 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PnPNet: Pull-and-Push Networks for Volumetric Segmentation with Boundary Confusion
Dec 13, 2023
Precise boundary segmentation of volumetric images is a critical task for image-guided diagnosis and computer-assisted intervention, especially for boundary confusion in clinical practice. However, U-shape networks cannot effectively resolve this challenge due to the lack of boundary shape constraints. Besides, existing methods of refining boundaries overemphasize the slender structure, which results in the overfitting phenomenon due to networks' limited abilities to model tiny objects. In this paper, we reconceptualize the mechanism of boundary generation by encompassing the interaction dynamics with adjacent regions. Moreover, we propose a unified network termed PnPNet to model shape characteristics of the confused boundary region. Core ingredients of PnPNet contain the pushing and pulling branches. Specifically, based on diffusion theory, we devise the semantic difference module (SDM) from the pushing branch to squeeze the boundary region. Explicit and implicit differential information inside SDM significantly boost representation abilities for inter-class boundaries. Additionally, motivated by the K-means algorithm, the class clustering module (CCM) from the pulling branch is introduced to stretch the intersected boundary region. Thus, pushing and pulling branches will shrink and enlarge the boundary uncertainty respectively. They furnish two adversarial forces to promote models to output a more precise delineation of boundaries. We carry out experiments on three challenging public datasets and one in-house dataset, containing three types of boundary confusion in model predictions. Experimental results demonstrate the superiority of PnPNet over other segmentation networks, especially on evaluation metrics of HD and ASSD. Besides, pushing and pulling branches can serve as plug-and-play modules to enhance classic U-shape baseline models. Codes are available.
STF: Spatial Temporal Fusion for Trajectory Prediction
Nov 29, 2023Trajectory prediction is a challenging task that aims to predict the future trajectory of vehicles or pedestrians over a short time horizon based on their historical positions. The main reason is that the trajectory is a kind of complex data, including spatial and temporal information, which is crucial for accurate prediction. Intuitively, the more information the model can capture, the more precise the future trajectory can be predicted. However, previous works based on deep learning methods processed spatial and temporal information separately, leading to inadequate spatial information capture, which means they failed to capture the complete spatial information. Therefore, it is of significance to capture information more fully and effectively on vehicle interactions. In this study, we introduced an integrated 3D graph that incorporates both spatial and temporal edges. Based on this, we proposed the integrated 3D graph, which considers the cross-time interaction information. In specific, we design a Spatial-Temporal Fusion (STF) model including Multi-layer perceptions (MLP) and Graph Attention (GAT) to capture the spatial and temporal information historical trajectories simultaneously on the 3D graph. Our experiment on the ApolloScape Trajectory Datasets shows that the proposed STF outperforms several baseline methods, especially on the long-time-horizon trajectory prediction.
Dynamic interactive group decision making method on two-dimensional language
Nov 29, 2023The language evaluation information of the interactive group decision method at present is based on the one-dimension language variable. At the same time, multi-attribute group decision making method based on two-dimension linguistic information only use single-stage and static evaluation method. In this paper, we propose a dynamic group decision making method based on two-dimension linguistic information, combining dynamic interactive group decision making methods with two-dimensional language evaluation information The method first use Two-Dimensional Uncertain Linguistic Generalized Weighted Aggregation (DULGWA) Operators to aggregate the preference information of each decision maker, then adopting dynamic information entropy method to obtain weights of attributes at each stage. Finally we propose the group consistency index to quantify the termination conditions of group interaction. One example is given to verify the developed approach and to demonstrate its effectiveness
Passive Integrated Sensing and Communication Scheme based on RF Fingerprint Information Extraction for Cell-Free RAN
Nov 10, 2023This paper investigates how to achieve integrated sensing and communication (ISAC) based on a cell-free radio access network (CF-RAN) architecture with a minimum footprint of communication resources. We propose a new passive sensing scheme. The scheme is based on the radio frequency (RF) fingerprint learning of the RF radio unit (RRU) to build an RF fingerprint library of RRUs. The source RRU is identified by comparing the RF fingerprints carried by the signal at the receiver side. The receiver extracts the channel parameters from the signal and estimates the channel environment, thus locating the reflectors in the environment. The proposed scheme can effectively solve the problem of interference between signals in the same time-frequency domain but in different spatial domains when multiple RRUs jointly serve users in CF-RAN architecture. Simulation results show that the proposed passive ISAC scheme can effectively detect reflector location information in the environment without degrading the communication performance.
Instruct and Extract: Instruction Tuning for On-Demand Information Extraction
Oct 24, 2023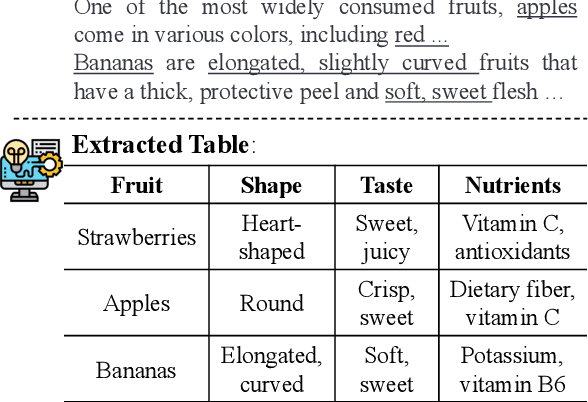
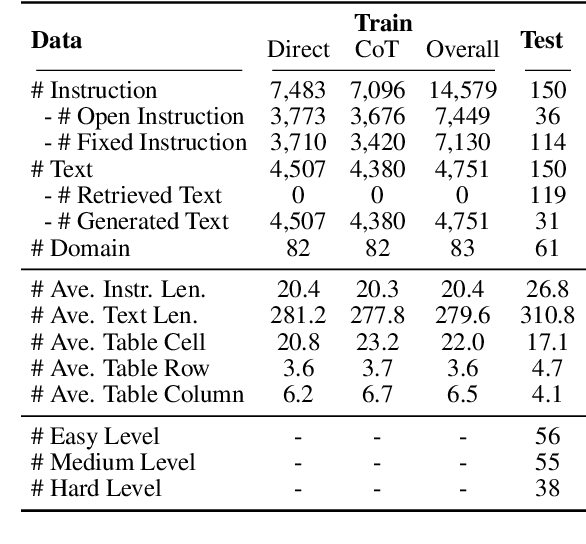
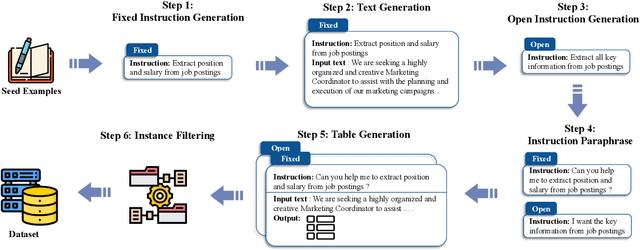
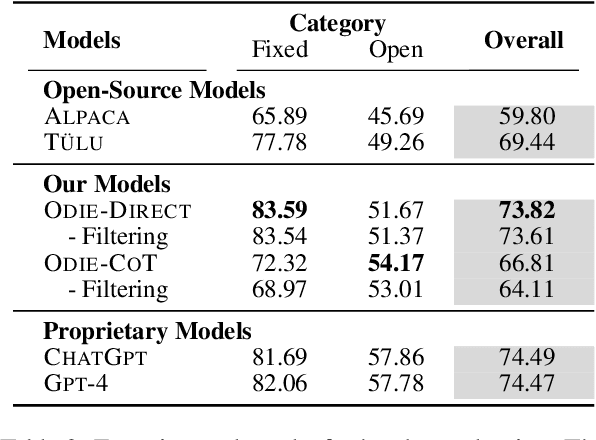
Large language models with instruction-following capabilities open the door to a wider group of users. However, when it comes to information extraction - a classic task in natural language processing - most task-specific systems cannot align well with long-tail ad hoc extraction use cases for non-expert users. To address this, we propose a novel paradigm, termed On-Demand Information Extraction, to fulfill the personalized demands of real-world users. Our task aims to follow the instructions to extract the desired content from the associated text and present it in a structured tabular format. The table headers can either be user-specified or inferred contextually by the model. To facilitate research in this emerging area, we present a benchmark named InstructIE, inclusive of both automatically generated training data, as well as the human-annotated test set. Building on InstructIE, we further develop an On-Demand Information Extractor, ODIE. Comprehensive evaluations on our benchmark reveal that ODIE substantially outperforms the existing open-source models of similar size. Our code and dataset are released on https://github.com/yzjiao/On-Demand-IE.
Jointly spatial-temporal representation learning for individual trajectories
Dec 07, 2023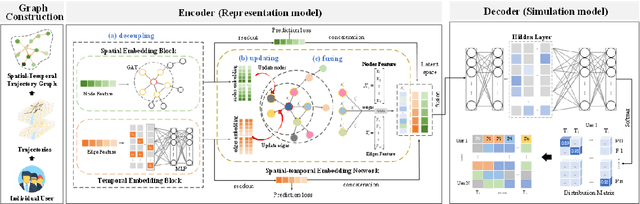
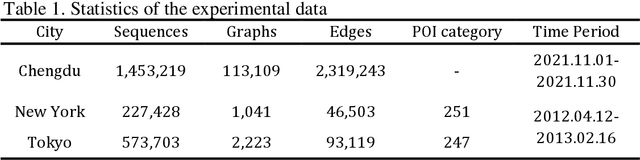
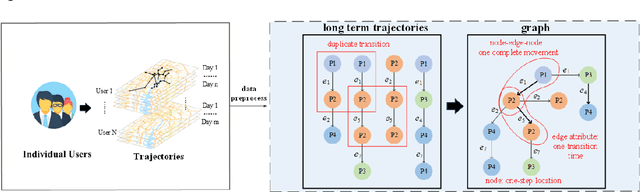
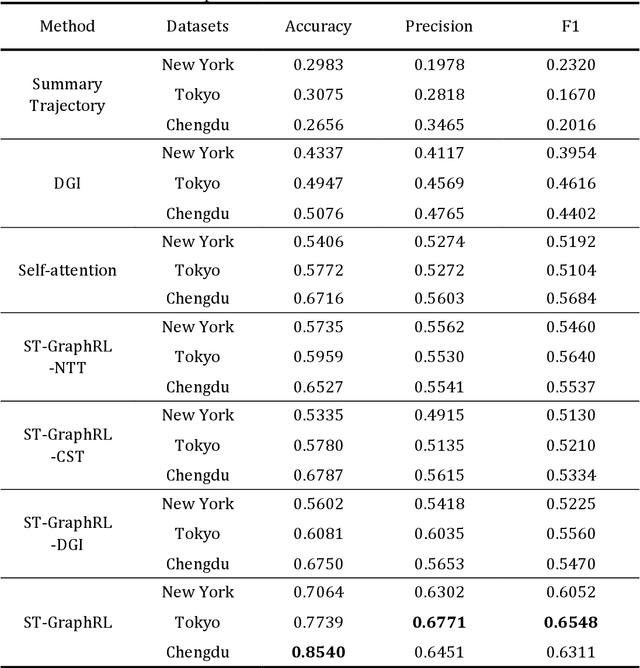
Individual trajectories, containing substantial information on human-environment interactions across space and time, is a crucial input for geospatial foundation models (GeoFMs). However, existing attempts, leveraging trajectory data for various applications have overlooked the implicit spatial-temporal dependency within trajectories and failed to encode and represent it in a format friendly to deep learning, posing a challenge in obtaining general-purpose trajectory representations. Therefore, this paper proposes a spatial-temporal joint representation learning method (ST-GraphRL) to formalize learnable spatial-temporal dependencies into trajectory representations. The proposed ST-GraphRL consists of three compositions: (i) a weighted directed spatial-temporal graph to explicitly construct mobility interactions over both space and time dimensions; (ii) a two-stage jointly encoder (i.e., decoupling and fusion) to learn entangled spatial-temporal dependencies by independently decomposing and jointly aggregating space and time information; (iii) a decoder guides ST-GraphRL to learn explicit mobility regularities by simulating the spatial-temporal distributions of trajectories. Tested on three real-world human mobility datasets, the proposed ST-GraphRL outperformed all the baseline models in predicting movement spatial-temporal distributions and preserving trajectory similarity with high spatial-temporal correlations. We also explore how spatial-temporal features presented in latent space, validating that ST-GraphRL understands spatial-temporal patterns. This method is also transferable for general-purpose geospatial data representations for broad downstream tasks, as well advancing GeoFMs developing.
Interactive Dual-Conformer with Scene-Inspired Mask for Soft Sound Event Detection
Dec 07, 2023Traditional binary hard labels for sound event detection (SED) lack details about the complexity and variability of sound event distributions. Recently, a novel annotation workflow is proposed to generate fine-grained non-binary soft labels, resulting in a new real-life dataset named MAESTRO Real for SED. In this paper, we first propose an interactive dual-conformer (IDC) module, in which a cross-interaction mechanism is applied to effectively exploit the information from soft labels. In addition, a novel scene-inspired mask (SIM) based on soft labels is incorporated for more precise SED predictions. The SIM is initially generated through a statistical approach, referred as SIM-V1. However, the fixed artificial mask may mismatch the SED model, resulting in limited effectiveness. Therefore, we further propose SIM-V2, which employs a word embedding model for adaptive SIM estimation. Experimental results show that the proposed IDC module can effectively utilize the information from soft labels, and the integration of SIM-V1 can further improve the accuracy. In addition, the impact of different word embedding dimensions on SIM-V2 is explored, and the results show that the appropriate dimension can enable SIM-V2 achieve superior performance than SIM-V1. In DCASE 2023 Challenge Task4B, the proposed system achieved the top ranking performance on the evaluation dataset of MAESTRO Real.
LiDAR-based Person Re-identification
Dec 11, 2023Camera-based person re-identification (ReID) systems have been widely applied in the field of public security. However, cameras often lack the perception of 3D morphological information of human and are susceptible to various limitations, such as inadequate illumination, complex background, and personal privacy. In this paper, we propose a LiDAR-based ReID framework, ReID3D, that utilizes pre-training strategy to retrieve features of 3D body shape and introduces Graph-based Complementary Enhancement Encoder for extracting comprehensive features. Due to the lack of LiDAR datasets, we build LReID, the first LiDAR-based person ReID dataset, which is collected in several outdoor scenes with variations in natural conditions. Additionally, we introduce LReID-sync, a simulated pedestrian dataset designed for pre-training encoders with tasks of point cloud completion and shape parameter learning. Extensive experiments on LReID show that ReID3D achieves exceptional performance with a rank-1 accuracy of 94.0, highlighting the significant potential of LiDAR in addressing person ReID tasks. To the best of our knowledge, we are the first to propose a solution for LiDAR-based ReID. The code and datasets will be released soon.
MMDesign: Multi-Modality Transfer Learning for Generative Protein Design
Dec 11, 2023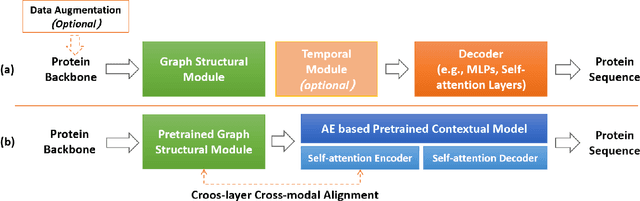
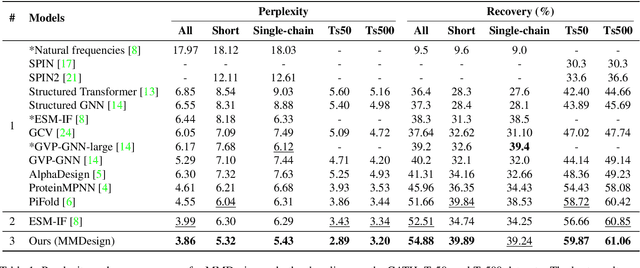
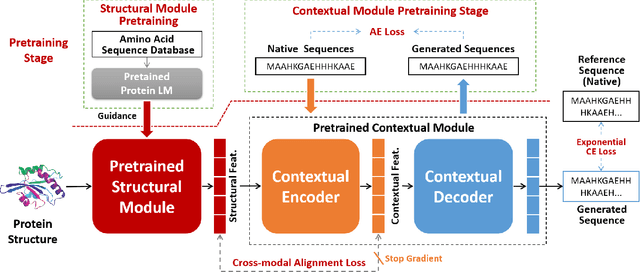
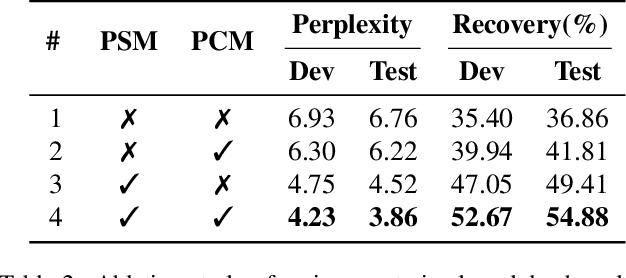
Protein design involves generating protein sequences based on their corresponding protein backbones. While deep generative models show promise for learning protein design directly from data, the lack of publicly available structure-sequence pairings limits their generalization capabilities. Previous efforts of generative protein design have focused on architectural improvements and pseudo-data augmentation to overcome this bottleneck. To further address this challenge, we propose a novel protein design paradigm called MMDesign, which leverages multi-modality transfer learning. To our knowledge, MMDesign is the first framework that combines a pretrained structural module with a pretrained contextual module, using an auto-encoder (AE) based language model to incorporate prior semantic knowledge of protein sequences. We also introduce a cross-layer cross-modal alignment algorithm to enable the structural module to learn long-term temporal information and ensure consistency between structural and contextual modalities. Experimental results, only training with the small CATH dataset, demonstrate that our MMDesign framework consistently outperforms other baselines on various public test sets. To further assess the biological plausibility of the generated protein sequences and data distribution, we present systematic quantitative analysis techniques that provide interpretability and reveal more about the laws of protein design.
Why "classic" Transformers are shallow and how to make them go deep
Dec 11, 2023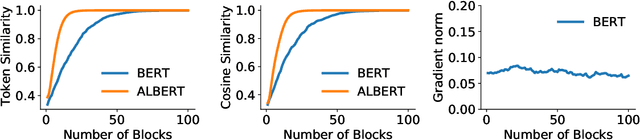

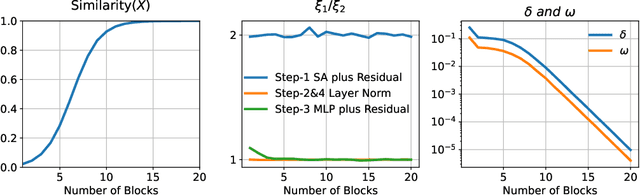
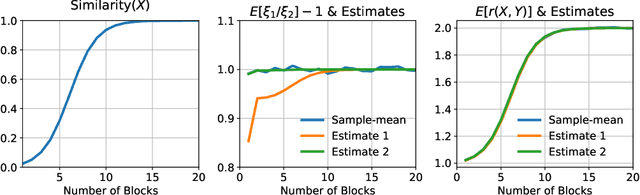
Since its introduction in 2017, Transformer has emerged as the leading neural network architecture, catalyzing revolutionary advancements in many AI disciplines. The key innovation in Transformer is a Self-Attention (SA) mechanism designed to capture contextual information. However, extending the original Transformer design to models of greater depth has proven exceedingly challenging, if not impossible. Even though various modifications have been proposed in order to stack more layers of SA mechanism into deeper models, a full understanding of this depth problem remains elusive. In this paper, we conduct a comprehensive investigation, both theoretically and empirically, to substantiate the claim that the depth problem is caused by \emph{token similarity escalation}; that is, tokens grow increasingly alike after repeated applications of the SA mechanism. Our analysis reveals that, driven by the invariant leading eigenspace and large spectral gaps of attention matrices, token similarity provably escalates at a linear rate. Based on the gained insight, we propose a simple strategy that, unlike most existing methods, surgically removes excessive similarity without discounting the SA mechanism as a whole. Preliminary experimental results confirm the effectiveness of the proposed approach on moderate-scale post-norm Transformer models.