 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Classification of retail products: From probabilistic ranking to neural networks
Dec 12, 2023
Food retailing is now on an accelerated path to a success penetration into the digital market by new ways of value creation at all stages of the consumer decision process. One of the most important imperatives in this path is the availability of quality data to feed all the process in digital transformation. But the quality of data is not so obvious if we consider the variety of products and suppliers in the grocery market. Within this context of digital transformation of grocery industry, \textit{Midiadia} is Spanish data provider company that works on converting data from the retailers' products into knowledge with attributes and insights from the product labels, that is, maintaining quality data in a dynamic market with a high dispersion of products. Currently, they manually categorize products (groceries) according to the information extracted directly (text processing) from the product labelling and packaging. This paper introduces a solution to automatically categorize the constantly changing product catalogue into a 3-level food taxonomy. Our proposal studies three different approaches: a score-based ranking method, traditional machine learning algorithms, and deep neural networks. Thus, we provide four different classifiers that support a more efficient and less error-prone maintenance of groceries catalogues, the main asset of the company. Finally, we have compared the performance of these three alternatives, concluding that traditional machine learning algorithms perform better, but closely followed by the score-based approach.
* 17 pages, 8 figures, journal
Learned representation-guided diffusion models for large-image generation
Dec 12, 2023To synthesize high-fidelity samples, diffusion models typically require auxiliary data to guide the generation process. However, it is impractical to procure the painstaking patch-level annotation effort required in specialized domains like histopathology and satellite imagery; it is often performed by domain experts and involves hundreds of millions of patches. Modern-day self-supervised learning (SSL) representations encode rich semantic and visual information. In this paper, we posit that such representations are expressive enough to act as proxies to fine-grained human labels. We introduce a novel approach that trains diffusion models conditioned on embeddings from SSL. Our diffusion models successfully project these features back to high-quality histopathology and remote sensing images. In addition, we construct larger images by assembling spatially consistent patches inferred from SSL embeddings, preserving long-range dependencies. Augmenting real data by generating variations of real images improves downstream classifier accuracy for patch-level and larger, image-scale classification tasks. Our models are effective even on datasets not encountered during training, demonstrating their robustness and generalizability. Generating images from learned embeddings is agnostic to the source of the embeddings. The SSL embeddings used to generate a large image can either be extracted from a reference image, or sampled from an auxiliary model conditioned on any related modality (e.g. class labels, text, genomic data). As proof of concept, we introduce the text-to-large image synthesis paradigm where we successfully synthesize large pathology and satellite images out of text descriptions.
On the notion of Hallucinations from the lens of Bias and Validity in Synthetic CXR Images
Dec 12, 2023Medical imaging has revolutionized disease diagnosis, yet the potential is hampered by limited access to diverse and privacy-conscious datasets. Open-source medical datasets, while valuable, suffer from data quality and clinical information disparities. Generative models, such as diffusion models, aim to mitigate these challenges. At Stanford, researchers explored the utility of a fine-tuned Stable Diffusion model (RoentGen) for medical imaging data augmentation. Our work examines specific considerations to expand the Stanford research question, Could Stable Diffusion Solve a Gap in Medical Imaging Data? from the lens of bias and validity of the generated outcomes. We leveraged RoentGen to produce synthetic Chest-XRay (CXR) images and conducted assessments on bias, validity, and hallucinations. Diagnostic accuracy was evaluated by a disease classifier, while a COVID classifier uncovered latent hallucinations. The bias analysis unveiled disparities in classification performance among various subgroups, with a pronounced impact on the Female Hispanic subgroup. Furthermore, incorporating race and gender into input prompts exacerbated fairness issues in the generated images. The quality of synthetic images exhibited variability, particularly in certain disease classes, where there was more significant uncertainty compared to the original images. Additionally, we observed latent hallucinations, with approximately 42% of the images incorrectly indicating COVID, hinting at the presence of hallucinatory elements. These identifications provide new research directions towards interpretability of synthetic CXR images, for further understanding of associated risks and patient safety in medical applications.
SM70: A Large Language Model for Medical Devices
Dec 12, 2023We are introducing SM70, a 70 billion-parameter Large Language Model that is specifically designed for SpassMed's medical devices under the brand name 'JEE1' (pronounced as G1 and means 'Life'). This large language model provides more accurate and safe responses to medical-domain questions. To fine-tune SM70, we used around 800K data entries from the publicly available dataset MedAlpaca. The Llama2 70B open-sourced model served as the foundation for SM70, and we employed the QLoRA technique for fine-tuning. The evaluation is conducted across three benchmark datasets - MEDQA - USMLE, PUBMEDQA, and USMLE - each representing a unique aspect of medical knowledge and reasoning. The performance of SM70 is contrasted with other notable LLMs, including Llama2 70B, Clinical Camel 70 (CC70), GPT 3.5, GPT 4, and Med-Palm, to provide a comparative understanding of its capabilities within the medical domain. Our results indicate that SM70 outperforms several established models in these datasets, showcasing its proficiency in handling a range of medical queries, from fact-based questions derived from PubMed abstracts to complex clinical decision-making scenarios. The robust performance of SM70, particularly in the USMLE and PUBMEDQA datasets, suggests its potential as an effective tool in clinical decision support and medical information retrieval. Despite its promising results, the paper also acknowledges the areas where SM70 lags behind the most advanced model, GPT 4, thereby highlighting the need for further development, especially in tasks demanding extensive medical knowledge and intricate reasoning.
A New Perspective On Denoising Based On Optimal Transport
Dec 13, 2023In the standard formulation of the denoising problem, one is given a probabilistic model relating a latent variable $\Theta \in \Omega \subset \mathbb{R}^m \; (m\ge 1)$ and an observation $Z \in \mathbb{R}^d$ according to: $Z \mid \Theta \sim p(\cdot\mid \Theta)$ and $\Theta \sim G^*$, and the goal is to construct a map to recover the latent variable from the observation. The posterior mean, a natural candidate for estimating $\Theta$ from $Z$, attains the minimum Bayes risk (under the squared error loss) but at the expense of over-shrinking the $Z$, and in general may fail to capture the geometric features of the prior distribution $G^*$ (e.g., low dimensionality, discreteness, sparsity, etc.). To rectify these drawbacks, in this paper we take a new perspective on this denoising problem that is inspired by optimal transport (OT) theory and use it to propose a new OT-based denoiser at the population level setting. We rigorously prove that, under general assumptions on the model, our OT-based denoiser is well-defined and unique, and is closely connected to solutions to a Monge OT problem. We then prove that, under appropriate identifiability assumptions on the model, our OT-based denoiser can be recovered solely from information of the marginal distribution of $Z$ and the posterior mean of the model, after solving a linear relaxation problem over a suitable space of couplings that is reminiscent of a standard multimarginal OT (MOT) problem. In particular, thanks to Tweedie's formula, when the likelihood model $\{ p(\cdot \mid \theta) \}_{\theta \in \Omega}$ is an exponential family of distributions, the OT-based denoiser can be recovered solely from the marginal distribution of $Z$. In general, our family of OT-like relaxations is of interest in its own right and for the denoising problem suggests alternative numerical methods inspired by the rich literature on computational OT.
Measuring Information in Text Explanations
Oct 06, 2023Text-based explanation is a particularly promising approach in explainable AI, but the evaluation of text explanations is method-dependent. We argue that placing the explanations on an information-theoretic framework could unify the evaluations of two popular text explanation methods: rationale and natural language explanations (NLE). This framework considers the post-hoc text pipeline as a series of communication channels, which we refer to as ``explanation channels''. We quantify the information flow through these channels, thereby facilitating the assessment of explanation characteristics. We set up tools for quantifying two information scores: relevance and informativeness. We illustrate what our proposed information scores measure by comparing them against some traditional evaluation metrics. Our information-theoretic scores reveal some unique observations about the underlying mechanisms of two representative text explanations. For example, the NLEs trade-off slightly between transmitting the input-related information and the target-related information, whereas the rationales do not exhibit such a trade-off mechanism. Our work contributes to the ongoing efforts in establishing rigorous and standardized evaluation criteria in the rapidly evolving field of explainable AI.
Artificial Intelligence in the automatic coding of interviews on Landscape Quality Objectives. Comparison and case study
Dec 09, 2023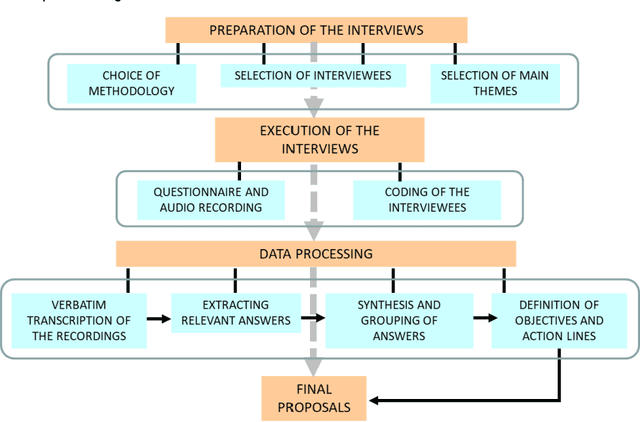
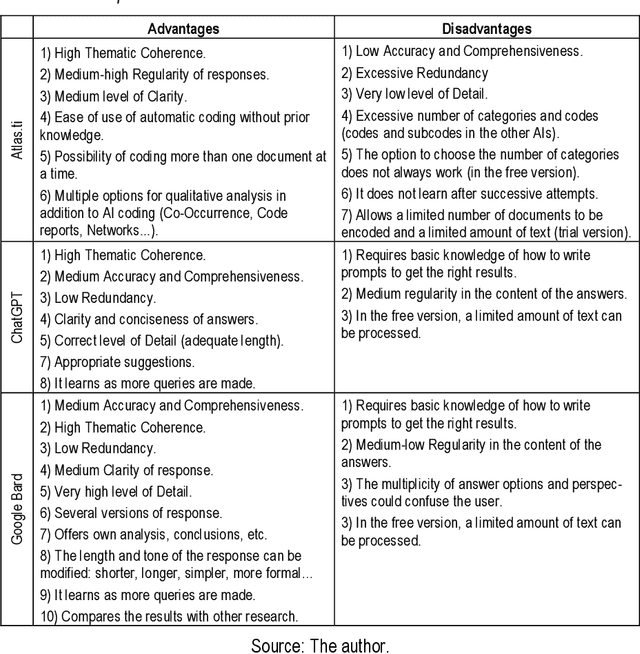
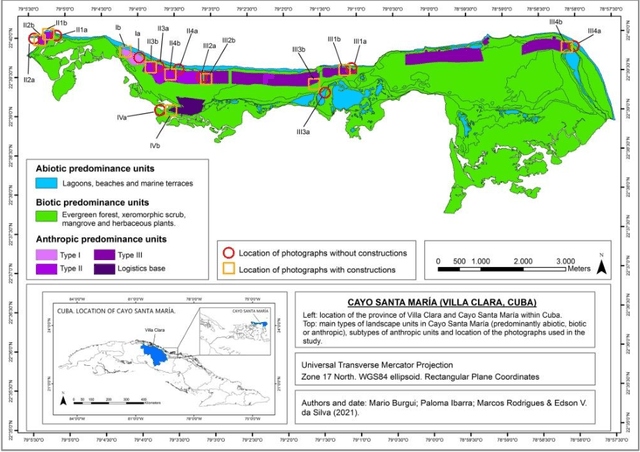
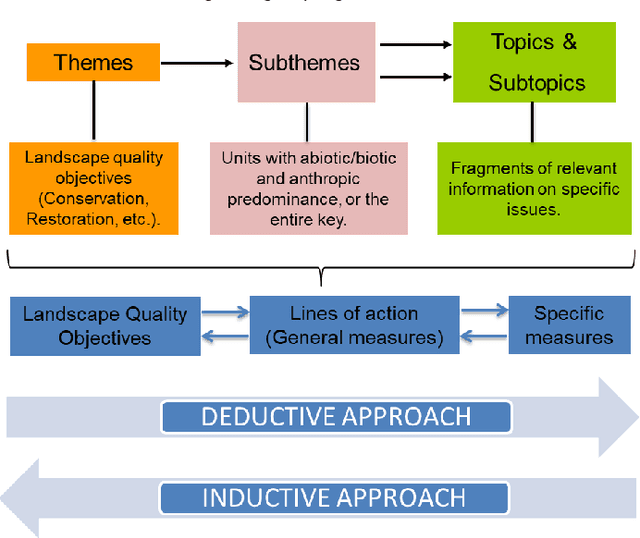
In this study, we conducted a comparative analysis of the automated coding provided by three Artificial Intelligence functionalities (At-las.ti, ChatGPT and Google Bard) in relation to the manual coding of 12 research interviews focused on Landscape Quality Objectives for a small island in the north of Cuba (Cayo Santa Mar\'ia). For this purpose, the following comparison criteria were established: Accuracy, Comprehensiveness, Thematic Coherence, Redundancy, Clarity, Detail and Regularity. The analysis showed the usefulness of AI for the intended purpose, albeit with numerous flaws and shortcomings. In summary, today the automatic coding of AIs can be considered useful as a guide towards a subsequent in-depth and meticulous analysis of the information by the researcher. However, as this is such a recently developed field, rapid evolution is expected to bring the necessary improvements to these tools.
ADOD: Adaptive Domain-Aware Object Detection with Residual Attention for Underwater Environments
Dec 11, 2023This research presents ADOD, a novel approach to address domain generalization in underwater object detection. Our method enhances the model's ability to generalize across diverse and unseen domains, ensuring robustness in various underwater environments. The first key contribution is Residual Attention YOLOv3, a novel variant of the YOLOv3 framework empowered by residual attention modules. These modules enable the model to focus on informative features while suppressing background noise, leading to improved detection accuracy and adaptability to different domains. The second contribution is the attention-based domain classification module, vital during training. This module helps the model identify domain-specific information, facilitating the learning of domain-invariant features. Consequently, ADOD can generalize effectively to underwater environments with distinct visual characteristics. Extensive experiments on diverse underwater datasets demonstrate ADOD's superior performance compared to state-of-the-art domain generalization methods, particularly in challenging scenarios. The proposed model achieves exceptional detection performance in both seen and unseen domains, showcasing its effectiveness in handling domain shifts in underwater object detection tasks. ADOD represents a significant advancement in adaptive object detection, providing a promising solution for real-world applications in underwater environments. With the prevalence of domain shifts in such settings, the model's strong generalization ability becomes a valuable asset for practical underwater surveillance and marine research endeavors.
Sparse but Strong: Crafting Adversarially Robust Graph Lottery Tickets
Dec 11, 2023Graph Lottery Tickets (GLTs), comprising a sparse adjacency matrix and a sparse graph neural network (GNN), can significantly reduce the inference latency and compute footprint compared to their dense counterparts. Despite these benefits, their performance against adversarial structure perturbations remains to be fully explored. In this work, we first investigate the resilience of GLTs against different structure perturbation attacks and observe that they are highly vulnerable and show a large drop in classification accuracy. Based on this observation, we then present an adversarially robust graph sparsification (ARGS) framework that prunes the adjacency matrix and the GNN weights by optimizing a novel loss function capturing the graph homophily property and information associated with both the true labels of the train nodes and the pseudo labels of the test nodes. By iteratively applying ARGS to prune both the perturbed graph adjacency matrix and the GNN model weights, we can find adversarially robust graph lottery tickets that are highly sparse yet achieve competitive performance under different untargeted training-time structure attacks. Evaluations conducted on various benchmarks, considering different poisoning structure attacks, namely, PGD, MetaAttack, Meta-PGD, and PR-BCD demonstrate that the GLTs generated by ARGS can significantly improve the robustness, even when subjected to high levels of sparsity.
Point Transformer with Federated Learning for Predicting Breast Cancer HER2 Status from Hematoxylin and Eosin-Stained Whole Slide Images
Dec 11, 2023Directly predicting human epidermal growth factor receptor 2 (HER2) status from widely available hematoxylin and eosin (HE)-stained whole slide images (WSIs) can reduce technical costs and expedite treatment selection. Accurately predicting HER2 requires large collections of multi-site WSIs. Federated learning enables collaborative training of these WSIs without gigabyte-size WSIs transportation and data privacy concerns. However, federated learning encounters challenges in addressing label imbalance in multi-site WSIs from the real world. Moreover, existing WSI classification methods cannot simultaneously exploit local context information and long-range dependencies in the site-end feature representation of federated learning. To address these issues, we present a point transformer with federated learning for multi-site HER2 status prediction from HE-stained WSIs. Our approach incorporates two novel designs. We propose a dynamic label distribution strategy and an auxiliary classifier, which helps to establish a well-initialized model and mitigate label distribution variations across sites. Additionally, we propose a farthest cosine sampling based on cosine distance. It can sample the most distinctive features and capture the long-range dependencies. Extensive experiments and analysis show that our method achieves state-of-the-art performance at four sites with a total of 2687 WSIs. Furthermore, we demonstrate that our model can generalize to two unseen sites with 229 WSIs.