 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhancing Human-Computer Interaction in Chest X-ray Analysis using Vision and Language Model with Eye Gaze Patterns
Apr 03, 2024
Recent advancements in Computer Assisted Diagnosis have shown promising performance in medical imaging tasks, particularly in chest X-ray analysis. However, the interaction between these models and radiologists has been primarily limited to input images. This work proposes a novel approach to enhance human-computer interaction in chest X-ray analysis using Vision-Language Models (VLMs) enhanced with radiologists' attention by incorporating eye gaze data alongside textual prompts. Our approach leverages heatmaps generated from eye gaze data, overlaying them onto medical images to highlight areas of intense radiologist's focus during chest X-ray evaluation. We evaluate this methodology in tasks such as visual question answering, chest X-ray report automation, error detection, and differential diagnosis. Our results demonstrate the inclusion of eye gaze information significantly enhances the accuracy of chest X-ray analysis. Also, the impact of eye gaze on fine-tuning was confirmed as it outperformed other medical VLMs in all tasks except visual question answering. This work marks the potential of leveraging both the VLM's capabilities and the radiologist's domain knowledge to improve the capabilities of AI models in medical imaging, paving a novel way for Computer Assisted Diagnosis with a human-centred AI.
Resource-Aware Collaborative Monte Carlo Localization with Distribution Compression
Apr 02, 2024Global localization is essential in enabling robot autonomy, and collaborative localization is key for multi-robot systems. In this paper, we address the task of collaborative global localization under computational and communication constraints. We propose a method which reduces the amount of information exchanged and the computational cost. We also analyze, implement and open-source seminal approaches, which we believe to be a valuable contribution to the community. We exploit techniques for distribution compression in near-linear time, with error guarantees. We evaluate our approach and the implemented baselines on multiple challenging scenarios, simulated and real-world. Our approach can run online on an onboard computer. We release an open-source C++/ROS2 implementation of our approach, as well as the baselines
Team UTSA-NLP at SemEval 2024 Task 5: Prompt Ensembling for Argument Reasoning in Civil Procedures with GPT4
Apr 02, 2024In this paper, we present our system for the SemEval Task 5, The Legal Argument Reasoning Task in Civil Procedure Challenge. Legal argument reasoning is an essential skill that all law students must master. Moreover, it is important to develop natural language processing solutions that can reason about a question given terse domain-specific contextual information. Our system explores a prompt-based solution using GPT4 to reason over legal arguments. We also evaluate an ensemble of prompting strategies, including chain-of-thought reasoning and in-context learning. Overall, our system results in a Macro F1 of .8095 on the validation dataset and .7315 (5th out of 21 teams) on the final test set. Code for this project is available at https://github.com/danschumac1/CivilPromptReasoningGPT4.
Multi-criteria Token Fusion with One-step-ahead Attention for Efficient Vision Transformers
Apr 01, 2024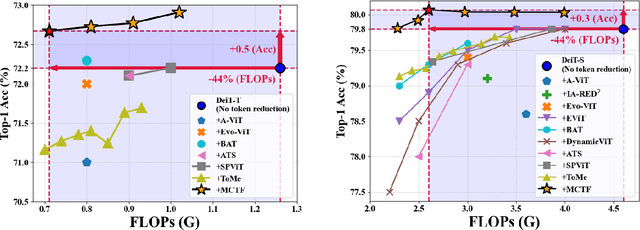
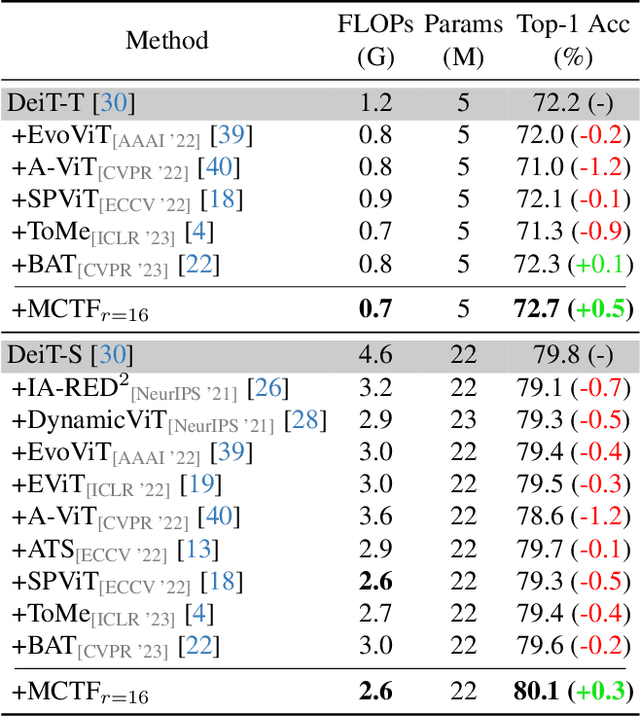
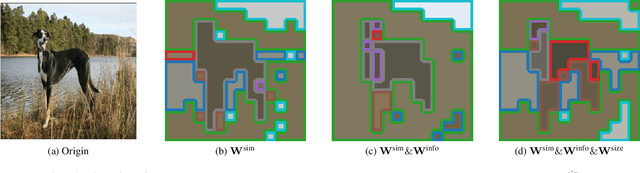
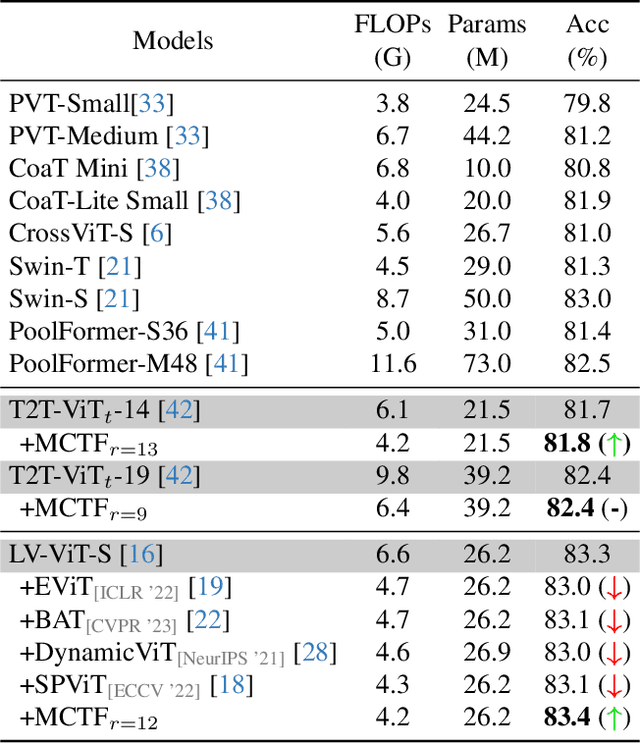
Vision Transformer (ViT) has emerged as a prominent backbone for computer vision. For more efficient ViTs, recent works lessen the quadratic cost of the self-attention layer by pruning or fusing the redundant tokens. However, these works faced the speed-accuracy trade-off caused by the loss of information. Here, we argue that token fusion needs to consider diverse relations between tokens to minimize information loss. In this paper, we propose a Multi-criteria Token Fusion (MCTF), that gradually fuses the tokens based on multi-criteria (e.g., similarity, informativeness, and size of fused tokens). Further, we utilize the one-step-ahead attention, which is the improved approach to capture the informativeness of the tokens. By training the model equipped with MCTF using a token reduction consistency, we achieve the best speed-accuracy trade-off in the image classification (ImageNet1K). Experimental results prove that MCTF consistently surpasses the previous reduction methods with and without training. Specifically, DeiT-T and DeiT-S with MCTF reduce FLOPs by about 44% while improving the performance (+0.5%, and +0.3%) over the base model, respectively. We also demonstrate the applicability of MCTF in various Vision Transformers (e.g., T2T-ViT, LV-ViT), achieving at least 31% speedup without performance degradation. Code is available at https://github.com/mlvlab/MCTF.
Medical Visual Prompting (MVP): A Unified Framework for Versatile and High-Quality Medical Image Segmentation
Apr 01, 2024Accurate segmentation of lesion regions is crucial for clinical diagnosis and treatment across various diseases. While deep convolutional networks have achieved satisfactory results in medical image segmentation, they face challenges such as loss of lesion shape information due to continuous convolution and downsampling, as well as the high cost of manually labeling lesions with varying shapes and sizes. To address these issues, we propose a novel medical visual prompting (MVP) framework that leverages pre-training and prompting concepts from natural language processing (NLP). The framework utilizes three key components: Super-Pixel Guided Prompting (SPGP) for superpixelating the input image, Image Embedding Guided Prompting (IEGP) for freezing patch embedding and merging with superpixels to provide visual prompts, and Adaptive Attention Mechanism Guided Prompting (AAGP) for pinpointing prompt content and efficiently adapting all layers. By integrating SPGP, IEGP, and AAGP, the MVP enables the segmentation network to better learn shape prompting information and facilitates mutual learning across different tasks. Extensive experiments conducted on five datasets demonstrate superior performance of this method in various challenging medical image tasks, while simplifying single-task medical segmentation models. This novel framework offers improved performance with fewer parameters and holds significant potential for accurate segmentation of lesion regions in various medical tasks, making it clinically valuable.
SyncMask: Synchronized Attentional Masking for Fashion-centric Vision-Language Pretraining
Apr 01, 2024Vision-language models (VLMs) have made significant strides in cross-modal understanding through large-scale paired datasets. However, in fashion domain, datasets often exhibit a disparity between the information conveyed in image and text. This issue stems from datasets containing multiple images of a single fashion item all paired with one text, leading to cases where some textual details are not visible in individual images. This mismatch, particularly when non-co-occurring elements are masked, undermines the training of conventional VLM objectives like Masked Language Modeling and Masked Image Modeling, thereby hindering the model's ability to accurately align fine-grained visual and textual features. Addressing this problem, we propose Synchronized attentional Masking (SyncMask), which generate masks that pinpoint the image patches and word tokens where the information co-occur in both image and text. This synchronization is accomplished by harnessing cross-attentional features obtained from a momentum model, ensuring a precise alignment between the two modalities. Additionally, we enhance grouped batch sampling with semi-hard negatives, effectively mitigating false negative issues in Image-Text Matching and Image-Text Contrastive learning objectives within fashion datasets. Our experiments demonstrate the effectiveness of the proposed approach, outperforming existing methods in three downstream tasks.
S2RC-GCN: A Spatial-Spectral Reliable Contrastive Graph Convolutional Network for Complex Land Cover Classification Using Hyperspectral Images
Apr 01, 2024Spatial correlations between different ground objects are an important feature of mining land cover research. Graph Convolutional Networks (GCNs) can effectively capture such spatial feature representations and have demonstrated promising results in performing hyperspectral imagery (HSI) classification tasks of complex land. However, the existing GCN-based HSI classification methods are prone to interference from redundant information when extracting complex features. To classify complex scenes more effectively, this study proposes a novel spatial-spectral reliable contrastive graph convolutional classification framework named S2RC-GCN. Specifically, we fused the spectral and spatial features extracted by the 1D- and 2D-encoder, and the 2D-encoder includes an attention model to automatically extract important information. We then leveraged the fused high-level features to construct graphs and fed the resulting graphs into the GCNs to determine more effective graph representations. Furthermore, a novel reliable contrastive graph convolution was proposed for reliable contrastive learning to learn and fuse robust features. Finally, to test the performance of the model on complex object classification, we used imagery taken by Gaofen-5 in the Jiang Xia area to construct complex land cover datasets. The test results show that compared with other models, our model achieved the best results and effectively improved the classification performance of complex remote sensing imagery.
Towards a Fully Interpretable and More Scalable RSA Model for Metaphor Understanding
Apr 03, 2024The Rational Speech Act (RSA) model provides a flexible framework to model pragmatic reasoning in computational terms. However, state-of-the-art RSA models are still fairly distant from modern machine learning techniques and present a number of limitations related to their interpretability and scalability. Here, we introduce a new RSA framework for metaphor understanding that addresses these limitations by providing an explicit formula - based on the mutually shared information between the speaker and the listener - for the estimation of the communicative goal and by learning the rationality parameter using gradient-based methods. The model was tested against 24 metaphors, not limited to the conventional $\textit{John-is-a-shark}$ type. Results suggest an overall strong positive correlation between the distributions generated by the model and the interpretations obtained from the human behavioral data, which increased when the intended meaning capitalized on properties that were inherent to the vehicle concept. Overall, findings suggest that metaphor processing is well captured by a typicality-based Bayesian model, even when more scalable and interpretable, opening up possible applications to other pragmatic phenomena and novel uses for increasing Large Language Models interpretability. Yet, results highlight that the more creative nuances of metaphorical meaning, not strictly encoded in the lexical concepts, are a challenging aspect for machines.
Personality-affected Emotion Generation in Dialog Systems
Apr 03, 2024Generating appropriate emotions for responses is essential for dialog systems to provide human-like interaction in various application scenarios. Most previous dialog systems tried to achieve this goal by learning empathetic manners from anonymous conversational data. However, emotional responses generated by those methods may be inconsistent, which will decrease user engagement and service quality. Psychological findings suggest that the emotional expressions of humans are rooted in personality traits. Therefore, we propose a new task, Personality-affected Emotion Generation, to generate emotion based on the personality given to the dialog system and further investigate a solution through the personality-affected mood transition. Specifically, we first construct a daily dialog dataset, Personality EmotionLines Dataset (PELD), with emotion and personality annotations. Subsequently, we analyze the challenges in this task, i.e., (1) heterogeneously integrating personality and emotional factors and (2) extracting multi-granularity emotional information in the dialog context. Finally, we propose to model the personality as the transition weight by simulating the mood transition process in the dialog system and solve the challenges above. We conduct extensive experiments on PELD for evaluation. Results suggest that by adopting our method, the emotion generation performance is improved by 13% in macro-F1 and 5% in weighted-F1 from the BERT-base model.
Exploring Unseen Environments with Robots using Large Language and Vision Models through a Procedurally Generated 3D Scene Representation
Mar 30, 2024Recent advancements in Generative Artificial Intelligence, particularly in the realm of Large Language Models (LLMs) and Large Vision Language Models (LVLMs), have enabled the prospect of leveraging cognitive planners within robotic systems. This work focuses on solving the object goal navigation problem by mimicking human cognition to attend, perceive and store task specific information and generate plans with the same. We introduce a comprehensive framework capable of exploring an unfamiliar environment in search of an object by leveraging the capabilities of Large Language Models(LLMs) and Large Vision Language Models (LVLMs) in understanding the underlying semantics of our world. A challenging task in using LLMs to generate high level sub-goals is to efficiently represent the environment around the robot. We propose to use a 3D scene modular representation, with semantically rich descriptions of the object, to provide the LLM with task relevant information. But providing the LLM with a mass of contextual information (rich 3D scene semantic representation), can lead to redundant and inefficient plans. We propose to use an LLM based pruner that leverages the capabilities of in-context learning to prune out irrelevant goal specific information.