 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Twitter Permeability to financial events: an experiment towards a model for sensing irregularities
Dec 14, 2023
There is a general consensus of the good sensing and novelty characteristics of Twitter as an information media for the complex financial market. This paper investigates the permeability of Twittersphere, the total universe of Twitter users and their habits, towards relevant events in the financial market. Analysis shows that a general purpose social media is permeable to financial-specific events and establishes Twitter as a relevant feeder for taking decisions regarding the financial market and event fraudulent activities in that market. However, the provenance of contributions, their different levels of credibility and quality and even the purpose or intention behind them should to be considered and carefully contemplated if Twitter is used as a single source for decision taking. With the overall aim of this research, to deploy an architecture for real-time monitoring of irregularities in the financial market, this paper conducts a series of experiments on the level of permeability and the permeable features of Twitter in the event of one of these irregularities. To be precise, Twitter data is collected concerning an event comprising of a specific financial action on the 27th January 2017:{~ }the announcement about the merge of two companies Tesco PLC and Booker Group PLC, listed in the main market of the London Stock Exchange (LSE), to create the UK's Leading Food Business. The experiment attempts to answer five key research questions which aim to characterize the features of Twitter permeability to the financial market. The experimental results confirm that a far-impacting financial event, such as the merger considered, caused apparent disturbances in all the features considered, that is, information volume, content and sentiment as well as geographical provenance. Analysis shows that despite, Twitter not being a specific financial forum, it is permeable to financial events.
Exploiting Label Skews in Federated Learning with Model Concatenation
Dec 16, 2023Federated Learning (FL) has emerged as a promising solution to perform deep learning on different data owners without exchanging raw data. However, non-IID data has been a key challenge in FL, which could significantly degrade the accuracy of the final model. Among different non-IID types, label skews have been challenging and common in image classification and other tasks. Instead of averaging the local models in most previous studies, we propose FedConcat, a simple and effective approach that concatenates these local models as the base of the global model to effectively aggregate the local knowledge. To reduce the size of the global model, we adopt the clustering technique to group the clients by their label distributions and collaboratively train a model inside each cluster. We theoretically analyze the advantage of concatenation over averaging by analyzing the information bottleneck of deep neural networks. Experimental results demonstrate that FedConcat achieves significantly higher accuracy than previous state-of-the-art FL methods in various heterogeneous label skew distribution settings and meanwhile has lower communication costs. Our code is publicly available at https://github.com/sjtudyq/FedConcat.
ElasticLaneNet: A Geometry-Flexible Approach for Lane Detection
Dec 16, 2023The task of lane detection involves identifying the boundaries of driving areas. Recognizing lanes with complex and variable geometric structures remains a challenge. In this paper, we introduce a new lane detection framework named ElasticLaneNet (Elastic-interaction-energy guided Lane detection Network). A novel and flexible way of representing lanes, namely, implicit representation is proposed. The training strategy considers predicted lanes as moving curves that being attracted to the ground truth guided by an elastic interaction energy based loss function (EIE loss). An auxiliary feature refinement (AFR) module is designed to gather information from different layers. The method performs well in complex lane scenarios, including those with large curvature, weak geometric features at intersections, complicated cross lanes, Y-shapes lanes, dense lanes, etc. We apply our approach on three datasets: SDLane, CULane, and TuSimple. The results demonstrate the exceptional performance of our method, with the state-of-the-art results on the structure-diversity dataset SDLane, achieving F1-score of 89.51, Recall rate of 87.50, and Precision of 91.61.
Inductive Link Prediction in Knowledge Graphs using Path-based Neural Networks
Dec 16, 2023Link prediction is a crucial research area in knowledge graphs, with many downstream applications. In many real-world scenarios, inductive link prediction is required, where predictions have to be made among unseen entities. Embedding-based models usually need fine-tuning on new entity embeddings, and hence are difficult to be directly applied to inductive link prediction tasks. Logical rules captured by rule-based models can be directly applied to new entities with the same graph typologies, but the captured rules are discrete and usually lack generosity. Graph neural networks (GNNs) can generalize topological information to new graphs taking advantage of deep neural networks, which however may still need fine-tuning on new entity embeddings. In this paper, we propose SiaILP, a path-based model for inductive link prediction using siamese neural networks. Our model only depends on relation and path embeddings, which can be generalized to new entities without fine-tuning. Experiments show that our model achieves several new state-of-the-art performances in link prediction tasks using inductive versions of WN18RR, FB15k-237, and Nell995.
Transformer-based No-Reference Image Quality Assessment via Supervised Contrastive Learning
Dec 12, 2023Image Quality Assessment (IQA) has long been a research hotspot in the field of image processing, especially No-Reference Image Quality Assessment (NR-IQA). Due to the powerful feature extraction ability, existing Convolution Neural Network (CNN) and Transformers based NR-IQA methods have achieved considerable progress. However, they still exhibit limited capability when facing unknown authentic distortion datasets. To further improve NR-IQA performance, in this paper, a novel supervised contrastive learning (SCL) and Transformer-based NR-IQA model SaTQA is proposed. We first train a model on a large-scale synthetic dataset by SCL (no image subjective score is required) to extract degradation features of images with various distortion types and levels. To further extract distortion information from images, we propose a backbone network incorporating the Multi-Stream Block (MSB) by combining the CNN inductive bias and Transformer long-term dependence modeling capability. Finally, we propose the Patch Attention Block (PAB) to obtain the final distorted image quality score by fusing the degradation features learned from contrastive learning with the perceptual distortion information extracted by the backbone network. Experimental results on seven standard IQA datasets show that SaTQA outperforms the state-of-the-art methods for both synthetic and authentic datasets. Code is available at https://github.com/I2-Multimedia-Lab/SaTQA
Modeling Uncertainty in Personalized Emotion Prediction with Normalizing Flows
Dec 10, 2023Designing predictive models for subjective problems in natural language processing (NLP) remains challenging. This is mainly due to its non-deterministic nature and different perceptions of the content by different humans. It may be solved by Personalized Natural Language Processing (PNLP), where the model exploits additional information about the reader to make more accurate predictions. However, current approaches require complete information about the recipients to be straight embedded. Besides, the recent methods focus on deterministic inference or simple frequency-based estimations of the probabilities. In this work, we overcome this limitation by proposing a novel approach to capture the uncertainty of the forecast using conditional Normalizing Flows. This allows us to model complex multimodal distributions and to compare various models using negative log-likelihood (NLL). In addition, the new solution allows for various interpretations of possible reader perception thanks to the available sampling function. We validated our method on three challenging, subjective NLP tasks, including emotion recognition and hate speech. The comparative analysis of generalized and personalized approaches revealed that our personalized solutions significantly outperform the baseline and provide more precise uncertainty estimates. The impact on the text interpretability and uncertainty studies are presented as well. The information brought by the developed methods makes it possible to build hybrid models whose effectiveness surpasses classic solutions. In addition, an analysis and visualization of the probabilities of the given decisions for texts with high entropy of annotations and annotators with mixed views were carried out.
Hypergraph-Guided Disentangled Spectrum Transformer Networks for Near-Infrared Facial Expression Recognition
Dec 10, 2023
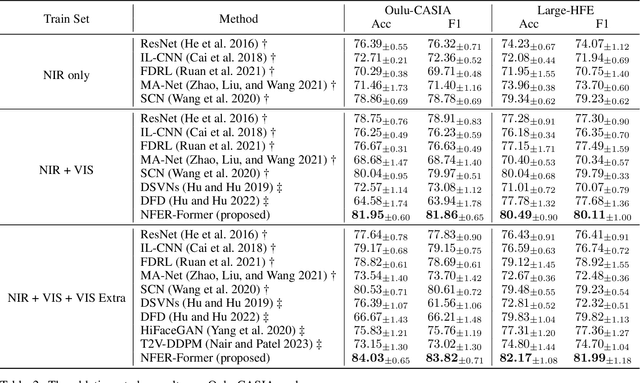
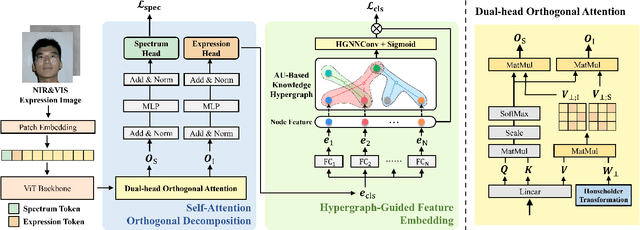
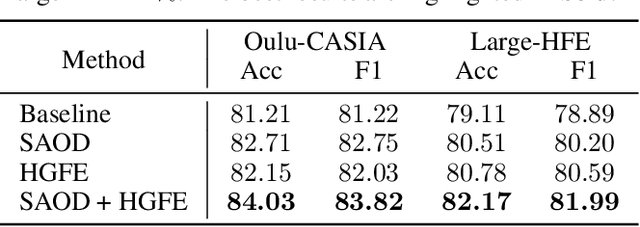
With the strong robusticity on illumination variations, near-infrared (NIR) can be an effective and essential complement to visible (VIS) facial expression recognition in low lighting or complete darkness conditions. However, facial expression recognition (FER) from NIR images presents more challenging problem than traditional FER due to the limitations imposed by the data scale and the difficulty of extracting discriminative features from incomplete visible lighting contents. In this paper, we give the first attempt to deep NIR facial expression recognition and proposed a novel method called near-infrared facial expression transformer (NFER-Former). Specifically, to make full use of the abundant label information in the field of VIS, we introduce a Self-Attention Orthogonal Decomposition mechanism that disentangles the expression information and spectrum information from the input image, so that the expression features can be extracted without the interference of spectrum variation. We also propose a Hypergraph-Guided Feature Embedding method that models some key facial behaviors and learns the structure of the complex correlations between them, thereby alleviating the interference of inter-class similarity. Additionally, we have constructed a large NIR-VIS Facial Expression dataset that includes 360 subjects to better validate the efficiency of NFER-Former. Extensive experiments and ablation studies show that NFER-Former significantly improves the performance of NIR FER and achieves state-of-the-art results on the only two available NIR FER datasets, Oulu-CASIA and Large-HFE.
DRDT: Dynamic Reflection with Divergent Thinking for LLM-based Sequential Recommendation
Dec 18, 2023The rise of Large Language Models (LLMs) has sparked interest in their application to sequential recommendation tasks as they can provide supportive item information. However, due to the inherent complexities of sequential recommendation, such as sequential patterns across datasets, noise within sequences, and the temporal evolution of user preferences, existing LLM reasoning strategies, such as in-context learning and chain-of-thought are not fully effective. To address these challenges, we introduce a novel reasoning principle: Dynamic Reflection with Divergent Thinking within a retriever-reranker framework. Our approach starts with a collaborative in-context demonstration retriever, which collects sequences exhibiting collaborative behaviors as in-context examples. Following this, we abstract high-level user preferences across multiple aspects, providing a more nuanced understanding of user interests and circumventing the noise within the raw sequences. The cornerstone of our methodology is dynamic reflection, a process that emulates human learning through probing, critiquing, and reflecting, using user feedback to tailor the analysis more effectively to the target user in a temporal manner. We evaluate our approach on three datasets using six pre-trained LLMs. The superior performance observed across these models demonstrates the efficacy of our reasoning strategy, notably achieved without the need to fine-tune the LLMs. With our principle, we managed to outperform GPT-Turbo-3.5 on three datasets using 7b models e.g., Vicuna-7b and Openchat-7b on NDCG@10. This research not only highlights the potential of LLMs in enhancing sequential recommendation systems but also underscores the importance of developing tailored reasoning strategies to fully harness their capabilities.
LLM-ARK: Knowledge Graph Reasoning Using Large Language Models via Deep Reinforcement Learning
Dec 18, 2023With the evolution of pre-training methods, large language models (LLMs) have exhibited exemplary reasoning capabilities via prompt engineering. However, the absence of Knowledge Graph (KG) environment awareness and the challenge of engineering viable optimization mechanisms for intermediary reasoning processes, constrict the performance of LLMs on KG reasoning tasks compared to smaller models. We introduce LLM-ARK, a LLM grounded KG reasoning agent designed to deliver precise and adaptable predictions on KG paths. LLM-ARK utilizes Full Textual Environment (FTE) prompts to assimilate state information for each step-sized intelligence. Leveraging LLMs to richly encode and represent various types of inputs and integrate the knowledge graph further with path environment data, before making the final decision. Reframing the Knowledge Graph (KG) multi-hop inference problem as a sequential decision-making issue, we optimize our model using the Proximal Policy Optimization (PPO) online policy gradient reinforcement learning algorithm which allows the model to learn from a vast array of reward signals across diverse tasks and environments. We evaluate state-of-the-art LLM(GPT-4) and our method which using open-source models of varying sizes on OpenDialKG dataset. Our experiment shows that LLaMA7B-ARK provides excellent results with a performance rate of 48.75% for the target@1 evaluation metric, far exceeding the current state-of-the-art model by 17.64 percentage points. Meanwhile, GPT-4 accomplished a score of only 14.91%, further highlighting the efficacy and complexity of our methodology. Our code is available on GitHub for further access.
Deep Learning Approaches for Seizure Video Analysis: A Review
Dec 18, 2023Seizure events may manifest as transient disruptions in movement and behavior, and the analysis of these clinical signs, referred to as semiology, is subject to observer variations when specialists evaluate video-recorded events in the clinical setting. To enhance the accuracy and consistency of evaluations, computer-aided video analysis of seizures has emerged as a natural avenue. In the field of medical applications, deep learning and computer vision approaches have driven substantial advancements. Historically, these approaches have been used for disease detection, classification, and prediction using diagnostic data; however, there has been limited exploration of their application in evaluating video-based motion detection in the clinical epileptology setting. While vision-based technologies do not aim to replace clinical expertise, they can significantly contribute to medical decision-making and patient care by providing quantitative evidence and decision support. Behavior monitoring tools offer several advantages such as providing objective information, detecting challenging-to-observe events, reducing documentation efforts, and extending assessment capabilities to areas with limited expertise. In this paper, we detail the foundation technologies used in vision-based systems in the analysis of seizure videos, highlighting their success in semiology detection and analysis, focusing on work published in the last 7 years. We systematically present these methods and indicate how the adoption of deep learning for the analysis of video recordings of seizures could be approached. Additionally, we illustrate how existing technologies can be interconnected through an integrated system for video-based semiology analysis. Finally, we discuss challenges and research directions for future studies.