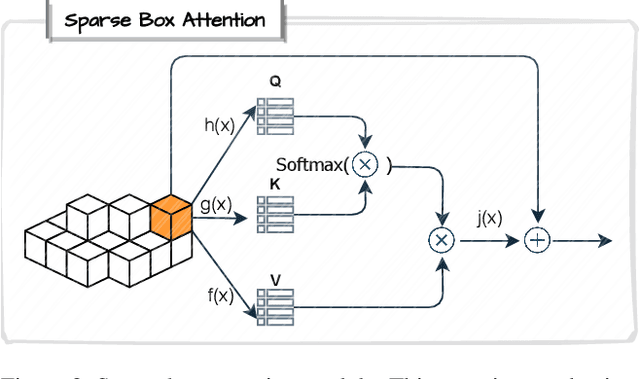
We present \textit{VoxelKP}, a novel fully sparse network architecture tailored for human keypoint estimation in LiDAR data. The key challenge is that objects are distributed sparsely in 3D space, while human keypoint detection requires detailed local information wherever humans are present. We propose four novel ideas in this paper. First, we propose sparse selective kernels to capture multi-scale context. Second, we introduce sparse box-attention to focus on learning spatial correlations between keypoints within each human instance. Third, we incorporate a spatial encoding to leverage absolute 3D coordinates when projecting 3D voxels to a 2D grid encoding a bird's eye view. Finally, we propose hybrid feature learning to combine the processing of per-voxel features with sparse convolution. We evaluate our method on the Waymo dataset and achieve an improvement of $27\%$ on the MPJPE metric compared to the state-of-the-art, \textit{HUM3DIL}, trained on the same data, and $12\%$ against the state-of-the-art, \textit{GC-KPL}, pretrained on a $25\times$ larger dataset. To the best of our knowledge, \textit{VoxelKP} is the first single-staged, fully sparse network that is specifically designed for addressing the challenging task of 3D keypoint estimation from LiDAR data, achieving state-of-the-art performances. Our code is available at \url{https://github.com/shijianjian/VoxelKP}.
DiAD: A Diffusion-based Framework for Multi-class Anomaly Detection
Dec 11, 2023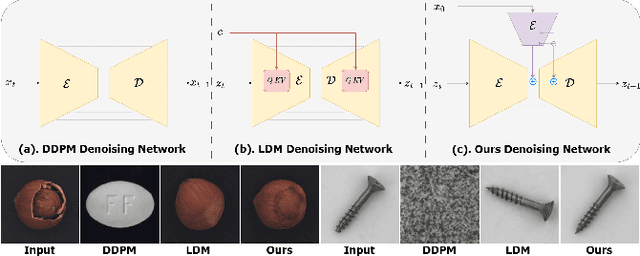
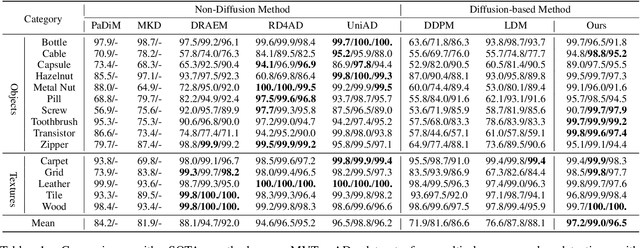
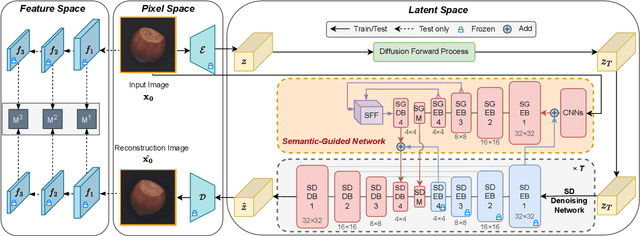

Reconstruction-based approaches have achieved remarkable outcomes in anomaly detection. The exceptional image reconstruction capabilities of recently popular diffusion models have sparked research efforts to utilize them for enhanced reconstruction of anomalous images. Nonetheless, these methods might face challenges related to the preservation of image categories and pixel-wise structural integrity in the more practical multi-class setting. To solve the above problems, we propose a Difusion-based Anomaly Detection (DiAD) framework for multi-class anomaly detection, which consists of a pixel-space autoencoder, a latent-space Semantic-Guided (SG) network with a connection to the stable diffusion's denoising network, and a feature-space pre-trained feature extractor. Firstly, The SG network is proposed for reconstructing anomalous regions while preserving the original image's semantic information. Secondly, we introduce Spatial-aware Feature Fusion (SFF) block to maximize reconstruction accuracy when dealing with extensively reconstructed areas. Thirdly, the input and reconstructed images are processed by a pre-trained feature extractor to generate anomaly maps based on features extracted at different scales. Experiments on MVTec-AD and VisA datasets demonstrate the effectiveness of our approach which surpasses the state-of-the-art methods, e.g., achieving 96.8/52.6 and 97.2/99.0 (AUROC/AP) for localization and detection respectively on multi-class MVTec-AD dataset. Code will be available at https://lewandofskee.github.io/projects/diad.
Non-contact Multimodal Indoor Human Monitoring Systems: A Survey
Dec 11, 2023Indoor human monitoring systems leverage a wide range of sensors, including cameras, radio devices, and inertial measurement units, to collect extensive data from users and the environment. These sensors contribute diverse data modalities, such as video feeds from cameras, received signal strength indicators and channel state information from WiFi devices, and three-axis acceleration data from inertial measurement units. In this context, we present a comprehensive survey of multimodal approaches for indoor human monitoring systems, with a specific focus on their relevance in elderly care. Our survey primarily highlights non-contact technologies, particularly cameras and radio devices, as key components in the development of indoor human monitoring systems. Throughout this article, we explore well-established techniques for extracting features from multimodal data sources. Our exploration extends to methodologies for fusing these features and harnessing multiple modalities to improve the accuracy and robustness of machine learning models. Furthermore, we conduct comparative analysis across different data modalities in diverse human monitoring tasks and undertake a comprehensive examination of existing multimodal datasets. This extensive survey not only highlights the significance of indoor human monitoring systems but also affirms their versatile applications. In particular, we emphasize their critical role in enhancing the quality of elderly care, offering valuable insights into the development of non-contact monitoring solutions applicable to the needs of aging populations.
Model-based Deep Learning for Beam Prediction based on a Channel Chart
Dec 04, 2023Channel charting builds a map of the radio environment in an unsupervised way. The obtained chart locations can be seen as low-dimensional compressed versions of channel state information that can be used for a wide variety of applications, including beam prediction. In non-standalone or cell-free systems, chart locations computed at a given base station can be transmitted to several other base stations (possibly operating at different frequency bands) for them to predict which beams to use. This potentially yields a dramatic reduction of the overhead due to channel estimation or beam management, since only the base station performing charting requires channel state information, the others directly predicting the beam from the chart location. In this paper, advanced model-based neural network architectures are proposed for both channel charting and beam prediction. The proposed methods are assessed on realistic synthetic channels, yielding promising results.