 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Clue Reasoning with Memory Augmentation for Knowledge-based Visual Question Answering
Dec 20, 2023
Visual Question Answering (VQA) has emerged as one of the most challenging tasks in artificial intelligence due to its multi-modal nature. However, most existing VQA methods are incapable of handling Knowledge-based Visual Question Answering (KB-VQA), which requires external knowledge beyond visible contents to answer questions about a given image. To address this issue, we propose a novel framework that endows the model with capabilities of answering more general questions, and achieves a better exploitation of external knowledge through generating Multiple Clues for Reasoning with Memory Neural Networks (MCR-MemNN). Specifically, a well-defined detector is adopted to predict image-question related relation phrases, each of which delivers two complementary clues to retrieve the supporting facts from external knowledge base (KB), which are further encoded into a continuous embedding space using a content-addressable memory. Afterwards, mutual interactions between visual-semantic representation and the supporting facts stored in memory are captured to distill the most relevant information in three modalities (i.e., image, question, and KB). Finally, the optimal answer is predicted by choosing the supporting fact with the highest score. We conduct extensive experiments on two widely-used benchmarks. The experimental results well justify the effectiveness of MCR-MemNN, as well as its superiority over other KB-VQA methods.
End-to-end Rain Streak Removal with RAW Images
Dec 20, 2023In this work we address the problem of rain streak removal with RAW images. The general approach is firstly processing RAW data into RGB images and removing rain streak with RGB images. Actually the original information of rain in RAW images is affected by image signal processing (ISP) pipelines including none-linear algorithms, unexpected noise, artifacts and so on. It gains more benefit to directly remove rain in RAW data before being processed into RGB format. To solve this problem, we propose a joint solution for rain removal and RAW processing to obtain clean color images from rainy RAW image. To be specific, we generate rainy RAW data by converting color rain streak into RAW space and design simple but efficient RAW processing algorithms to synthesize both rainy and clean color images. The rainy color images are used as reference to help color corrections. Different backbones show that our method conduct a better result compared with several other state-of-the-art deraining methods focused on color image. In addition, the proposed network generalizes well to other cameras beyond our selected RAW dataset. Finally, we give the result tested on images processed by different ISP pipelines to show the generalization performance of our model is better compared with methods on color images.
No prejudice! Fair Federated Graph Neural Networks for Personalized Recommendation
Dec 20, 2023Ensuring fairness in Recommendation Systems (RSs) across demographic groups is critical due to the increased integration of RSs in applications such as personalized healthcare, finance, and e-commerce. Graph-based RSs play a crucial role in capturing intricate higher-order interactions among entities. However, integrating these graph models into the Federated Learning (FL) paradigm with fairness constraints poses formidable challenges as this requires access to the entire interaction graph and sensitive user information (such as gender, age, etc.) at the central server. This paper addresses the pervasive issue of inherent bias within RSs for different demographic groups without compromising the privacy of sensitive user attributes in FL environment with the graph-based model. To address the group bias, we propose F2PGNN (Fair Federated Personalized Graph Neural Network), a novel framework that leverages the power of Personalized Graph Neural Network (GNN) coupled with fairness considerations. Additionally, we use differential privacy techniques to fortify privacy protection. Experimental evaluation on three publicly available datasets showcases the efficacy of F2PGNN in mitigating group unfairness by 47% - 99% compared to the state-of-the-art while preserving privacy and maintaining the utility. The results validate the significance of our framework in achieving equitable and personalized recommendations using GNN within the FL landscape.
Leveraging Structured Information for Explainable Multi-hop Question Answering and Reasoning
Nov 07, 2023Neural models, including large language models (LLMs), achieve superior performance on multi-hop question-answering. To elicit reasoning capabilities from LLMs, recent works propose using the chain-of-thought (CoT) mechanism to generate both the reasoning chain and the answer, which enhances the model's capabilities in conducting multi-hop reasoning. However, several challenges still remain: such as struggling with inaccurate reasoning, hallucinations, and lack of interpretability. On the other hand, information extraction (IE) identifies entities, relations, and events grounded to the text. The extracted structured information can be easily interpreted by humans and machines (Grishman, 2019). In this work, we investigate constructing and leveraging extracted semantic structures (graphs) for multi-hop question answering, especially the reasoning process. Empirical results and human evaluations show that our framework: generates more faithful reasoning chains and substantially improves the QA performance on two benchmark datasets. Moreover, the extracted structures themselves naturally provide grounded explanations that are preferred by humans, as compared to the generated reasoning chains and saliency-based explanations.
3-D Distributed Localization with Mixed Local Relative Measurements
Dec 18, 2023This paper studies 3-D distributed network localization using mixed types of local relative measurements. Each node holds a local coordinate frame without a common orientation and can only measure one type of information (relative position, distance, relative bearing, angle, or ratio-of-distance measurements) about its neighboring nodes in its local coordinate frame. A novel rigidity-theory-based distributed localization is developed to overcome the challenge due to the absence of a global coordinate frame. The main idea is to construct displacement constraints for the positions of the nodes by using mixed local relative measurements. Then, a linear distributed localization algorithm is proposed for each free node to estimate its position by solving the displacement constraints. The algebraic condition and graph condition are obtained to guarantee the global convergence of the proposed distributed localization algorithm.
Discretionary Trees: Understanding Street-Level Bureaucracy via Machine Learning
Dec 17, 2023
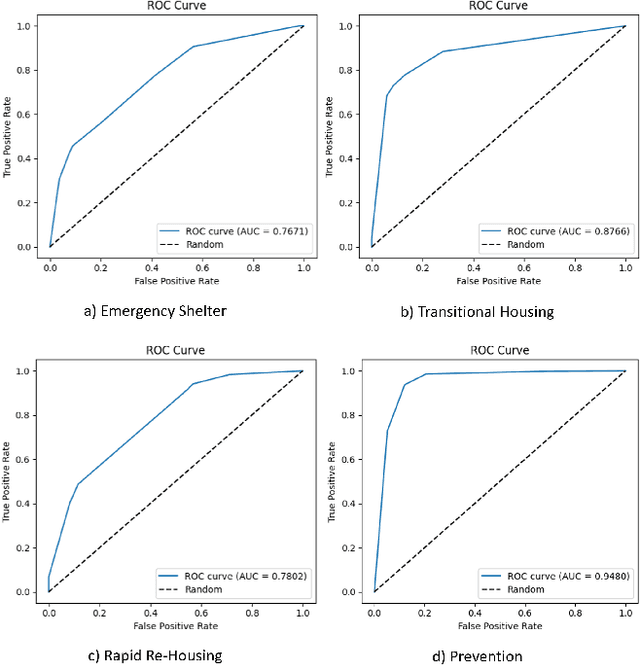

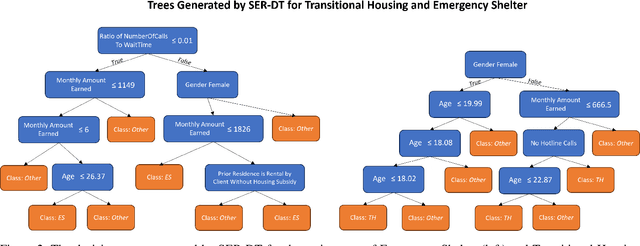
Street-level bureaucrats interact directly with people on behalf of government agencies to perform a wide range of functions, including, for example, administering social services and policing. A key feature of street-level bureaucracy is that the civil servants, while tasked with implementing agency policy, are also granted significant discretion in how they choose to apply that policy in individual cases. Using that discretion could be beneficial, as it allows for exceptions to policies based on human interactions and evaluations, but it could also allow biases and inequities to seep into important domains of societal resource allocation. In this paper, we use machine learning techniques to understand street-level bureaucrats' behavior. We leverage a rich dataset that combines demographic and other information on households with information on which homelessness interventions they were assigned during a period when assignments were not formulaic. We find that caseworker decisions in this time are highly predictable overall, and some, but not all of this predictivity can be captured by simple decision rules. We theorize that the decisions not captured by the simple decision rules can be considered applications of caseworker discretion. These discretionary decisions are far from random in both the characteristics of such households and in terms of the outcomes of the decisions. Caseworkers typically only apply discretion to households that would be considered less vulnerable. When they do apply discretion to assign households to more intensive interventions, the marginal benefits to those households are significantly higher than would be expected if the households were chosen at random; there is no similar reduction in marginal benefit to households that are discretionarily allocated less intensive interventions, suggesting that caseworkers are improving outcomes using their knowledge.
DreamTuner: Single Image is Enough for Subject-Driven Generation
Dec 21, 2023Diffusion-based models have demonstrated impressive capabilities for text-to-image generation and are expected for personalized applications of subject-driven generation, which require the generation of customized concepts with one or a few reference images. However, existing methods based on fine-tuning fail to balance the trade-off between subject learning and the maintenance of the generation capabilities of pretrained models. Moreover, other methods that utilize additional image encoders tend to lose important details of the subject due to encoding compression. To address these challenges, we propose DreamTurner, a novel method that injects reference information from coarse to fine to achieve subject-driven image generation more effectively. DreamTurner introduces a subject-encoder for coarse subject identity preservation, where the compressed general subject features are introduced through an attention layer before visual-text cross-attention. We then modify the self-attention layers within pretrained text-to-image models to self-subject-attention layers to refine the details of the target subject. The generated image queries detailed features from both the reference image and itself in self-subject-attention. It is worth emphasizing that self-subject-attention is an effective, elegant, and training-free method for maintaining the detailed features of customized subjects and can serve as a plug-and-play solution during inference. Finally, with additional subject-driven fine-tuning, DreamTurner achieves remarkable performance in subject-driven image generation, which can be controlled by a text or other conditions such as pose. For further details, please visit the project page at https://dreamtuner-diffusion.github.io/.
Enhancing Cognitive Diagnosis using Un-interacted Exercises: A Collaboration-aware Mixed Sampling Approach
Dec 15, 2023Cognitive diagnosis is a crucial task in computational education, aimed at evaluating students' proficiency levels across various knowledge concepts through exercises. Current models, however, primarily rely on students' answered exercises, neglecting the complex and rich information contained in un-interacted exercises. While recent research has attempted to leverage the data within un-interacted exercises linked to interacted knowledge concepts, aiming to address the long-tail issue, these studies fail to fully explore the informative, un-interacted exercises related to broader knowledge concepts. This oversight results in diminished performance when these models are applied to comprehensive datasets. In response to this gap, we present the Collaborative-aware Mixed Exercise Sampling (CMES) framework, which can effectively exploit the information present in un-interacted exercises linked to un-interacted knowledge concepts. Specifically, we introduce a novel universal sampling module where the training samples comprise not merely raw data slices, but enhanced samples generated by combining weight-enhanced attention mixture techniques. Given the necessity of real response labels in cognitive diagnosis, we also propose a ranking-based pseudo feedback module to regulate students' responses on generated exercises. The versatility of the CMES framework bolsters existing models and improves their adaptability. Finally, we demonstrate the effectiveness and interpretability of our framework through comprehensive experiments on real-world datasets.
EmbAu: A Novel Technique to Embed Audio Data Using Shuffled Frog Leaping Algorithm
Dec 13, 2023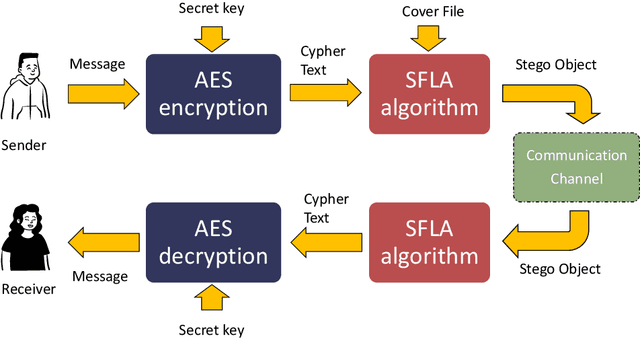



The aim of steganographic algorithms is to identify the appropriate pixel positions in the host or cover image, where bits of sensitive information can be concealed for data encryption. Work is being done to improve the capacity to integrate sensitive information and to maintain the visual appearance of the steganographic image. Consequently, steganography is a challenging research area. In our currently proposed image steganographic technique, we used the Shuffled Frog Leaping Algorithm (SFLA) to determine the order of pixels by which sensitive information can be placed in the cover image. To achieve greater embedding capacity, pixels from the spatial domain of the cover image are carefully chosen and used for placing the sensitive data. Bolstered via image steganography, the final image after embedding is resistant to steganalytic attacks. The SFLA algorithm serves in the optimal pixels selection of any colored (RGB) cover image for secret bit embedding. Using the fitness function, the SFLA benefits by reaching a minimum cost value in an acceptable amount of time. The pixels for embedding are meticulously chosen to minimize the host image's distortion upon embedding. Moreover, an effort has been taken to make the detection of embedded data in the steganographic image a formidable challenge. Due to the enormous need for audio data encryption in the current world, we feel that our suggested method has significant potential in real-world applications. In this paper, we propose and compare our strategy to existing steganographic methods.
Spot the Bot: Distinguishing Human-Written and Bot-Generated Texts Using Clustering and Information Theory Techniques
Nov 19, 2023With the development of generative models like GPT-3, it is increasingly more challenging to differentiate generated texts from human-written ones. There is a large number of studies that have demonstrated good results in bot identification. However, the majority of such works depend on supervised learning methods that require labelled data and/or prior knowledge about the bot-model architecture. In this work, we propose a bot identification algorithm that is based on unsupervised learning techniques and does not depend on a large amount of labelled data. By combining findings in semantic analysis by clustering (crisp and fuzzy) and information techniques, we construct a robust model that detects a generated text for different types of bot. We find that the generated texts tend to be more chaotic while literary works are more complex. We also demonstrate that the clustering of human texts results in fuzzier clusters in comparison to the more compact and well-separated clusters of bot-generated texts.