 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OctreeOcc: Efficient and Multi-Granularity Occupancy Prediction Using Octree Queries
Dec 06, 2023
Occupancy prediction has increasingly garnered attention in recent years for its fine-grained understanding of 3D scenes. Traditional approaches typically rely on dense, regular grid representations, which often leads to excessive computational demands and a loss of spatial details for small objects. This paper introduces OctreeOcc, an innovative 3D occupancy prediction framework that leverages the octree representation to adaptively capture valuable information in 3D, offering variable granularity to accommodate object shapes and semantic regions of varying sizes and complexities. In particular, we incorporate image semantic information to improve the accuracy of initial octree structures and design an effective rectification mechanism to refine the octree structure iteratively. Our extensive evaluations show that OctreeOcc not only surpasses state-of-the-art methods in occupancy prediction, but also achieves a 15%-24% reduction in computational overhead compared to dense-grid-based methods.
PCoQA: Persian Conversational Question Answering Dataset
Dec 07, 2023Humans seek information regarding a specific topic through performing a conversation containing a series of questions and answers. In the pursuit of conversational question answering research, we introduce the PCoQA, the first \textbf{P}ersian \textbf{Co}nversational \textbf{Q}uestion \textbf{A}nswering dataset, a resource comprising information-seeking dialogs encompassing a total of 9,026 contextually-driven questions. Each dialog involves a questioner, a responder, and a document from the Wikipedia; The questioner asks several inter-connected questions from the text and the responder provides a span of the document as the answer for each question. PCoQA is designed to present novel challenges compared to previous question answering datasets including having more open-ended non-factual answers, longer answers, and fewer lexical overlaps. This paper not only presents the comprehensive PCoQA dataset but also reports the performance of various benchmark models. Our models include baseline models and pre-trained models, which are leveraged to boost the performance of the model. The dataset and benchmarks are available at our Github page.
How much informative is your XAI? A decision-making assessment task to objectively measure the goodness of explanations
Dec 07, 2023There is an increasing consensus about the effectiveness of user-centred approaches in the explainable artificial intelligence (XAI) field. Indeed, the number and complexity of personalised and user-centred approaches to XAI have rapidly grown in recent years. Often, these works have a two-fold objective: (1) proposing novel XAI techniques able to consider the users and (2) assessing the \textit{goodness} of such techniques with respect to others. From these new works, it emerged that user-centred approaches to XAI positively affect the interaction between users and systems. However, so far, the goodness of XAI systems has been measured through indirect measures, such as performance. In this paper, we propose an assessment task to objectively and quantitatively measure the goodness of XAI systems in terms of their \textit{information power}, which we intended as the amount of information the system provides to the users during the interaction. Moreover, we plan to use our task to objectively compare two XAI techniques in a human-robot decision-making task to understand deeper whether user-centred approaches are more informative than classical ones.
NestE: Modeling Nested Relational Structures for Knowledge Graph Reasoning
Dec 14, 2023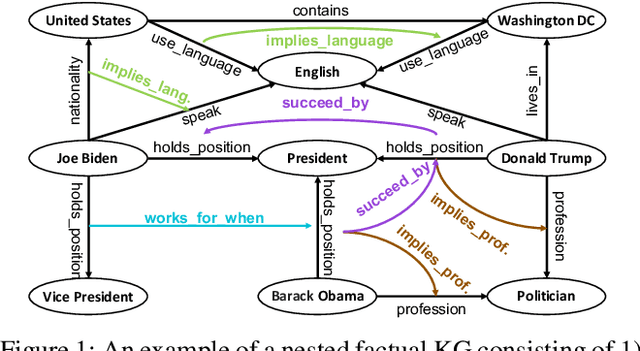

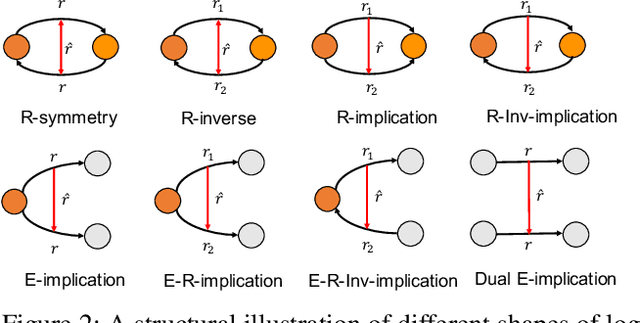
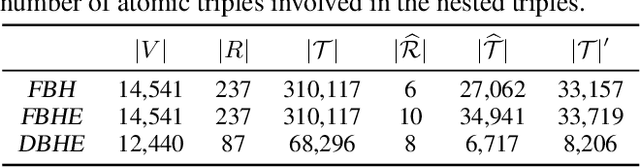
Reasoning with knowledge graphs (KGs) has primarily focused on triple-shaped facts. Recent advancements have been explored to enhance the semantics of these facts by incorporating more potent representations, such as hyper-relational facts. However, these approaches are limited to \emph{atomic facts}, which describe a single piece of information. This paper extends beyond \emph{atomic facts} and delves into \emph{nested facts}, represented by quoted triples where subjects and objects are triples themselves (e.g., ((\emph{BarackObama}, \emph{holds\_position}, \emph{President}), \emph{succeed\_by}, (\emph{DonaldTrump}, \emph{holds\_position}, \emph{President}))). These nested facts enable the expression of complex semantics like \emph{situations} over time and \emph{logical patterns} over entities and relations. In response, we introduce NestE, a novel KG embedding approach that captures the semantics of both atomic and nested factual knowledge. NestE represents each atomic fact as a $1\times3$ matrix, and each nested relation is modeled as a $3\times3$ matrix that rotates the $1\times3$ atomic fact matrix through matrix multiplication. Each element of the matrix is represented as a complex number in the generalized 4D hypercomplex space, including (spherical) quaternions, hyperbolic quaternions, and split-quaternions. Through thorough analysis, we demonstrate the embedding's efficacy in capturing diverse logical patterns over nested facts, surpassing the confines of first-order logic-like expressions. Our experimental results showcase NestE's significant performance gains over current baselines in triple prediction and conditional link prediction. The code and pre-trained models are open available at https://github.com/xiongbo010/NestE.
Contrastive Learning-Based Spectral Knowledge Distillation for Multi-Modality and Missing Modality Scenarios in Semantic Segmentation
Dec 04, 2023Improving the performance of semantic segmentation models using multispectral information is crucial, especially for environments with low-light and adverse conditions. Multi-modal fusion techniques pursue either the learning of cross-modality features to generate a fused image or engage in knowledge distillation but address multimodal and missing modality scenarios as distinct issues, which is not an optimal approach for multi-sensor models. To address this, a novel multi-modal fusion approach called CSK-Net is proposed, which uses a contrastive learning-based spectral knowledge distillation technique along with an automatic mixed feature exchange mechanism for semantic segmentation in optical (EO) and infrared (IR) images. The distillation scheme extracts detailed textures from the optical images and distills them into the optical branch of CSK-Net. The model encoder consists of shared convolution weights with separate batch norm (BN) layers for both modalities, to capture the multi-spectral information from different modalities of the same objects. A Novel Gated Spectral Unit (GSU) and mixed feature exchange strategy are proposed to increase the correlation of modality-shared information and decrease the modality-specific information during the distillation process. Comprehensive experiments show that CSK-Net surpasses state-of-the-art models in multi-modal tasks and for missing modalities when exclusively utilizing IR data for inference across three public benchmarking datasets. For missing modality scenarios, the performance increase is achieved without additional computational costs compared to the baseline segmentation models.
Local-Global History-aware Contrastive Learning for Temporal Knowledge Graph Reasoning
Dec 04, 2023Temporal knowledge graphs (TKGs) have been identified as a promising approach to represent the dynamics of facts along the timeline. The extrapolation of TKG is to predict unknowable facts happening in the future, holding significant practical value across diverse fields. Most extrapolation studies in TKGs focus on modeling global historical fact repeating and cyclic patterns, as well as local historical adjacent fact evolution patterns, showing promising performance in predicting future unknown facts. Yet, existing methods still face two major challenges: (1) They usually neglect the importance of historical information in KG snapshots related to the queries when encoding the local and global historical information; (2) They exhibit weak anti-noise capabilities, which hinders their performance when the inputs are contaminated with noise.To this end, we propose a novel \blue{Lo}cal-\blue{g}lobal history-aware \blue{C}ontrastive \blue{L}earning model (\blue{LogCL}) for TKG reasoning, which adopts contrastive learning to better guide the fusion of local and global historical information and enhance the ability to resist interference. Specifically, for the first challenge, LogCL proposes an entity-aware attention mechanism applied to the local and global historical facts encoder, which captures the key historical information related to queries. For the latter issue, LogCL designs four historical query contrast patterns, effectively improving the robustness of the model. The experimental results on four benchmark datasets demonstrate that LogCL delivers better and more robust performance than the state-of-the-art baselines.
A GAN Approach for Node Embedding in Heterogeneous Graphs Using Subgraph Sampling
Dec 11, 2023Our research addresses class imbalance issues in heterogeneous graphs using graph neural networks (GNNs). We propose a novel method combining the strengths of Generative Adversarial Networks (GANs) with GNNs, creating synthetic nodes and edges that effectively balance the dataset. This approach directly targets and rectifies imbalances at the data level. The proposed framework resolves issues such as neglecting graph structures during data generation and creating synthetic structures usable with GNN-based classifiers in downstream tasks. It processes node and edge information concurrently, improving edge balance through node augmentation and subgraph sampling. Additionally, our framework integrates a threshold strategy, aiding in determining optimal edge thresholds during training without time-consuming parameter adjustments. Experiments on the Amazon and Yelp Review datasets highlight the effectiveness of the framework we proposed, especially in minority node identification, where it consistently outperforms baseline models across key performance metrics, demonstrating its potential in the field.
Transformer Attractors for Robust and Efficient End-to-End Neural Diarization
Dec 11, 2023End-to-end neural diarization with encoder-decoder based attractors (EEND-EDA) is a method to perform diarization in a single neural network. EDA handles the diarization of a flexible number of speakers by using an LSTM-based encoder-decoder that generates a set of speaker-wise attractors in an autoregressive manner. In this paper, we propose to replace EDA with a transformer-based attractor calculation (TA) module. TA is composed of a Combiner block and a Transformer decoder. The main function of the combiner block is to generate conversational dependent (CD) embeddings by incorporating learned conversational information into a global set of embeddings. These CD embeddings will then serve as the input for the transformer decoder. Results on public datasets show that EEND-TA achieves 2.68% absolute DER improvement over EEND-EDA. EEND-TA inference is 1.28 times faster than that of EEND-EDA.
EEND-DEMUX: End-to-End Neural Speaker Diarization via Demultiplexed Speaker Embeddings
Dec 11, 2023In recent years, there have been studies to further improve the end-to-end neural speaker diarization (EEND) systems. This letter proposes the EEND-DEMUX model, a novel framework utilizing demultiplexed speaker embeddings. In this work, we focus on disentangling speaker-relevant information in the latent space and then transform each separated latent variable into its corresponding speech activity. EEND-DEMUX can directly obtain separated speaker embeddings through the demultiplexing operation in the inference phase without an external speaker diarization system, an embedding extractor, or a heuristic decoding technique. Furthermore, we employ a multi-head cross-attention mechanism to capture the correlation between mixture and separated speaker embeddings effectively. We formulate three loss functions based on matching, orthogonality, and sparsity constraints to learn robust demultiplexed speaker embeddings. The experimental results on the LibriMix dataset show consistently improved performance in both a fixed and flexible number of speakers scenarios.
Training on Synthetic Data Beats Real Data in Multimodal Relation Extraction
Dec 05, 2023The task of multimodal relation extraction has attracted significant research attention, but progress is constrained by the scarcity of available training data. One natural thought is to extend existing datasets with cross-modal generative models. In this paper, we consider a novel problem setting, where only unimodal data, either text or image, are available during training. We aim to train a multimodal classifier from synthetic data that perform well on real multimodal test data. However, training with synthetic data suffers from two obstacles: lack of data diversity and label information loss. To alleviate the issues, we propose Mutual Information-aware Multimodal Iterated Relational dAta GEneration (MI2RAGE), which applies Chained Cross-modal Generation (CCG) to promote diversity in the generated data and exploits a teacher network to select valuable training samples with high mutual information with the ground-truth labels. Comparing our method to direct training on synthetic data, we observed a significant improvement of 24.06% F1 with synthetic text and 26.42% F1 with synthetic images. Notably, our best model trained on completely synthetic images outperforms prior state-of-the-art models trained on real multimodal data by a margin of 3.76% in F1. Our codebase will be made available upon acceptance.