 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SCCA: Shifted Cross Chunk Attention for long contextual semantic expansion
Dec 12, 2023
Sparse attention as a efficient method can significantly decrease the computation cost, but current sparse attention tend to rely on window self attention which block the global information flow. For this problem, we present Shifted Cross Chunk Attention (SCCA), using different KV shifting strategy to extend respective field in each attention layer. Except, we combine Dilated Attention(DA) and Dilated Neighborhood Attention(DNA) to present Shifted Dilated Attention(SDA). Both SCCA and SDA can accumulate attention results in multi head attention to obtain approximate respective field in full attention. In this paper, we conduct language modeling experiments using different pattern of SCCA and combination of SCCA and SDA. The proposed shifted cross chunk attention (SCCA) can effectively extend large language models (LLMs) to longer context combined with Positional interpolation(PI) and LoRA than current sparse attention. Notably, SCCA adopts LLaMA2 7B from 4k context to 8k in single V100. This attention pattern can provide a Plug-and-play fine-tuning method to extend model context while retaining their original architectures, and is compatible with most existing techniques.
Multi-Granularity Framework for Unsupervised Representation Learning of Time Series
Dec 12, 2023Representation learning plays a critical role in the analysis of time series data and has high practical value across a wide range of applications. including trend analysis, time series data retrieval and forecasting. In practice, data confusion is a significant issue as it can considerably impact the effectiveness and accuracy of data analysis, machine learning models and decision-making processes. In general, previous studies did not consider the variability at various levels of granularity, thus resulting in inadequate information utilization, which further exacerbated the issue of data confusion. This paper proposes an unsupervised framework to realize multi-granularity representation learning for time series. Specifically, we employed a cross-granularity transformer to develop an association between fine- and coarse-grained representations. In addition, we introduced a retrieval task as an unsupervised training task to learn the multi-granularity representation of time series. Moreover, a novel loss function was designed to obtain the comprehensive multi-granularity representation of the time series via unsupervised learning. The experimental results revealed that the proposed framework demonstrates significant advantages over alternative representation learning models.
NestE: Modeling Nested Relational Structures for Knowledge Graph Reasoning
Dec 14, 2023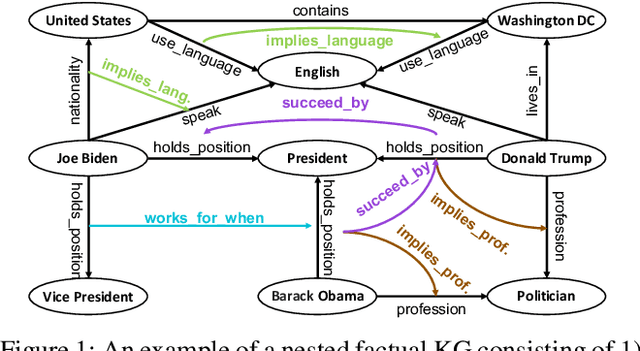

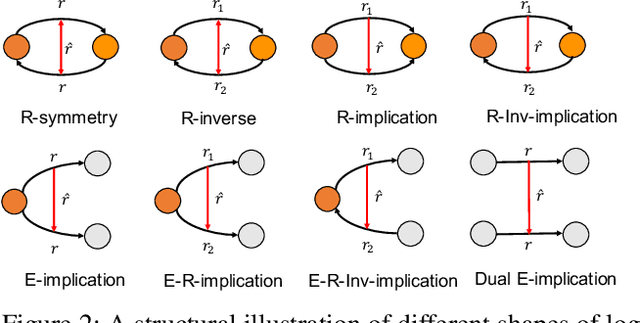
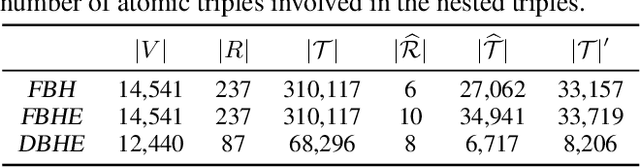
Reasoning with knowledge graphs (KGs) has primarily focused on triple-shaped facts. Recent advancements have been explored to enhance the semantics of these facts by incorporating more potent representations, such as hyper-relational facts. However, these approaches are limited to \emph{atomic facts}, which describe a single piece of information. This paper extends beyond \emph{atomic facts} and delves into \emph{nested facts}, represented by quoted triples where subjects and objects are triples themselves (e.g., ((\emph{BarackObama}, \emph{holds\_position}, \emph{President}), \emph{succeed\_by}, (\emph{DonaldTrump}, \emph{holds\_position}, \emph{President}))). These nested facts enable the expression of complex semantics like \emph{situations} over time and \emph{logical patterns} over entities and relations. In response, we introduce NestE, a novel KG embedding approach that captures the semantics of both atomic and nested factual knowledge. NestE represents each atomic fact as a $1\times3$ matrix, and each nested relation is modeled as a $3\times3$ matrix that rotates the $1\times3$ atomic fact matrix through matrix multiplication. Each element of the matrix is represented as a complex number in the generalized 4D hypercomplex space, including (spherical) quaternions, hyperbolic quaternions, and split-quaternions. Through thorough analysis, we demonstrate the embedding's efficacy in capturing diverse logical patterns over nested facts, surpassing the confines of first-order logic-like expressions. Our experimental results showcase NestE's significant performance gains over current baselines in triple prediction and conditional link prediction. The code and pre-trained models are open available at https://github.com/xiongbo010/NestE.
An Autonomous Driving model with BEV-V2X Perception, Trajectory Prediction and Driving Planning in Complex Traffic Intersections
Dec 08, 2023The comprehensiveness of vehicle-to-everything (V2X) recognition enriches and holistically shapes the global Birds-Eye-View (BEV) perception, incorporating rich semantics and integrating driving scene information, thereby serving features of trajectory prediction, decision-making and driving planning. Utilizing V2X message sets to form BEV format proves to be an effective perception method for connected and automated vehicles (CAVs). Specifically, MAP, SPAT and RSI data contributes to the achievement of road connectivity, synchronized traffic signal navigation and obstacle warning. Moreover, using time-sequential BSMs information from multiple vehicles allows for the perception of current state and the prediction of future trajectories. Therefore, this paper develops a comprehensive autonomous driving model that relies on BEV-V2X perception, Interacting Multiple model Unscented Kalman Filter (IMM-UKF)-based trajectory prediction, and deep reinforcement learning (DRL)-based decision making and planing. We establish a DRL environment with reward-shaping methods to formulate a unified set of optimal driving behaviors that encompass obstacle avoidance, lane changes, overtaking, turning maneuver, and synchronized traffic signal navigation. Consequently, a complex traffic intersection scenario was simulated, and the well-trained model was applied for driving control. The observed driving behavior closely resembled that of an experienced driver, exhibiting anticipatory actions and revealing notable operational highlights of driving policy.
Cross-BERT for Point Cloud Pretraining
Dec 08, 2023Introducing BERT into cross-modal settings raises difficulties in its optimization for handling multiple modalities. Both the BERT architecture and training objective need to be adapted to incorporate and model information from different modalities. In this paper, we address these challenges by exploring the implicit semantic and geometric correlations between 2D and 3D data of the same objects/scenes. We propose a new cross-modal BERT-style self-supervised learning paradigm, called Cross-BERT. To facilitate pretraining for irregular and sparse point clouds, we design two self-supervised tasks to boost cross-modal interaction. The first task, referred to as Point-Image Alignment, aims to align features between unimodal and cross-modal representations to capture the correspondences between the 2D and 3D modalities. The second task, termed Masked Cross-modal Modeling, further improves mask modeling of BERT by incorporating high-dimensional semantic information obtained by cross-modal interaction. By performing cross-modal interaction, Cross-BERT can smoothly reconstruct the masked tokens during pretraining, leading to notable performance enhancements for downstream tasks. Through empirical evaluation, we demonstrate that Cross-BERT outperforms existing state-of-the-art methods in 3D downstream applications. Our work highlights the effectiveness of leveraging cross-modal 2D knowledge to strengthen 3D point cloud representation and the transferable capability of BERT across modalities.
FreestyleRet: Retrieving Images from Style-Diversified Queries
Dec 08, 2023Image Retrieval aims to retrieve corresponding images based on a given query. In application scenarios, users intend to express their retrieval intent through various query styles. However, current retrieval tasks predominantly focus on text-query retrieval exploration, leading to limited retrieval query options and potential ambiguity or bias in user intention. In this paper, we propose the Style-Diversified Query-Based Image Retrieval task, which enables retrieval based on various query styles. To facilitate the novel setting, we propose the first Diverse-Style Retrieval dataset, encompassing diverse query styles including text, sketch, low-resolution, and art. We also propose a light-weighted style-diversified retrieval framework. For various query style inputs, we apply the Gram Matrix to extract the query's textural features and cluster them into a style space with style-specific bases. Then we employ the style-init prompt tuning module to enable the visual encoder to comprehend the texture and style information of the query. Experiments demonstrate that our model, employing the style-init prompt tuning strategy, outperforms existing retrieval models on the style-diversified retrieval task. Moreover, style-diversified queries~(sketch+text, art+text, etc) can be simultaneously retrieved in our model. The auxiliary information from other queries enhances the retrieval performance within the respective query.
Hypergraph Node Representation Learning with One-Stage Message Passing
Dec 01, 2023Hypergraphs as an expressive and general structure have attracted considerable attention from various research domains. Most existing hypergraph node representation learning techniques are based on graph neural networks, and thus adopt the two-stage message passing paradigm (i.e. node -> hyperedge -> node). This paradigm only focuses on local information propagation and does not effectively take into account global information, resulting in less optimal representations. Our theoretical analysis of representative two-stage message passing methods shows that, mathematically, they model different ways of local message passing through hyperedges, and can be unified into one-stage message passing (i.e. node -> node). However, they still only model local information. Motivated by this theoretical analysis, we propose a novel one-stage message passing paradigm to model both global and local information propagation for hypergraphs. We integrate this paradigm into HGraphormer, a Transformer-based framework for hypergraph node representation learning. HGraphormer injects the hypergraph structure information (local information) into Transformers (global information) by combining the attention matrix and hypergraph Laplacian. Extensive experiments demonstrate that HGraphormer outperforms recent hypergraph learning methods on five representative benchmark datasets on the semi-supervised hypernode classification task, setting new state-of-the-art performance, with accuracy improvements between 2.52% and 6.70%. Our code and datasets are available.
Transformer Attractors for Robust and Efficient End-to-End Neural Diarization
Dec 11, 2023End-to-end neural diarization with encoder-decoder based attractors (EEND-EDA) is a method to perform diarization in a single neural network. EDA handles the diarization of a flexible number of speakers by using an LSTM-based encoder-decoder that generates a set of speaker-wise attractors in an autoregressive manner. In this paper, we propose to replace EDA with a transformer-based attractor calculation (TA) module. TA is composed of a Combiner block and a Transformer decoder. The main function of the combiner block is to generate conversational dependent (CD) embeddings by incorporating learned conversational information into a global set of embeddings. These CD embeddings will then serve as the input for the transformer decoder. Results on public datasets show that EEND-TA achieves 2.68% absolute DER improvement over EEND-EDA. EEND-TA inference is 1.28 times faster than that of EEND-EDA.
A GAN Approach for Node Embedding in Heterogeneous Graphs Using Subgraph Sampling
Dec 11, 2023Our research addresses class imbalance issues in heterogeneous graphs using graph neural networks (GNNs). We propose a novel method combining the strengths of Generative Adversarial Networks (GANs) with GNNs, creating synthetic nodes and edges that effectively balance the dataset. This approach directly targets and rectifies imbalances at the data level. The proposed framework resolves issues such as neglecting graph structures during data generation and creating synthetic structures usable with GNN-based classifiers in downstream tasks. It processes node and edge information concurrently, improving edge balance through node augmentation and subgraph sampling. Additionally, our framework integrates a threshold strategy, aiding in determining optimal edge thresholds during training without time-consuming parameter adjustments. Experiments on the Amazon and Yelp Review datasets highlight the effectiveness of the framework we proposed, especially in minority node identification, where it consistently outperforms baseline models across key performance metrics, demonstrating its potential in the field.
EEND-DEMUX: End-to-End Neural Speaker Diarization via Demultiplexed Speaker Embeddings
Dec 11, 2023In recent years, there have been studies to further improve the end-to-end neural speaker diarization (EEND) systems. This letter proposes the EEND-DEMUX model, a novel framework utilizing demultiplexed speaker embeddings. In this work, we focus on disentangling speaker-relevant information in the latent space and then transform each separated latent variable into its corresponding speech activity. EEND-DEMUX can directly obtain separated speaker embeddings through the demultiplexing operation in the inference phase without an external speaker diarization system, an embedding extractor, or a heuristic decoding technique. Furthermore, we employ a multi-head cross-attention mechanism to capture the correlation between mixture and separated speaker embeddings effectively. We formulate three loss functions based on matching, orthogonality, and sparsity constraints to learn robust demultiplexed speaker embeddings. The experimental results on the LibriMix dataset show consistently improved performance in both a fixed and flexible number of speakers scenarios.