 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AccidentGPT: Accident analysis and prevention from V2X Environmental Perception with Multi-modal Large Model
Dec 20, 2023
Traffic accidents, being a significant contributor to both human casualties and property damage, have long been a focal point of research for many scholars in the field of traffic safety. However, previous studies, whether focusing on static environmental assessments or dynamic driving analyses, as well as pre-accident predictions or post-accident rule analyses, have typically been conducted in isolation. There has been a lack of an effective framework for developing a comprehensive understanding and application of traffic safety. To address this gap, this paper introduces AccidentGPT, a comprehensive accident analysis and prevention multi-modal large model. AccidentGPT establishes a multi-modal information interaction framework grounded in multi-sensor perception, thereby enabling a holistic approach to accident analysis and prevention in the field of traffic safety. Specifically, our capabilities can be categorized as follows: for autonomous driving vehicles, we provide comprehensive environmental perception and understanding to control the vehicle and avoid collisions. For human-driven vehicles, we offer proactive long-range safety warnings and blind-spot alerts while also providing safety driving recommendations and behavioral norms through human-machine dialogue and interaction. Additionally, for traffic police and management agencies, our framework supports intelligent and real-time analysis of traffic safety, encompassing pedestrian, vehicles, roads, and the environment through collaborative perception from multiple vehicles and road testing devices. The system is also capable of providing a thorough analysis of accident causes and liability after vehicle collisions. Our framework stands as the first large model to integrate comprehensive scene understanding into traffic safety studies.
Federated Learning with Extremely Noisy Clients via Negative Distillation
Dec 20, 2023Federated learning (FL) has shown remarkable success in cooperatively training deep models, while typically struggling with noisy labels. Advanced works propose to tackle label noise by a re-weighting strategy with a strong assumption, i.e., mild label noise. However, it may be violated in many real-world FL scenarios because of highly contaminated clients, resulting in extreme noise ratios, e.g., $>$90%. To tackle extremely noisy clients, we study the robustness of the re-weighting strategy, showing a pessimistic conclusion: minimizing the weight of clients trained over noisy data outperforms re-weighting strategies. To leverage models trained on noisy clients, we propose a novel approach, called negative distillation (FedNed). FedNed first identifies noisy clients and employs rather than discards the noisy clients in a knowledge distillation manner. In particular, clients identified as noisy ones are required to train models using noisy labels and pseudo-labels obtained by global models. The model trained on noisy labels serves as a `bad teacher' in knowledge distillation, aiming to decrease the risk of providing incorrect information. Meanwhile, the model trained on pseudo-labels is involved in model aggregation if not identified as a noisy client. Consequently, through pseudo-labeling, FedNed gradually increases the trustworthiness of models trained on noisy clients, while leveraging all clients for model aggregation through negative distillation. To verify the efficacy of FedNed, we conduct extensive experiments under various settings, demonstrating that FedNed can consistently outperform baselines and achieve state-of-the-art performance. Our code is available at https://github.com/linChen99/FedNed.
Hybrid Sample Synthesis-based Debiasing of Classifier in Limited Data Setting
Dec 20, 2023Deep learning models are known to suffer from the problem of bias, and researchers have been exploring methods to address this issue. However, most of these methods require prior knowledge of the bias and are not always practical. In this paper, we focus on a more practical setting with no prior information about the bias. Generally, in this setting, there are a large number of bias-aligned samples that cause the model to produce biased predictions and a few bias-conflicting samples that do not conform to the bias. If the training data is limited, the influence of the bias-aligned samples may become even stronger on the model predictions, and we experimentally demonstrate that existing debiasing techniques suffer severely in such cases. In this paper, we examine the effects of unknown bias in small dataset regimes and present a novel approach to mitigate this issue. The proposed approach directly addresses the issue of the extremely low occurrence of bias-conflicting samples in limited data settings through the synthesis of hybrid samples that can be used to reduce the effect of bias. We perform extensive experiments on several benchmark datasets and experimentally demonstrate the effectiveness of our proposed approach in addressing any unknown bias in the presence of limited data. Specifically, our approach outperforms the vanilla, LfF, LDD, and DebiAN debiasing methods by absolute margins of 10.39%, 9.08%, 8.07%, and 9.67% when only 10% of the Corrupted CIFAR-10 Type 1 dataset is available with a bias-conflicting sample ratio of 0.05.
Alignment is not sufficient to prevent large language models from generating harmful information: A psychoanalytic perspective
Nov 14, 2023Large Language Models (LLMs) are central to a multitude of applications but struggle with significant risks, notably in generating harmful content and biases. Drawing an analogy to the human psyche's conflict between evolutionary survival instincts and societal norm adherence elucidated in Freud's psychoanalysis theory, we argue that LLMs suffer a similar fundamental conflict, arising between their inherent desire for syntactic and semantic continuity, established during the pre-training phase, and the post-training alignment with human values. This conflict renders LLMs vulnerable to adversarial attacks, wherein intensifying the models' desire for continuity can circumvent alignment efforts, resulting in the generation of harmful information. Through a series of experiments, we first validated the existence of the desire for continuity in LLMs, and further devised a straightforward yet powerful technique, such as incomplete sentences, negative priming, and cognitive dissonance scenarios, to demonstrate that even advanced LLMs struggle to prevent the generation of harmful information. In summary, our study uncovers the root of LLMs' vulnerabilities to adversarial attacks, hereby questioning the efficacy of solely relying on sophisticated alignment methods, and further advocates for a new training idea that integrates modal concepts alongside traditional amodal concepts, aiming to endow LLMs with a more nuanced understanding of real-world contexts and ethical considerations.
Cross-modal Contrastive Learning with Asymmetric Co-attention Network for Video Moment Retrieval
Dec 12, 2023Video moment retrieval is a challenging task requiring fine-grained interactions between video and text modalities. Recent work in image-text pretraining has demonstrated that most existing pretrained models suffer from information asymmetry due to the difference in length between visual and textual sequences. We question whether the same problem also exists in the video-text domain with an auxiliary need to preserve both spatial and temporal information. Thus, we evaluate a recently proposed solution involving the addition of an asymmetric co-attention network for video grounding tasks. Additionally, we incorporate momentum contrastive loss for robust, discriminative representation learning in both modalities. We note that the integration of these supplementary modules yields better performance compared to state-of-the-art models on the TACoS dataset and comparable results on ActivityNet Captions, all while utilizing significantly fewer parameters with respect to baseline.
Beyond the Label Itself: Latent Labels Enhance Semi-supervised Point Cloud Panoptic Segmentation
Dec 13, 2023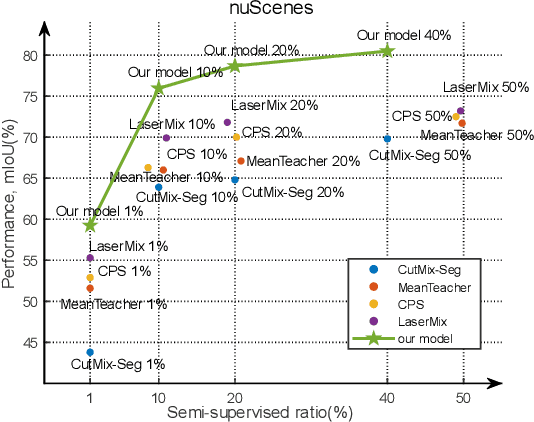
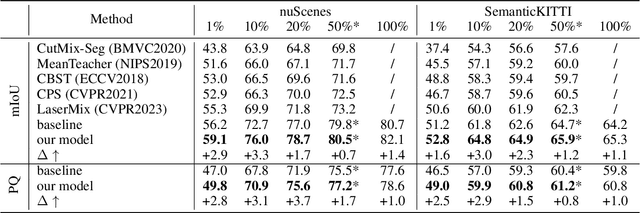

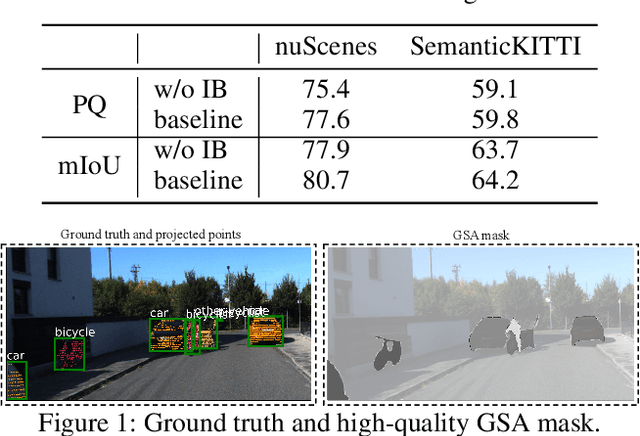
As the exorbitant expense of labeling autopilot datasets and the growing trend of utilizing unlabeled data, semi-supervised segmentation on point clouds becomes increasingly imperative. Intuitively, finding out more ``unspoken words'' (i.e., latent instance information) beyond the label itself should be helpful to improve performance. In this paper, we discover two types of latent labels behind the displayed label embedded in LiDAR and image data. First, in the LiDAR Branch, we propose a novel augmentation, Cylinder-Mix, which is able to augment more yet reliable samples for training. Second, in the Image Branch, we propose the Instance Position-scale Learning (IPSL) Module to learn and fuse the information of instance position and scale, which is from a 2D pre-trained detector and a type of latent label obtained from 3D to 2D projection. Finally, the two latent labels are embedded into the multi-modal panoptic segmentation network. The ablation of the IPSL module demonstrates its robust adaptability, and the experiments evaluated on SemanticKITTI and nuScenes demonstrate that our model outperforms the state-of-the-art method, LaserMix.
Helping Language Models Learn More: Multi-dimensional Task Prompt for Few-shot Tuning
Dec 13, 2023Large language models (LLMs) can be used as accessible and intelligent chatbots by constructing natural language queries and directly inputting the prompt into the large language model. However, different prompt' constructions often lead to uncertainty in the answers and thus make it hard to utilize the specific knowledge of LLMs (like ChatGPT). To alleviate this, we use an interpretable structure to explain the prompt learning principle in LLMs, which certificates that the effectiveness of language models is determined by position changes of the task's related tokens. Therefore, we propose MTPrompt, a multi-dimensional task prompt learning method consisting based on task-related object, summary, and task description information. By automatically building and searching for appropriate prompts, our proposed MTPrompt achieves the best results on few-shot samples setting and five different datasets. In addition, we demonstrate the effectiveness and stability of our method in different experimental settings and ablation experiments. In interaction with large language models, embedding more task-related information into prompts will make it easier to stimulate knowledge embedded in large language models.
Mono3DVG: 3D Visual Grounding in Monocular Images
Dec 13, 2023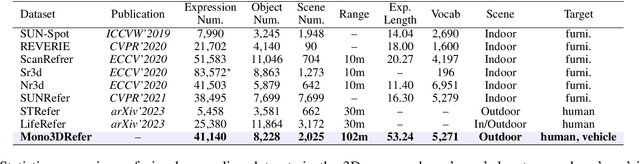


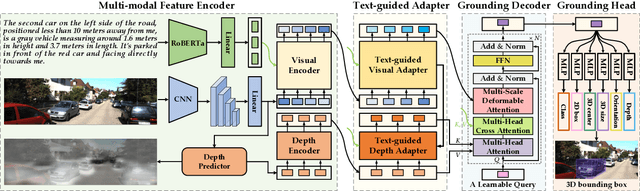
We introduce a novel task of 3D visual grounding in monocular RGB images using language descriptions with both appearance and geometry information. Specifically, we build a large-scale dataset, Mono3DRefer, which contains 3D object targets with their corresponding geometric text descriptions, generated by ChatGPT and refined manually. To foster this task, we propose Mono3DVG-TR, an end-to-end transformer-based network, which takes advantage of both the appearance and geometry information in text embeddings for multi-modal learning and 3D object localization. Depth predictor is designed to explicitly learn geometry features. The dual text-guided adapter is proposed to refine multiscale visual and geometry features of the referred object. Based on depth-text-visual stacking attention, the decoder fuses object-level geometric cues and visual appearance into a learnable query. Comprehensive benchmarks and some insightful analyses are provided for Mono3DVG. Extensive comparisons and ablation studies show that our method significantly outperforms all baselines. The dataset and code will be publicly available at: https://github.com/ZhanYang-nwpu/Mono3DVG.
Flow Matching Beyond Kinematics: Generating Jets with Particle-ID and Trajectory Displacement Information
Nov 30, 2023We introduce the first generative model trained on the JetClass dataset. Our model generates jets at the constituent level, and it is a permutation-equivariant continuous normalizing flow (CNF) trained with the flow matching technique. It is conditioned on the jet type, so that a single model can be used to generate the ten different jet types of JetClass. For the first time, we also introduce a generative model that goes beyond the kinematic features of jet constituents. The JetClass dataset includes more features, such as particle-ID and track impact parameter, and we demonstrate that our CNF can accurately model all of these additional features as well. Our generative model for JetClass expands on the versatility of existing jet generation techniques, enhancing their potential utility in high-energy physics research, and offering a more comprehensive understanding of the generated jets.
Metalearning with Very Few Samples Per Task
Dec 21, 2023Metalearning and multitask learning are two frameworks for solving a group of related learning tasks more efficiently than we could hope to solve each of the individual tasks on their own. In multitask learning, we are given a fixed set of related learning tasks and need to output one accurate model per task, whereas in metalearning we are given tasks that are drawn i.i.d. from a metadistribution and need to output some common information that can be easily specialized to new, previously unseen tasks from the metadistribution. In this work, we consider a binary classification setting where tasks are related by a shared representation, that is, every task $P$ of interest can be solved by a classifier of the form $f_{P} \circ h$ where $h \in H$ is a map from features to some representation space that is shared across tasks, and $f_{P} \in F$ is a task-specific classifier from the representation space to labels. The main question we ask in this work is how much data do we need to metalearn a good representation? Here, the amount of data is measured in terms of both the number of tasks $t$ that we need to see and the number of samples $n$ per task. We focus on the regime where the number of samples per task is extremely small. Our main result shows that, in a distribution-free setting where the feature vectors are in $\mathbb{R}^d$, the representation is a linear map from $\mathbb{R}^d \to \mathbb{R}^k$, and the task-specific classifiers are halfspaces in $\mathbb{R}^k$, we can metalearn a representation with error $\varepsilon$ using just $n = k+2$ samples per task, and $d \cdot (1/\varepsilon)^{O(k)}$ tasks. Learning with so few samples per task is remarkable because metalearning would be impossible with $k+1$ samples per task, and because we cannot even hope to learn an accurate task-specific classifier with just $k+2$ samples per task.