 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Keypoint-based Stereophotoclinometry for Characterizing and Navigating Small Bodies: A Factor Graph Approach
Dec 11, 2023
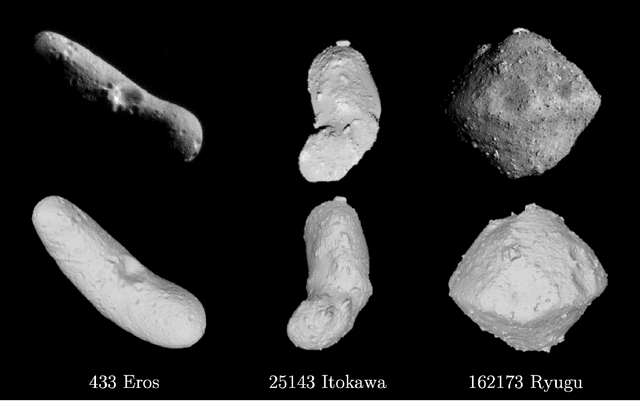

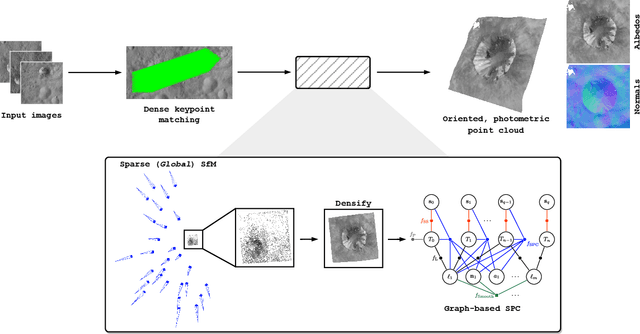

This paper proposes the incorporation of techniques from stereophotoclinometry (SPC) into a keypoint-based structure-from-motion (SfM) system to estimate the surface normal and albedo at detected landmarks to improve autonomous surface and shape characterization of small celestial bodies from in-situ imagery. In contrast to the current state-of-the-practice method for small body shape reconstruction, i.e., SPC, which relies on human-in-the-loop verification and high-fidelity a priori information to achieve accurate results, we forego the expensive maplet estimation step and instead leverage dense keypoint measurements and correspondences from an autonomous keypoint detection and matching method based on deep learning to provide the necessary photogrammetric constraints. Moreover, we develop a factor graph-based approach allowing for simultaneous optimization of the spacecraft's pose, landmark positions, Sun-relative direction, and surface normals and albedos via fusion of Sun sensor measurements and image keypoint measurements. The proposed framework is validated on real imagery of the Cornelia crater on Asteroid 4 Vesta, along with pose estimation and mapping comparison against an SPC reconstruction, where we demonstrate precise alignment to the SPC solution without relying on any a priori camera pose and topography information or humans-in-the-loop
FRNet: Frustum-Range Networks for Scalable LiDAR Segmentation
Dec 07, 2023LiDAR segmentation is crucial for autonomous driving systems. The recent range-view approaches are promising for real-time processing. However, they suffer inevitably from corrupted contextual information and rely heavily on post-processing techniques for prediction refinement. In this work, we propose a simple yet powerful FRNet that restores the contextual information of the range image pixels with corresponding frustum LiDAR points. Firstly, a frustum feature encoder module is used to extract per-point features within the frustum region, which preserves scene consistency and is crucial for point-level predictions. Next, a frustum-point fusion module is introduced to update per-point features hierarchically, which enables each point to extract more surrounding information via the frustum features. Finally, a head fusion module is used to fuse features at different levels for final semantic prediction. Extensive experiments on four popular LiDAR segmentation benchmarks under various task setups demonstrate our superiority. FRNet achieves competitive performance while maintaining high efficiency. The code is publicly available.
Classification for everyone : Building geography agnostic models for fairer recognition
Dec 11, 2023In this paper, we analyze different methods to mitigate inherent geographical biases present in state of the art image classification models. We first quantitatively present this bias in two datasets - The Dollar Street Dataset and ImageNet, using images with location information. We then present different methods which can be employed to reduce this bias. Finally, we analyze the effectiveness of the different techniques on making these models more robust to geographical locations of the images.
OctreeOcc: Efficient and Multi-Granularity Occupancy Prediction Using Octree Queries
Dec 09, 2023Occupancy prediction has increasingly garnered attention in recent years for its fine-grained understanding of 3D scenes. Traditional approaches typically rely on dense, regular grid representations, which often leads to excessive computational demands and a loss of spatial details for small objects. This paper introduces OctreeOcc, an innovative 3D occupancy prediction framework that leverages the octree representation to adaptively capture valuable information in 3D, offering variable granularity to accommodate object shapes and semantic regions of varying sizes and complexities. In particular, we incorporate image semantic information to improve the accuracy of initial octree structures and design an effective rectification mechanism to refine the octree structure iteratively. Our extensive evaluations show that OctreeOcc not only surpasses state-of-the-art methods in occupancy prediction, but also achieves a 15%-24% reduction in computational overhead compared to dense-grid-based methods.
RAPID: Training-free Retrieval-based Log Anomaly Detection with PLM considering Token-level information
Nov 09, 2023As the IT industry advances, system log data becomes increasingly crucial. Many computer systems rely on log texts for management due to restricted access to source code. The need for log anomaly detection is growing, especially in real-world applications, but identifying anomalies in rapidly accumulating logs remains a challenging task. Traditional deep learning-based anomaly detection models require dataset-specific training, leading to corresponding delays. Notably, most methods only focus on sequence-level log information, which makes the detection of subtle anomalies harder, and often involve inference processes that are difficult to utilize in real-time. We introduce RAPID, a model that capitalizes on the inherent features of log data to enable anomaly detection without training delays, ensuring real-time capability. RAPID treats logs as natural language, extracting representations using pre-trained language models. Given that logs can be categorized based on system context, we implement a retrieval-based technique to contrast test logs with the most similar normal logs. This strategy not only obviates the need for log-specific training but also adeptly incorporates token-level information, ensuring refined and robust detection, particularly for unseen logs. We also propose the core set technique, which can reduce the computational cost needed for comparison. Experimental results show that even without training on log data, RAPID demonstrates competitive performance compared to prior models and achieves the best performance on certain datasets. Through various research questions, we verified its capability for real-time detection without delay.
Simulation-based Evaluation of Indoor Positioning Systems in Connected Aircraft Cabins
Dec 14, 2023The manuscript discusses the increasing use of location-aware radio communication systems to support operational processes for the demanding aircraft cabin environment. In this context, the challenges for evaluation and integration of radio-based localization systems in the connected cabin are specifically addressed by proposing a hybrid deterministic and stochastic simulation approach, including both model-based ray-tracing and empirical residual simulation. The simulation approach is detailed in the manuscript and a methodology for applying and evaluating localization methods based on obtained geometric relations is conducted. This can also be used as a data generation and validation tool for data-driven localization methods, which further increase the localization accuracy and robustness. The derived location information can in return be used in order to perform operational prediction and optimization for efficient and sustainable passenger handling. A dataset derived from the introduced simulation platform is publicly available.
PySCIPOpt-ML: Embedding Trained Machine Learning Models into Mixed-Integer Programs
Dec 13, 2023A standard tool for modelling real-world optimisation problems is mixed-integer programming (MIP). However, for many of these problems there is either incomplete information describing variable relations, or the relations between variables are highly complex. To overcome both these hurdles, machine learning (ML) models are often used and embedded in the MIP as surrogate models to represent these relations. Due to the large amount of available ML frameworks, formulating ML models into MIPs is highly non-trivial. In this paper we propose a tool for the automatic MIP formulation of trained ML models, allowing easy integration of ML constraints into MIPs. In addition, we introduce a library of MIP instances with embedded ML constraints. The project is available at https://github.com/Opt-Mucca/PySCIPOpt-ML.
Interpretable Diffusion via Information Decomposition
Oct 12, 2023


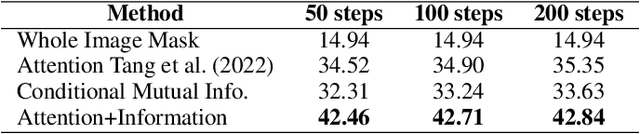
Denoising diffusion models enable conditional generation and density modeling of complex relationships like images and text. However, the nature of the learned relationships is opaque making it difficult to understand precisely what relationships between words and parts of an image are captured, or to predict the effect of an intervention. We illuminate the fine-grained relationships learned by diffusion models by noticing a precise relationship between diffusion and information decomposition. Exact expressions for mutual information and conditional mutual information can be written in terms of the denoising model. Furthermore, pointwise estimates can be easily estimated as well, allowing us to ask questions about the relationships between specific images and captions. Decomposing information even further to understand which variables in a high-dimensional space carry information is a long-standing problem. For diffusion models, we show that a natural non-negative decomposition of mutual information emerges, allowing us to quantify informative relationships between words and pixels in an image. We exploit these new relations to measure the compositional understanding of diffusion models, to do unsupervised localization of objects in images, and to measure effects when selectively editing images through prompt interventions.
Tender Notice Extraction from E-papers Using Neural Network
Dec 16, 2023Tender notices are usually sought by most of the companies at regular intervals as a means for obtaining the contracts of various projects. These notices consist of all the required information like description of the work, period of construction, estimated amount of project, etc. In the context of Nepal, tender notices are usually published in national as well as local newspapers. The interested bidders should search all the related tender notices in newspapers. However, it is very tedious for these companies to manually search tender notices in every newspaper and figure out which bid is best suited for them. This project is built with the purpose of solving this tedious task of manually searching the tender notices. Initially, the newspapers are downloaded in PDF format using the selenium library of python. After downloading the newspapers, the e-papers are scanned and tender notices are automatically extracted using a neural network. For extraction purposes, different architectures of CNN namely ResNet, GoogleNet and Xception are used and a model with highest performance has been implemented. Finally, these extracted notices are then published on the website and are accessible to the users. This project is helpful for construction companies as well as contractors assuring quality and efficiency. This project has great application in the field of competitive bidding as well as managing them in a systematic manner.
M2ConceptBase: A Fine-grained Aligned Multi-modal Conceptual Knowledge Base
Dec 16, 2023Large multi-modal models (LMMs) have demonstrated promising intelligence owing to the rapid development of pre-training techniques. However, their fine-grained cross-modal alignment ability is constrained by the coarse alignment in image-text pairs. This limitation hinders awareness of fine-grained concepts, resulting in sub-optimal performance. In this paper, we propose a multi-modal conceptual knowledge base, named M2ConceptBase, which aims to provide fine-grained alignment between images and concepts. Specifically, M2ConceptBase models concepts as nodes, associating each with relevant images and detailed text, thereby enhancing LMMs' cross-modal alignment with rich conceptual knowledge. To collect concept-image and concept-description alignments, we propose a context-aware multi-modal symbol grounding approach that considers context information in existing large-scale image-text pairs with respect to each concept. A cutting-edge large language model supplements descriptions for concepts not grounded via our symbol grounding approach. Finally, our M2ConceptBase contains more than 951K images and 152K concepts, each associating with an average of 6.27 images and a single detailed description. We conduct experiments on the OK-VQA task, demonstrating that our M2ConceptBase facilitates the model in achieving state-of-the-art performance. Moreover, we construct a comprehensive benchmark to evaluate the concept understanding of LMMs and show that M2ConceptBase could effectively improve LMMs' concept understanding and cross-modal alignment abilities.