 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Does provable absence of barren plateaus imply classical simulability? Or, why we need to rethink variational quantum computing
Dec 14, 2023
A large amount of effort has recently been put into understanding the barren plateau phenomenon. In this perspective article, we face the increasingly loud elephant in the room and ask a question that has been hinted at by many but not explicitly addressed: Can the structure that allows one to avoid barren plateaus also be leveraged to efficiently simulate the loss classically? We present strong evidence that commonly used models with provable absence of barren plateaus are also classically simulable, provided that one can collect some classical data from quantum devices during an initial data acquisition phase. This follows from the observation that barren plateaus result from a curse of dimensionality, and that current approaches for solving them end up encoding the problem into some small, classically simulable, subspaces. This sheds serious doubt on the non-classicality of the information processing capabilities of parametrized quantum circuits for barren plateau-free landscapes and on the possibility of superpolynomial advantages from running them on quantum hardware. We end by discussing caveats in our arguments, the role of smart initializations, and by highlighting new opportunities that our perspective raises.
Generative Model-based Feature Knowledge Distillation for Action Recognition
Dec 14, 2023Knowledge distillation (KD), a technique widely employed in computer vision, has emerged as a de facto standard for improving the performance of small neural networks. However, prevailing KD-based approaches in video tasks primarily focus on designing loss functions and fusing cross-modal information. This overlooks the spatial-temporal feature semantics, resulting in limited advancements in model compression. Addressing this gap, our paper introduces an innovative knowledge distillation framework, with the generative model for training a lightweight student model. In particular, the framework is organized into two steps: the initial phase is Feature Representation, wherein a generative model-based attention module is trained to represent feature semantics; Subsequently, the Generative-based Feature Distillation phase encompasses both Generative Distillation and Attention Distillation, with the objective of transferring attention-based feature semantics with the generative model. The efficacy of our approach is demonstrated through comprehensive experiments on diverse popular datasets, proving considerable enhancements in video action recognition task. Moreover, the effectiveness of our proposed framework is validated in the context of more intricate video action detection task. Our code is available at https://github.com/aaai-24/Generative-based-KD.
Large Language Models for Autonomous Driving: Real-World Experiments
Dec 14, 2023Autonomous driving systems are increasingly popular in today's technological landscape, where vehicles with partial automation have already been widely available on the market, and the full automation era with ``driverless'' capabilities is near the horizon. However, accurately understanding humans' commands, particularly for autonomous vehicles that have only passengers instead of drivers, and achieving a high level of personalization remain challenging tasks in the development of autonomous driving systems. In this paper, we introduce a Large Language Model (LLM)-based framework Talk-to-Drive (Talk2Drive) to process verbal commands from humans and make autonomous driving decisions with contextual information, satisfying their personalized preferences for safety, efficiency, and comfort. First, a speech recognition module is developed for Talk2Drive to interpret verbal inputs from humans to textual instructions, which are then sent to LLMs for reasoning. Then, appropriate commands for the Electrical Control Unit (ECU) are generated, achieving a 100\% success rate in executing codes. Real-world experiments show that our framework can substantially reduce the takeover rate for a diverse range of drivers by up to 90.1\%. To the best of our knowledge, Talk2Drive marks the first instance of employing an LLM-based system in a real-world autonomous driving environment.
HeadRecon: High-Fidelity 3D Head Reconstruction from Monocular Video
Dec 14, 2023Recently, the reconstruction of high-fidelity 3D head models from static portrait image has made great progress. However, most methods require multi-view or multi-illumination information, which therefore put forward high requirements for data acquisition. In this paper, we study the reconstruction of high-fidelity 3D head models from arbitrary monocular videos. Non-rigid structure from motion (NRSFM) methods have been widely used to solve such problems according to the two-dimensional correspondence between different frames. However, the inaccurate correspondence caused by high-complex hair structures and various facial expression changes would heavily influence the reconstruction accuracy. To tackle these problems, we propose a prior-guided dynamic implicit neural network. Specifically, we design a two-part dynamic deformation field to transform the current frame space to the canonical one. We further model the head geometry in the canonical space with a learnable signed distance field (SDF) and optimize it using the volumetric rendering with the guidance of two-main head priors to improve the reconstruction accuracy and robustness. Extensive ablation studies and comparisons with state-of-the-art methods demonstrate the effectiveness and robustness of our proposed method.
Multi-modal Latent Space Learning for Chain-of-Thought Reasoning in Language Models
Dec 14, 2023
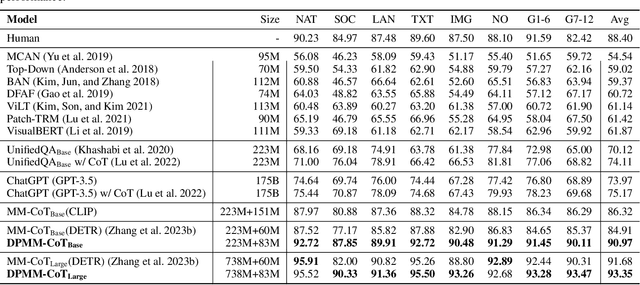
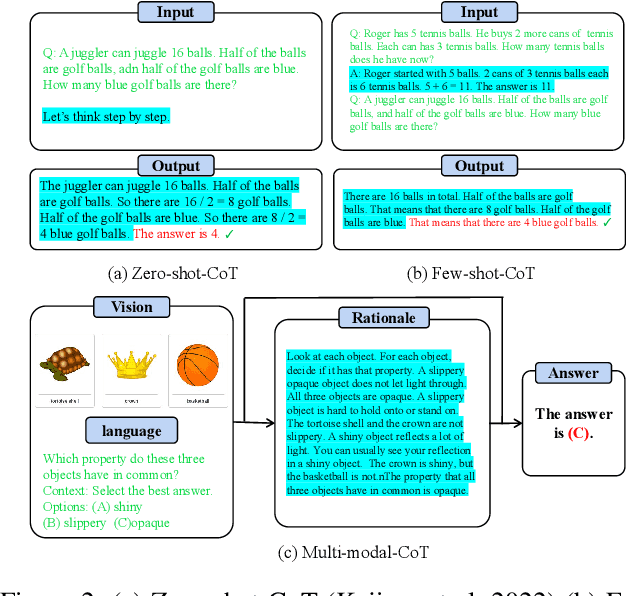
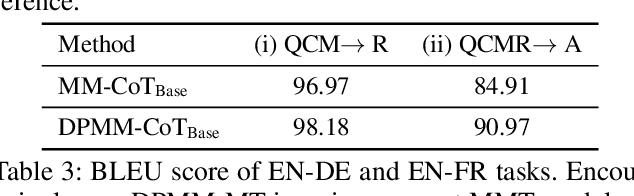
Chain-of-thought (CoT) reasoning has exhibited impressive performance in language models for solving complex tasks and answering questions. However, many real-world questions require multi-modal information, such as text and images. Previous research on multi-modal CoT has primarily focused on extracting fixed image features from off-the-shelf vision models and then fusing them with text using attention mechanisms. This approach has limitations because these vision models were not designed for complex reasoning tasks and do not align well with language thoughts. To overcome this limitation, we introduce a novel approach for multi-modal CoT reasoning that utilizes latent space learning via diffusion processes to generate effective image features that align with language thoughts. Our method fuses image features and text representations at a deep level and improves the complex reasoning ability of multi-modal CoT. We demonstrate the efficacy of our proposed method on multi-modal ScienceQA and machine translation benchmarks, achieving state-of-the-art performance on ScienceQA. Overall, our approach offers a more robust and effective solution for multi-modal reasoning in language models, enhancing their ability to tackle complex real-world problems.
Learning Genomic Sequence Representations using Graph Neural Networks over De Bruijn Graphs
Dec 06, 2023The rapid expansion of genomic sequence data calls for new methods to achieve robust sequence representations. Existing techniques often neglect intricate structural details, emphasizing mainly contextual information. To address this, we developed k-mer embeddings that merge contextual and structural string information by enhancing De Bruijn graphs with structural similarity connections. Subsequently, we crafted a self-supervised method based on Contrastive Learning that employs a heterogeneous Graph Convolutional Network encoder and constructs positive pairs based on node similarities. Our embeddings consistently outperform prior techniques for Edit Distance Approximation and Closest String Retrieval tasks.
Plant Disease Recognition Datasets in the Age of Deep Learning: Challenges and Opportunities
Dec 13, 2023Plant disease recognition has witnessed a significant improvement with deep learning in recent years. Although plant disease datasets are essential and many relevant datasets are public available, two fundamental questions exist. First, how to differentiate datasets and further choose suitable public datasets for specific applications? Second, what kinds of characteristics of datasets are desired to achieve promising performance in real-world applications? To address the questions, this study explicitly propose an informative taxonomy to describe potential plant disease datasets. We further provide several directions for future, such as creating challenge-oriented datasets and the ultimate objective deploying deep learning in real-world applications with satisfactory performance. In addition, existing related public RGB image datasets are summarized. We believe that this study will contributing making better datasets and that this study will contribute beyond plant disease recognition such as plant species recognition. To facilitate the community, our project is public https://github.com/xml94/PPDRD with the information of relevant public datasets.
Accelerated Event-Based Feature Detection and Compression for Surveillance Video Systems
Dec 13, 2023The strong temporal consistency of surveillance video enables compelling compression performance with traditional methods, but downstream vision applications operate on decoded image frames with a high data rate. Since it is not straightforward for applications to extract information on temporal redundancy from the compressed video representations, we propose a novel system which conveys temporal redundancy within a sparse decompressed representation. We leverage a video representation framework called ADDER to transcode framed videos to sparse, asynchronous intensity samples. We introduce mechanisms for content adaptation, lossy compression, and asynchronous forms of classical vision algorithms. We evaluate our system on the VIRAT surveillance video dataset, and we show a median 43.7% speed improvement in FAST feature detection compared to OpenCV. We run the same algorithm as OpenCV, but only process pixels that receive new asynchronous events, rather than process every pixel in an image frame. Our work paves the way for upcoming neuromorphic sensors and is amenable to future applications with spiking neural networks.
Privacy-Preserving Distributed Optimisation using Stochastic PDMM
Dec 13, 2023Privacy-preserving distributed processing has received considerable attention recently. The main purpose of these algorithms is to solve certain signal processing tasks over a network in a decentralised fashion without revealing private/secret data to the outside world. Because of the iterative nature of these distributed algorithms, computationally complex approaches such as (homomorphic) encryption are undesired. Recently, an information theoretic method called subspace perturbation has been introduced for synchronous update schemes. The main idea is to exploit a certain structure in the update equations for noise insertion such that the private data is protected without compromising the algorithm's accuracy. This structure, however, is absent in asynchronous update schemes. In this paper we will investigate such asynchronous schemes and derive a lower bound on the noise variance after random initialisation of the algorithm. This bound shows that the privacy level of asynchronous schemes is always better than or at least equal to that of synchronous schemes. Computer simulations are conducted to consolidate our theoretical results.
TERM Model: Tensor Ring Mixture Model for Density Estimation
Dec 13, 2023Efficient probability density estimation is a core challenge in statistical machine learning. Tensor-based probabilistic graph methods address interpretability and stability concerns encountered in neural network approaches. However, a substantial number of potential tensor permutations can lead to a tensor network with the same structure but varying expressive capabilities. In this paper, we take tensor ring decomposition for density estimator, which significantly reduces the number of permutation candidates while enhancing expressive capability compared with existing used decompositions. Additionally, a mixture model that incorporates multiple permutation candidates with adaptive weights is further designed, resulting in increased expressive flexibility and comprehensiveness. Different from the prevailing directions of tensor network structure/permutation search, our approach provides a new viewpoint inspired by ensemble learning. This approach acknowledges that suboptimal permutations can offer distinctive information besides that of optimal permutations. Experiments show the superiority of the proposed approach in estimating probability density for moderately dimensional datasets and sampling to capture intricate details.