 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CARAT: Contrastive Feature Reconstruction and Aggregation for Multi-modal Multi-label Emotion Recognition
Dec 15, 2023
Multi-modal multi-label emotion recognition (MMER) aims to identify relevant emotions from multiple modalities. The challenge of MMER is how to effectively capture discriminative features for multiple labels from heterogeneous data. Recent studies are mainly devoted to exploring various fusion strategies to integrate multi-modal information into a unified representation for all labels. However, such a learning scheme not only overlooks the specificity of each modality but also fails to capture individual discriminative features for different labels. Moreover, dependencies of labels and modalities cannot be effectively modeled. To address these issues, this paper presents ContrAstive feature Reconstruction and AggregaTion (CARAT) for the MMER task. Specifically, we devise a reconstruction-based fusion mechanism to better model fine-grained modality-to-label dependencies by contrastively learning modal-separated and label-specific features. To further exploit the modality complementarity, we introduce a shuffle-based aggregation strategy to enrich co-occurrence collaboration among labels. Experiments on two benchmark datasets CMU-MOSEI and M3ED demonstrate the effectiveness of CARAT over state-of-the-art methods. Code is available at https://github.com/chengzju/CARAT.
Asset Ownership Identification: Using machine learning to predict enterprise asset ownership
Dec 15, 2023Asset owner identification is an important first step for any information security organization, allowing organizations the ability to identify and detect data breaches and losses, vulnerabilities, possible attack surfaces, and define effective countermeasures. Using existing asset ownership data, the research utilized an assortment of machine learning algorithms to determine the best classification model to predict an asset's owner. The research ran separate analyses for each enumerated team, then ran a 100 iteration Monte Carlo Cross Validation across Adaboost, Logistic Regression, Naive Bayes, Classification and Regression Trees, and Random Forests. Finally, a visualization dashboard was created to help users understand the asset inventory through interactive exploratory data analysis as well as the ability to understand model evaluation metrics including accuracy, sensitivity, and specificity for each model. Overall, Adaboost performed the best across all owners with low testing errors below 5% while Naive Bayes performed the worst. The remaining models performed similarly. The fully qualified domain name (FQDN), Classless Inter-Domain Routing (CIDR) CIDR/16, and location were among the most important features.
Implicit Modeling of Non-rigid Objects with Cross-Category Signals
Dec 15, 2023Deep implicit functions (DIFs) have emerged as a potent and articulate means of representing 3D shapes. However, methods modeling object categories or non-rigid entities have mainly focused on single-object scenarios. In this work, we propose MODIF, a multi-object deep implicit function that jointly learns the deformation fields and instance-specific latent codes for multiple objects at once. Our emphasis is on non-rigid, non-interpenetrating entities such as organs. To effectively capture the interrelation between these entities and ensure precise, collision-free representations, our approach facilitates signaling between category-specific fields to adequately rectify shapes. We also introduce novel inter-object supervision: an attraction-repulsion loss is formulated to refine contact regions between objects. Our approach is demonstrated on various medical benchmarks, involving modeling different groups of intricate anatomical entities. Experimental results illustrate that our model can proficiently learn the shape representation of each organ and their relations to others, to the point that shapes missing from unseen instances can be consistently recovered by our method. Finally, MODIF can also propagate semantic information throughout the population via accurate point correspondences
* Accepted at AAAI 2024. Paper + supplementary material
Towards Neuromorphic Compression based Neural Sensing for Next-Generation Wireless Implantable Brain Machine Interface
Dec 15, 2023This work introduces a neuromorphic compression based neural sensing architecture with address-event representation inspired readout protocol for massively parallel, next-gen wireless iBMI. The architectural trade-offs and implications of the proposed method are quantitatively analyzed in terms of compression ratio and spike information preservation. For the latter, we use metrics such as root-mean-square error and correlation coefficient between the original and recovered signal to assess the effect of neuromorphic compression on spike shape. Furthermore, we use accuracy, sensitivity, and false detection rate to understand the effect of compression on downstream iBMI tasks, specifically, spike detection. We demonstrate that a data compression ratio of $50-100$ can be achieved, $5-18\times$ more than prior work, by selective transmission of event pulses corresponding to neural spikes. A correlation coefficient of $\approx0.9$ and spike detection accuracy of over $90\%$ for the worst-case analysis involving $10K$-channel simulated recording and typical analysis using $100$ or $384$-channel real neural recordings. We also analyze the collision handling capability and scalability of the proposed pipeline.
Harnessing Retrieval-Augmented Generation (RAG) for Uncovering Knowledge Gaps
Dec 12, 2023The paper presents a methodology for uncovering knowledge gaps on the internet using the Retrieval Augmented Generation (RAG) model. By simulating user search behaviour, the RAG system identifies and addresses gaps in information retrieval systems. The study demonstrates the effectiveness of the RAG system in generating relevant suggestions with a consistent accuracy of 93%. The methodology can be applied in various fields such as scientific discovery, educational enhancement, research development, market analysis, search engine optimisation, and content development. The results highlight the value of identifying and understanding knowledge gaps to guide future endeavours.
Leveraging AI-derived Data for Carbon Accounting: Information Extraction from Alternative Sources
Nov 26, 2023Carbon accounting is a fundamental building block in our global path to emissions reduction and decarbonization, yet many challenges exist in achieving reliable and trusted carbon accounting measures. We motivate that carbon accounting not only needs to be more data-driven, but also more methodologically sound. We discuss the need for alternative, more diverse data sources that can play a significant role on our path to trusted carbon accounting procedures and elaborate on not only why, but how Artificial Intelligence (AI) in general and Natural Language Processing (NLP) in particular can unlock reasonable access to a treasure trove of alternative data sets in light of the recent advances in the field that better enable the utilization of unstructured data in this process. We present a case study of the recent developments on real-world data via an NLP-powered analysis using OpenAI's GPT API on financial and shipping data. We conclude the paper with a discussion on how these methods and approaches can be integrated into a broader framework for AI-enabled integrative carbon accounting.
Keypoint-based Stereophotoclinometry for Characterizing and Navigating Small Bodies: A Factor Graph Approach
Dec 11, 2023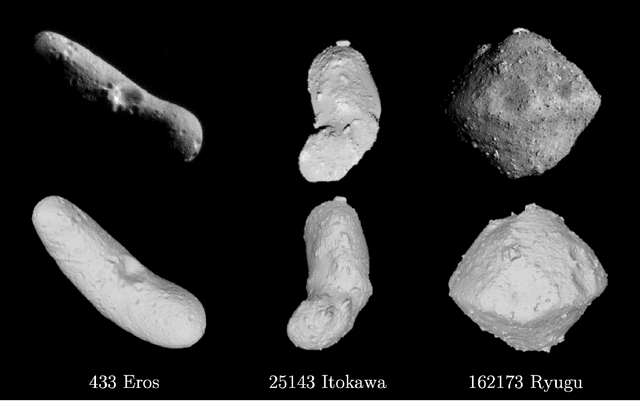

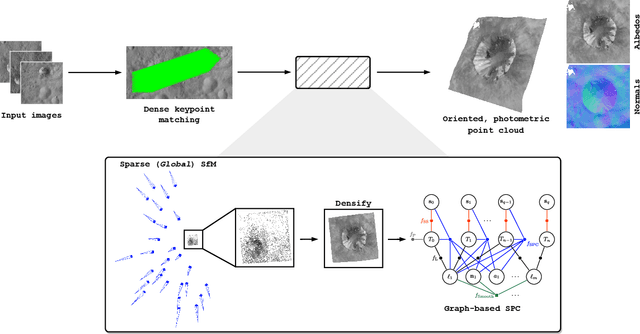

This paper proposes the incorporation of techniques from stereophotoclinometry (SPC) into a keypoint-based structure-from-motion (SfM) system to estimate the surface normal and albedo at detected landmarks to improve autonomous surface and shape characterization of small celestial bodies from in-situ imagery. In contrast to the current state-of-the-practice method for small body shape reconstruction, i.e., SPC, which relies on human-in-the-loop verification and high-fidelity a priori information to achieve accurate results, we forego the expensive maplet estimation step and instead leverage dense keypoint measurements and correspondences from an autonomous keypoint detection and matching method based on deep learning to provide the necessary photogrammetric constraints. Moreover, we develop a factor graph-based approach allowing for simultaneous optimization of the spacecraft's pose, landmark positions, Sun-relative direction, and surface normals and albedos via fusion of Sun sensor measurements and image keypoint measurements. The proposed framework is validated on real imagery of the Cornelia crater on Asteroid 4 Vesta, along with pose estimation and mapping comparison against an SPC reconstruction, where we demonstrate precise alignment to the SPC solution without relying on any a priori camera pose and topography information or humans-in-the-loop
Filtering Pixel Latent Variables for Unmixing Volumetric Images
Dec 08, 2023Measurements of different overlapping components require robust unmixing algorithms to convert the raw multi-dimensional measurements to useful unmixed images. Such algorithms perform reliable separation of the components when the raw signal is fully resolved and contains enough information to fit curves on the raw distributions. In experimental physics, measurements are often noisy, undersampled, or unresolved spatially or spectrally. We propose a novel method where bandpass filters are applied to the latent space of a multi-dimensional convolutional neural network to separate the overlapping signal components and extract each of their relative contributions. Simultaneously processing all dimensions with multi-dimensional convolution kernels empowers the network to combine the information from adjacent pixels and time- or spectral-bins, facilitating component separation in instances where individual pixels lack well-resolved information. We demonstrate the applicability of the method to real experimental physics problems using fluorescence lifetime microscopy and mode decomposition in optical fibers as test cases. The successful application of our approach to these two distinct experimental cases, characterized by different measured distributions, highlights the versatility of our approach in addressing a wide array of imaging tasks.
PneumoLLM: Harnessing the Power of Large Language Model for Pneumoconiosis Diagnosis
Dec 08, 2023The conventional pretraining-and-finetuning paradigm, while effective for common diseases with ample data, faces challenges in diagnosing data-scarce occupational diseases like pneumoconiosis. Recently, large language models (LLMs) have exhibits unprecedented ability when conducting multiple tasks in dialogue, bringing opportunities to diagnosis. A common strategy might involve using adapter layers for vision-language alignment and diagnosis in a dialogic manner. Yet, this approach often requires optimization of extensive learnable parameters in the text branch and the dialogue head, potentially diminishing the LLMs' efficacy, especially with limited training data. In our work, we innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters. Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, we introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, we propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens. Comprehensive experiments validate the superiority of our methods and the effectiveness of proposed modules. Our codes can be found at https://github.com/CodeMonsterPHD/PneumoLLM/tree/main.
Classification for everyone : Building geography agnostic models for fairer recognition
Dec 11, 2023In this paper, we analyze different methods to mitigate inherent geographical biases present in state of the art image classification models. We first quantitatively present this bias in two datasets - The Dollar Street Dataset and ImageNet, using images with location information. We then present different methods which can be employed to reduce this bias. Finally, we analyze the effectiveness of the different techniques on making these models more robust to geographical locations of the images.