 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Look Before You Leap: A Universal Emergent Decomposition of Retrieval Tasks in Language Models
Dec 13, 2023
When solving challenging problems, language models (LMs) are able to identify relevant information from long and complicated contexts. To study how LMs solve retrieval tasks in diverse situations, we introduce ORION, a collection of structured retrieval tasks spanning six domains, from text understanding to coding. Each task in ORION can be represented abstractly by a request (e.g. a question) that retrieves an attribute (e.g. the character name) from a context (e.g. a story). We apply causal analysis on 18 open-source language models with sizes ranging from 125 million to 70 billion parameters. We find that LMs internally decompose retrieval tasks in a modular way: middle layers at the last token position process the request, while late layers retrieve the correct entity from the context. After causally enforcing this decomposition, models are still able to solve the original task, preserving 70% of the original correct token probability in 98 of the 106 studied model-task pairs. We connect our macroscopic decomposition with a microscopic description by performing a fine-grained case study of a question-answering task on Pythia-2.8b. Building on our high-level understanding, we demonstrate a proof of concept application for scalable internal oversight of LMs to mitigate prompt-injection while requiring human supervision on only a single input. Our solution improves accuracy drastically (from 15.5% to 97.5% on Pythia-12b). This work presents evidence of a universal emergent modular processing of tasks across varied domains and models and is a pioneering effort in applying interpretability for scalable internal oversight of LMs.
Comparing YOLOv8 and Mask RCNN for object segmentation in complex orchard environments
Dec 13, 2023Instance segmentation, an important image processing operation for automation in agriculture, is used to precisely delineate individual objects of interest within images, which provides foundational information for various automated or robotic tasks such as selective harvesting and precision pruning. This study compares the one-stage YOLOv8 and the two-stage Mask R-CNN machine learning models for instance segmentation under varying orchard conditions across two datasets. Dataset 1, collected in dormant season, includes images of dormant apple trees, which were used to train multi-object segmentation models delineating tree branches and trunks. Dataset 2, collected in the early growing season, includes images of apple tree canopies with green foliage and immature (green) apples (also called fruitlet), which were used to train single-object segmentation models delineating only immature green apples. The results showed that YOLOv8 performed better than Mask R-CNN, achieving good precision and near-perfect recall across both datasets at a confidence threshold of 0.5. Specifically, for Dataset 1, YOLOv8 achieved a precision of 0.90 and a recall of 0.95 for all classes. In comparison, Mask R-CNN demonstrated a precision of 0.81 and a recall of 0.81 for the same dataset. With Dataset 2, YOLOv8 achieved a precision of 0.93 and a recall of 0.97. Mask R-CNN, in this single-class scenario, achieved a precision of 0.85 and a recall of 0.88. Additionally, the inference times for YOLOv8 were 10.9 ms for multi-class segmentation (Dataset 1) and 7.8 ms for single-class segmentation (Dataset 2), compared to 15.6 ms and 12.8 ms achieved by Mask R-CNN's, respectively.
Bayesian inversion of GPR waveforms for uncertainty-aware sub-surface material characterization
Dec 13, 2023Accurate estimation of sub-surface properties like moisture content and depth of layers is crucial for applications spanning sub-surface condition monitoring, precision agriculture, and effective wildfire risk assessment. Soil in nature is often covered by overlaying surface material, making its characterization using conventional methods challenging. In addition, the estimation of the properties of the overlaying layer is crucial for applications like wildfire assessment. This study thus proposes a Bayesian model-updating-based approach for ground penetrating radar (GPR) waveform inversion to predict sub-surface properties like the moisture contents and depths of the soil layer and overlaying material accumulated above the soil. The dielectric permittivity of material layers were predicted with the proposed method, along with other parameters, including depth and electrical conductivity of layers. The proposed Bayesian model updating approach yields probabilistic estimates of these parameters that can provide information about the confidence and uncertainty related to the estimates. The methodology was evaluated for a diverse range of experimental data collected through laboratory and field investigations. Laboratory investigations included variations in soil moisture values and depth of the top layer (or overlaying material), and the field investigation included measurement of field soil moisture for sixteen days. The results demonstrated predictions consistent with time-domain reflectometry (TDR) measurements and conventional gravimetric tests. The top layer depth could also be predicted with reasonable accuracy. The proposed method provides a promising approach for uncertainty-aware sub-surface parameter estimation that can enable decision-making for risk assessment across a wide range of applications.
PointJEM: Self-supervised Point Cloud Understanding for Reducing Feature Redundancy via Joint Entropy Maximization
Dec 06, 2023Most deep learning-based point cloud processing methods are supervised and require large scale of labeled data. However, manual labeling of point cloud data is laborious and time-consuming. Self-supervised representation learning can address the aforementioned issue by learning robust and generalized representations from unlabeled datasets. Nevertheless, the embedded features obtained by representation learning usually contain redundant information, and most current methods reduce feature redundancy by linear correlation constraints. In this paper, we propose PointJEM, a self-supervised representation learning method applied to the point cloud field. PointJEM comprises an embedding scheme and a loss function based on joint entropy. The embedding scheme divides the embedding vector into different parts, each part can learn a distinctive feature. To reduce redundant information in the features, PointJEM maximizes the joint entropy between the different parts, thereby rendering the learned feature variables pairwise independent. To validate the effectiveness of our method, we conducted experiments on multiple datasets. The results demonstrate that our method can significantly reduce feature redundancy beyond linear correlation. Furthermore, PointJEM achieves competitive performance in downstream tasks such as classification and segmentation.
Memory-Efficient Optical Flow via Radius-Distribution Orthogonal Cost Volume
Dec 06, 2023The full 4D cost volume in Recurrent All-Pairs Field Transforms (RAFT) or global matching by Transformer achieves impressive performance for optical flow estimation. However, their memory consumption increases quadratically with input resolution, rendering them impractical for high-resolution images. In this paper, we present MeFlow, a novel memory-efficient method for high-resolution optical flow estimation. The key of MeFlow is a recurrent local orthogonal cost volume representation, which decomposes the 2D search space dynamically into two 1D orthogonal spaces, enabling our method to scale effectively to very high-resolution inputs. To preserve essential information in the orthogonal space, we utilize self attention to propagate feature information from the 2D space to the orthogonal space. We further propose a radius-distribution multi-scale lookup strategy to model the correspondences of large displacements at a negligible cost. We verify the efficiency and effectiveness of our method on the challenging Sintel and KITTI benchmarks, and real-world 4K ($2160\!\times\!3840$) images. Our method achieves competitive performance on both Sintel and KITTI benchmarks, while maintaining the highest memory efficiency on high-resolution inputs.
Enhancing Facial Classification and Recognition using 3D Facial Models and Deep Learning
Dec 08, 2023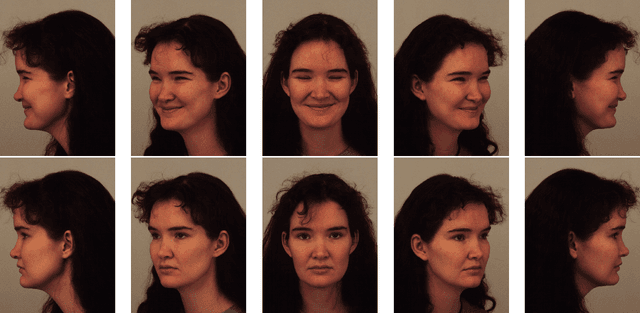



Accurate analysis and classification of facial attributes are essential in various applications, from human-computer interaction to security systems. In this work, a novel approach to enhance facial classification and recognition tasks through the integration of 3D facial models with deep learning methods was proposed. We extract the most useful information for various tasks using the 3D Facial Model, leading to improved classification accuracy. Combining 3D facial insights with ResNet architecture, our approach achieves notable results: 100% individual classification, 95.4% gender classification, and 83.5% expression classification accuracy. This method holds promise for advancing facial analysis and recognition research.
CaVE: A Cone-Aligned Approach for Fast Predict-then-optimize with Binary Linear Programs
Dec 12, 2023The end-to-end predict-then-optimize framework, also known as decision-focused learning, has gained popularity for its ability to integrate optimization into the training procedure of machine learning models that predict the unknown cost (objective function) coefficients of optimization problems from contextual instance information. Naturally, most of the problems of interest in this space can be cast as integer linear programs. In this work, we focus on binary linear programs (BLPs) and propose a new end-to-end training method for predict-then-optimize. Our method, Cone-aligned Vector Estimation (CaVE), aligns the predicted cost vectors with the cone corresponding to the true optimal solution of a training instance. When the predicted cost vector lies inside the cone, the optimal solution to the linear relaxation of the binary problem is optimal w.r.t. to the true cost vector. Not only does this alignment produce decision-aware learning models, but it also dramatically reduces training time as it circumvents the need to solve BLPs to compute a loss function with its gradients. Experiments across multiple datasets show that our method exhibits a favorable trade-off between training time and solution quality, particularly with large-scale optimization problems such as vehicle routing, a hard BLP that has yet to benefit from predict-then-optimize methods in the literature due to its difficulty.
Visible Light Positioning under Luminous Flux Degradation of LEDs
Dec 12, 2023The position estimation problem based on received power measurements is investigated for visible light systems in the presence of luminous flux degradation of light emitting diodes (LEDs). When the receiver is unaware of this degradation and performs position estimation accordingly, there exists a mismatch between the true model and the assumed model. For this scenario, the misspecified Cram\'er-Rao bound (MCRB) and the mismatched maximum likelihood (MML) estimator are derived to quantify the performance loss due to this model mismatch. Also, the Cram\'er-Rao lower bound (CRB) and the maximum likelihood (ML) estimator are derived when the receiver knows the degradation formula for the LEDs but does not know the decay rate parameter in that formula. In addition, in the presence of full knowledge about the degradation formula and the decay rate parameters, the CRB and the ML estimator are obtained to specify the best achievable performance. By evaluating the theoretical limits and the estimators in these three scenarios, we reveal the effects of the information about the LED degradation model and the decay rate parameters on position estimation performance. It is shown that the model mismatch can result in significant degradation in localization performance at high signal-to-noise ratios, which can be compensated by conducting joint position and decay rate parameter estimation.
FairSISA: Ensemble Post-Processing to Improve Fairness of Unlearning in LLMs
Dec 12, 2023Training large language models (LLMs) is a costly endeavour in terms of time and computational resources. The large amount of training data used during the unsupervised pre-training phase makes it difficult to verify all data and, unfortunately, undesirable data may be ingested during training. Re-training from scratch is impractical and has led to the creation of the 'unlearning' discipline where models are modified to "unlearn" undesirable information without retraining. However, any modification can alter the behaviour of LLMs, especially on key dimensions such as fairness. This is the first work that examines this interplay between unlearning and fairness for LLMs. In particular, we focus on a popular unlearning framework known as SISA [Bourtoule et al., 2021], which creates an ensemble of models trained on disjoint shards. We evaluate the performance-fairness trade-off for SISA, and empirically demsontrate that SISA can indeed reduce fairness in LLMs. To remedy this, we propose post-processing bias mitigation techniques for ensemble models produced by SISA. We adapt the post-processing fairness improvement technique from [Hardt et al., 2016] to design three methods that can handle model ensembles, and prove that one of the methods is an optimal fair predictor for ensemble of models. Through experimental results, we demonstrate the efficacy of our post-processing framework called 'FairSISA'.
QSMVM: QoS-aware and social-aware multimetric routing protocol for video-streaming services over MANETs
Dec 12, 2023A mobile ad hoc network (MANET) is a set of autonomous mobile devices connected by wireless links in a distributed manner and without a fixed infrastructure. Real-time multimedia services, such as video-streaming over MANETs, offers very promising applications, e.g. two members of a group of tourists who want to share a video transmitted through the MANET they form; a video-streaming service deployed over a MANET where users watch a film; among other examples. On the other hand, social web technologies, where people actively interact online with others through social networks, are leading to a socialization of networks. Information of interaction among users is being used to provide socially-enhanced software. To achieve this, we need to know the strength of the relationship between a given user and each user they interact with. This strength of the relationship can be measured through a concept called tie strength (TS), first introduced by Mark Granovetter in 1973. In this article, we modify our previous proposal named multipath multimedia dynamic source routing (MMDSR) protocol to include a social metric TS in the decisions taken by the forwarding algorithm. We find a trade-off between the quality of service (QoS) and the trust level between users who form the forwarding path in the MANET. Our goal is to increase the trust metric while the QoS is not affected significantly.