 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Beyond the Label Itself: Latent Labels Enhance Semi-supervised Point Cloud Panoptic Segmentation
Dec 13, 2023
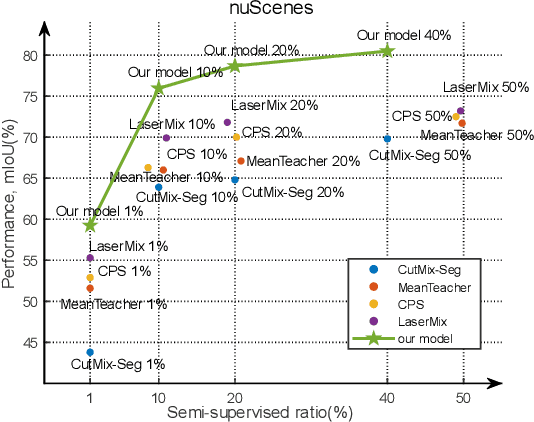
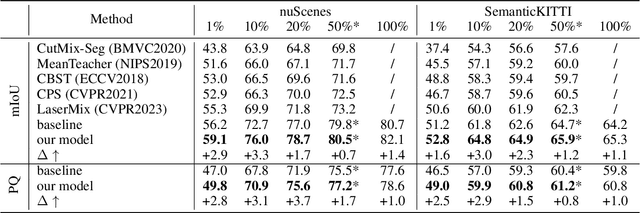

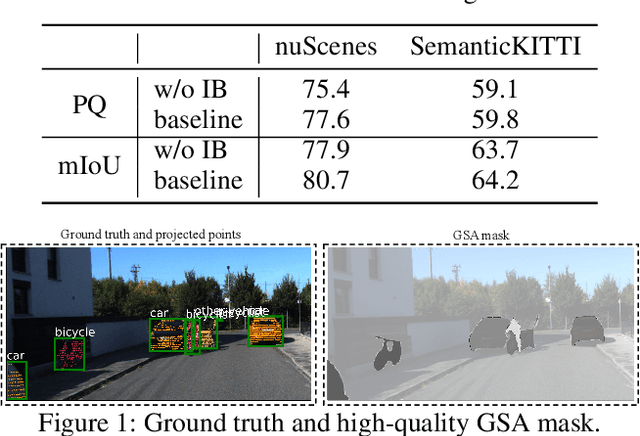
As the exorbitant expense of labeling autopilot datasets and the growing trend of utilizing unlabeled data, semi-supervised segmentation on point clouds becomes increasingly imperative. Intuitively, finding out more ``unspoken words'' (i.e., latent instance information) beyond the label itself should be helpful to improve performance. In this paper, we discover two types of latent labels behind the displayed label embedded in LiDAR and image data. First, in the LiDAR Branch, we propose a novel augmentation, Cylinder-Mix, which is able to augment more yet reliable samples for training. Second, in the Image Branch, we propose the Instance Position-scale Learning (IPSL) Module to learn and fuse the information of instance position and scale, which is from a 2D pre-trained detector and a type of latent label obtained from 3D to 2D projection. Finally, the two latent labels are embedded into the multi-modal panoptic segmentation network. The ablation of the IPSL module demonstrates its robust adaptability, and the experiments evaluated on SemanticKITTI and nuScenes demonstrate that our model outperforms the state-of-the-art method, LaserMix.
Helping Language Models Learn More: Multi-dimensional Task Prompt for Few-shot Tuning
Dec 13, 2023Large language models (LLMs) can be used as accessible and intelligent chatbots by constructing natural language queries and directly inputting the prompt into the large language model. However, different prompt' constructions often lead to uncertainty in the answers and thus make it hard to utilize the specific knowledge of LLMs (like ChatGPT). To alleviate this, we use an interpretable structure to explain the prompt learning principle in LLMs, which certificates that the effectiveness of language models is determined by position changes of the task's related tokens. Therefore, we propose MTPrompt, a multi-dimensional task prompt learning method consisting based on task-related object, summary, and task description information. By automatically building and searching for appropriate prompts, our proposed MTPrompt achieves the best results on few-shot samples setting and five different datasets. In addition, we demonstrate the effectiveness and stability of our method in different experimental settings and ablation experiments. In interaction with large language models, embedding more task-related information into prompts will make it easier to stimulate knowledge embedded in large language models.
Mono3DVG: 3D Visual Grounding in Monocular Images
Dec 13, 2023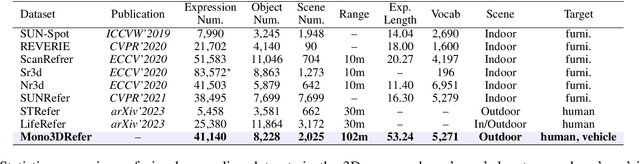


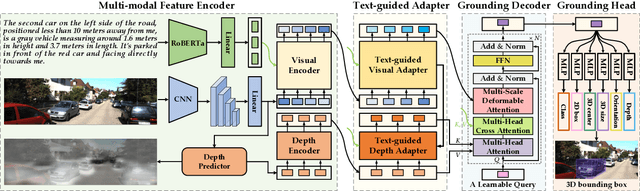
We introduce a novel task of 3D visual grounding in monocular RGB images using language descriptions with both appearance and geometry information. Specifically, we build a large-scale dataset, Mono3DRefer, which contains 3D object targets with their corresponding geometric text descriptions, generated by ChatGPT and refined manually. To foster this task, we propose Mono3DVG-TR, an end-to-end transformer-based network, which takes advantage of both the appearance and geometry information in text embeddings for multi-modal learning and 3D object localization. Depth predictor is designed to explicitly learn geometry features. The dual text-guided adapter is proposed to refine multiscale visual and geometry features of the referred object. Based on depth-text-visual stacking attention, the decoder fuses object-level geometric cues and visual appearance into a learnable query. Comprehensive benchmarks and some insightful analyses are provided for Mono3DVG. Extensive comparisons and ablation studies show that our method significantly outperforms all baselines. The dataset and code will be publicly available at: https://github.com/ZhanYang-nwpu/Mono3DVG.
Information Content Exploration
Oct 10, 2023Sparse reward environments are known to be challenging for reinforcement learning agents. In such environments, efficient and scalable exploration is crucial. Exploration is a means by which an agent gains information about the environment. We expand on this topic and propose a new intrinsic reward that systemically quantifies exploratory behavior and promotes state coverage by maximizing the information content of a trajectory taken by an agent. We compare our method to alternative exploration based intrinsic reward techniques, namely Curiosity Driven Learning and Random Network Distillation. We show that our information theoretic reward induces efficient exploration and outperforms in various games, including Montezuma Revenge, a known difficult task for reinforcement learning. Finally, we propose an extension that maximizes information content in a discretely compressed latent space which boosts sample efficiency and generalizes to continuous state spaces.
Approximate information maximization for bandit games
Oct 19, 2023Entropy maximization and free energy minimization are general physical principles for modeling the dynamics of various physical systems. Notable examples include modeling decision-making within the brain using the free-energy principle, optimizing the accuracy-complexity trade-off when accessing hidden variables with the information bottleneck principle (Tishby et al., 2000), and navigation in random environments using information maximization (Vergassola et al., 2007). Built on this principle, we propose a new class of bandit algorithms that maximize an approximation to the information of a key variable within the system. To this end, we develop an approximated analytical physics-based representation of an entropy to forecast the information gain of each action and greedily choose the one with the largest information gain. This method yields strong performances in classical bandit settings. Motivated by its empirical success, we prove its asymptotic optimality for the two-armed bandit problem with Gaussian rewards. Owing to its ability to encompass the system's properties in a global physical functional, this approach can be efficiently adapted to more complex bandit settings, calling for further investigation of information maximization approaches for multi-armed bandit problems.
Metalearning with Very Few Samples Per Task
Dec 21, 2023Metalearning and multitask learning are two frameworks for solving a group of related learning tasks more efficiently than we could hope to solve each of the individual tasks on their own. In multitask learning, we are given a fixed set of related learning tasks and need to output one accurate model per task, whereas in metalearning we are given tasks that are drawn i.i.d. from a metadistribution and need to output some common information that can be easily specialized to new, previously unseen tasks from the metadistribution. In this work, we consider a binary classification setting where tasks are related by a shared representation, that is, every task $P$ of interest can be solved by a classifier of the form $f_{P} \circ h$ where $h \in H$ is a map from features to some representation space that is shared across tasks, and $f_{P} \in F$ is a task-specific classifier from the representation space to labels. The main question we ask in this work is how much data do we need to metalearn a good representation? Here, the amount of data is measured in terms of both the number of tasks $t$ that we need to see and the number of samples $n$ per task. We focus on the regime where the number of samples per task is extremely small. Our main result shows that, in a distribution-free setting where the feature vectors are in $\mathbb{R}^d$, the representation is a linear map from $\mathbb{R}^d \to \mathbb{R}^k$, and the task-specific classifiers are halfspaces in $\mathbb{R}^k$, we can metalearn a representation with error $\varepsilon$ using just $n = k+2$ samples per task, and $d \cdot (1/\varepsilon)^{O(k)}$ tasks. Learning with so few samples per task is remarkable because metalearning would be impossible with $k+1$ samples per task, and because we cannot even hope to learn an accurate task-specific classifier with just $k+2$ samples per task.
Improving the Expressive Power of Deep Neural Networks through Integral Activation Transform
Dec 19, 2023The impressive expressive power of deep neural networks (DNNs) underlies their widespread applicability. However, while the theoretical capacity of deep architectures is high, the practical expressive power achieved through successful training often falls short. Building on the insights gained from Neural ODEs, which explore the depth of DNNs as a continuous variable, in this work, we generalize the traditional fully connected DNN through the concept of continuous width. In the Generalized Deep Neural Network (GDNN), the traditional notion of neurons in each layer is replaced by a continuous state function. Using the finite rank parameterization of the weight integral kernel, we establish that GDNN can be obtained by employing the Integral Activation Transform (IAT) as activation layers within the traditional DNN framework. The IAT maps the input vector to a function space using some basis functions, followed by nonlinear activation in the function space, and then extracts information through the integration with another collection of basis functions. A specific variant, IAT-ReLU, featuring the ReLU nonlinearity, serves as a smooth generalization of the scalar ReLU activation. Notably, IAT-ReLU exhibits a continuous activation pattern when continuous basis functions are employed, making it smooth and enhancing the trainability of the DNN. Our numerical experiments demonstrate that IAT-ReLU outperforms regular ReLU in terms of trainability and better smoothness.
Compact 3D Scene Representation via Self-Organizing Gaussian Grids
Dec 19, 20233D Gaussian Splatting has recently emerged as a highly promising technique for modeling of static 3D scenes. In contrast to Neural Radiance Fields, it utilizes efficient rasterization allowing for very fast rendering at high-quality. However, the storage size is significantly higher, which hinders practical deployment, e.g.~on resource constrained devices. In this paper, we introduce a compact scene representation organizing the parameters of 3D Gaussian Splatting (3DGS) into a 2D grid with local homogeneity, ensuring a drastic reduction in storage requirements without compromising visual quality during rendering. Central to our idea is the explicit exploitation of perceptual redundancies present in natural scenes. In essence, the inherent nature of a scene allows for numerous permutations of Gaussian parameters to equivalently represent it. To this end, we propose a novel highly parallel algorithm that regularly arranges the high-dimensional Gaussian parameters into a 2D grid while preserving their neighborhood structure. During training, we further enforce local smoothness between the sorted parameters in the grid. The uncompressed Gaussians use the same structure as 3DGS, ensuring a seamless integration with established renderers. Our method achieves a reduction factor of 8x to 26x in size for complex scenes with no increase in training time, marking a substantial leap forward in the domain of 3D scene distribution and consumption. Additional information can be found on our project page: https://fraunhoferhhi.github.io/Self-Organizing-Gaussians/
Localization and Discrete Beamforming with a Large Reconfigurable Intelligent Surface
Dec 19, 2023In millimeter-wave (mmWave) cellular systems, reconfigurable intelligent surfaces (RISs) are foreseeably deployed with a large number of reflecting elements to achieve high beamforming gains. The large-sized RIS will make radio links fall in the near-field localization regime with spatial non-stationarity issues. Moreover, the discrete phase restriction on the RIS reflection coefficient incurs exponential complexity for discrete beamforming. It remains an open problem to find the optimal RIS reflection coefficient design in polynomial time. To address these issues, we propose a scalable partitioned-far-field protocol that considers both the near-filed non-stationarity and discrete beamforming. The protocol approximates near-field signal propagation using a partitioned-far-field representation to inherit the sparsity from the sophisticated far-field and facilitate the near-field localization scheme. To improve the theoretical localization performance, we propose a fast passive beamforming (FPB) algorithm that optimally solves the discrete RIS beamforming problem, reducing the search complexity from exponential order to linear order. Furthermore, by exploiting the partitioned structure of RIS, we introduce a two-stage coarse-to-fine localization algorithm that leverages both the time delay and angle information. Numerical results demonstrate that centimeter-level localization precision is achieved under medium and high signal-to-noise ratios (SNR), revealing that RISs can provide support for low-cost and high-precision localization in future cellular systems.
Adversarial AutoMixup
Dec 19, 2023Data mixing augmentation has been widely applied to improve the generalization ability of deep neural networks. Recently, offline data mixing augmentation, e.g. handcrafted and saliency information-based mixup, has been gradually replaced by automatic mixing approaches. Through minimizing two sub-tasks, namely, mixed sample generation and mixup classification in an end-to-end way, AutoMix significantly improves accuracy on image classification tasks. However, as the optimization objective is consistent for the two sub-tasks, this approach is prone to generating consistent instead of diverse mixed samples, which results in overfitting for target task training. In this paper, we propose AdAutomixup, an adversarial automatic mixup augmentation approach that generates challenging samples to train a robust classifier for image classification, by alternatively optimizing the classifier and the mixup sample generator. AdAutomixup comprises two modules, a mixed example generator, and a target classifier. The mixed sample generator aims to produce hard mixed examples to challenge the target classifier while the target classifier`s aim is to learn robust features from hard mixed examples to improve generalization. To prevent the collapse of the inherent meanings of images, we further introduce an exponential moving average (EMA) teacher and cosine similarity to train AdAutomixup in an end-to-end way. Extensive experiments on seven image benchmarks consistently prove that our approach outperforms the state of the art in various classification scenarios.