 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Harnessing Retrieval-Augmented Generation (RAG) for Uncovering Knowledge Gaps
Dec 12, 2023
The paper presents a methodology for uncovering knowledge gaps on the internet using the Retrieval Augmented Generation (RAG) model. By simulating user search behaviour, the RAG system identifies and addresses gaps in information retrieval systems. The study demonstrates the effectiveness of the RAG system in generating relevant suggestions with a consistent accuracy of 93%. The methodology can be applied in various fields such as scientific discovery, educational enhancement, research development, market analysis, search engine optimisation, and content development. The results highlight the value of identifying and understanding knowledge gaps to guide future endeavours.
CMG-Net: Robust Normal Estimation for Point Clouds via Chamfer Normal Distance and Multi-scale Geometry
Dec 14, 2023This work presents an accurate and robust method for estimating normals from point clouds. In contrast to predecessor approaches that minimize the deviations between the annotated and the predicted normals directly, leading to direction inconsistency, we first propose a new metric termed Chamfer Normal Distance to address this issue. This not only mitigates the challenge but also facilitates network training and substantially enhances the network robustness against noise. Subsequently, we devise an innovative architecture that encompasses Multi-scale Local Feature Aggregation and Hierarchical Geometric Information Fusion. This design empowers the network to capture intricate geometric details more effectively and alleviate the ambiguity in scale selection. Extensive experiments demonstrate that our method achieves the state-of-the-art performance on both synthetic and real-world datasets, particularly in scenarios contaminated by noise. Our implementation is available at https://github.com/YingruiWoo/CMG-Net_Pytorch.
Design, construction and evaluation of emotional multimodal pathological speech database
Dec 14, 2023


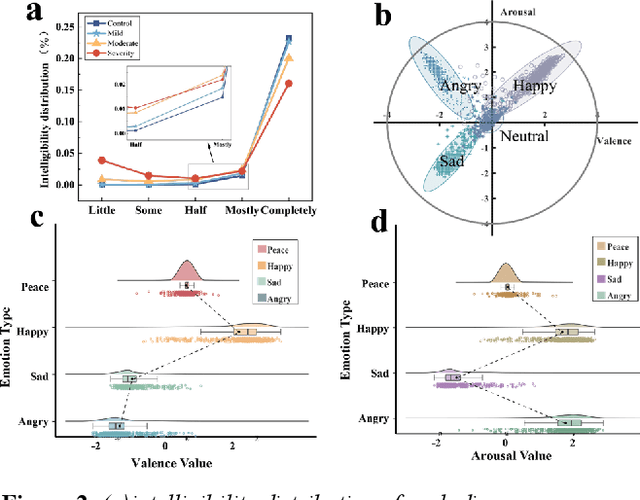
The lack of an available emotion pathology database is one of the key obstacles in studying the emotion expression status of patients with dysarthria. The first Chinese multimodal emotional pathological speech database containing multi-perspective information is constructed in this paper. It includes 29 controls and 39 patients with different degrees of motor dysarthria, expressing happy, sad, angry and neutral emotions. All emotional speech was labeled for intelligibility, types and discrete dimensional emotions by developed WeChat mini-program. The subjective analysis justifies from emotion discrimination accuracy, speech intelligibility, valence-arousal spatial distribution, and correlation between SCL-90 and disease severity. The automatic recognition tested on speech and glottal data, with average accuracy of 78% for controls and 60% for patients in audio, while 51% for controls and 38% for patients in glottal data, indicating an influence of the disease on emotional expression.
RedCore: Relative Advantage Aware Cross-modal Representation Learning for Missing Modalities with Imbalanced Missing Rates
Dec 16, 2023Multimodal learning is susceptible to modality missing, which poses a major obstacle for its practical applications and, thus, invigorates increasing research interest. In this paper, we investigate two challenging problems: 1) when modality missing exists in the training data, how to exploit the incomplete samples while guaranteeing that they are properly supervised? 2) when the missing rates of different modalities vary, causing or exacerbating the imbalance among modalities, how to address the imbalance and ensure all modalities are well-trained? To tackle these two challenges, we first introduce the variational information bottleneck (VIB) method for the cross-modal representation learning of missing modalities, which capitalizes on the available modalities and the labels as supervision. Then, accounting for the imbalanced missing rates, we define relative advantage to quantify the advantage of each modality over others. Accordingly, a bi-level optimization problem is formulated to adaptively regulate the supervision of all modalities during training. As a whole, the proposed approach features \textbf{Re}lative a\textbf{d}vantage aware \textbf{C}ross-m\textbf{o}dal \textbf{r}epresentation l\textbf{e}arning (abbreviated as \textbf{RedCore}) for missing modalities with imbalanced missing rates. Extensive empirical results demonstrate that RedCore outperforms competing models in that it exhibits superior robustness against either large or imbalanced missing rates.
Towards 6G Digital Twin Channel Using Radio Environment Knowledge Pool
Dec 16, 2023DTC is a technical system that reflects the raw channel fading states and variations in a digital form at the virtual space, to actively adapt to novel communication techniques of the wireless communication system (WCS) at the physical or link level. To realize DTC, in this article, the concept and construction method of the radio environment knowledge pool (REKP) is proposed, which possesses the advantages of being controllable, interpretable, renewable, and generalized. Concretely, it is a collection that represents the regular pattern representations and interconnections between propagation environment information (PEI) and channel data. It also has the ability to update knowledge based on environment changes, human cognition, and technological developments. Firstly, the current state of knowledge-based research in the communication field and that for acquiring channel knowledge and achieving DTC are summarized. Secondly, how to construct and update REKP to conduct key communication tasks is given. Then, the typical cases with extensive numerical results are presented to demonstrate the great potential of REKP in enabling DTC. Finally, how to utilize REKP to address key challenges in implementing DTC and 6G WCS are discussed, including interpretability and generalization of DTC, and enhancing performance and reducing costs in the 6G WCS.
Filtering Pixel Latent Variables for Unmixing Volumetric Images
Dec 08, 2023Measurements of different overlapping components require robust unmixing algorithms to convert the raw multi-dimensional measurements to useful unmixed images. Such algorithms perform reliable separation of the components when the raw signal is fully resolved and contains enough information to fit curves on the raw distributions. In experimental physics, measurements are often noisy, undersampled, or unresolved spatially or spectrally. We propose a novel method where bandpass filters are applied to the latent space of a multi-dimensional convolutional neural network to separate the overlapping signal components and extract each of their relative contributions. Simultaneously processing all dimensions with multi-dimensional convolution kernels empowers the network to combine the information from adjacent pixels and time- or spectral-bins, facilitating component separation in instances where individual pixels lack well-resolved information. We demonstrate the applicability of the method to real experimental physics problems using fluorescence lifetime microscopy and mode decomposition in optical fibers as test cases. The successful application of our approach to these two distinct experimental cases, characterized by different measured distributions, highlights the versatility of our approach in addressing a wide array of imaging tasks.
PneumoLLM: Harnessing the Power of Large Language Model for Pneumoconiosis Diagnosis
Dec 08, 2023The conventional pretraining-and-finetuning paradigm, while effective for common diseases with ample data, faces challenges in diagnosing data-scarce occupational diseases like pneumoconiosis. Recently, large language models (LLMs) have exhibits unprecedented ability when conducting multiple tasks in dialogue, bringing opportunities to diagnosis. A common strategy might involve using adapter layers for vision-language alignment and diagnosis in a dialogic manner. Yet, this approach often requires optimization of extensive learnable parameters in the text branch and the dialogue head, potentially diminishing the LLMs' efficacy, especially with limited training data. In our work, we innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters. Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, we introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, we propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens. Comprehensive experiments validate the superiority of our methods and the effectiveness of proposed modules. Our codes can be found at https://github.com/CodeMonsterPHD/PneumoLLM/tree/main.
Enhancing Spoofing Speech Detection Using Rhythm Information
Oct 18, 2023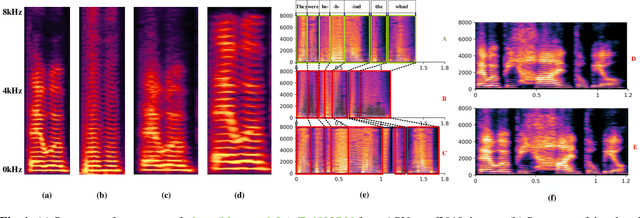
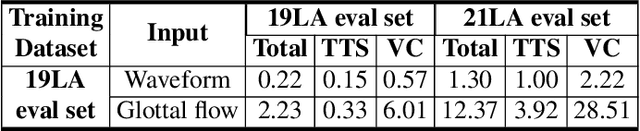
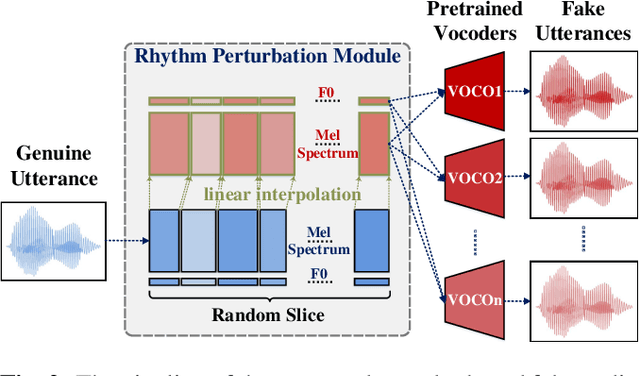
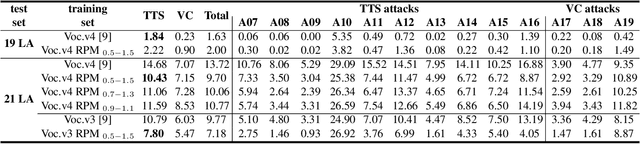
Spoofing speech detection is a hot and in-demand research field. However, current spoofing speech detection systems is lack of convincing evidence. In this paper, to increase the reliability of detection systems, the flaws of rhythm information inherent in the TTS-generated speech are analyzed. TTS models take text as input and utilize acoustic models to predict rhythm information, which introduces artifacts in the rhythm information. By filtering out vocal tract response, the remaining glottal flow with rhythm information retains detection ability for TTS-generated speech. Based on these analyses, a rhythm perturbation module is proposed to enhance the copy-synthesis data augmentation method. Fake utterances generated by the proposed method force the detecting model to pay attention to the artifacts in rhythm information and effectively improve the ability to detect TTS-generated speech of the anti-spoofing countermeasures.
CARAT: Contrastive Feature Reconstruction and Aggregation for Multi-modal Multi-label Emotion Recognition
Dec 15, 2023Multi-modal multi-label emotion recognition (MMER) aims to identify relevant emotions from multiple modalities. The challenge of MMER is how to effectively capture discriminative features for multiple labels from heterogeneous data. Recent studies are mainly devoted to exploring various fusion strategies to integrate multi-modal information into a unified representation for all labels. However, such a learning scheme not only overlooks the specificity of each modality but also fails to capture individual discriminative features for different labels. Moreover, dependencies of labels and modalities cannot be effectively modeled. To address these issues, this paper presents ContrAstive feature Reconstruction and AggregaTion (CARAT) for the MMER task. Specifically, we devise a reconstruction-based fusion mechanism to better model fine-grained modality-to-label dependencies by contrastively learning modal-separated and label-specific features. To further exploit the modality complementarity, we introduce a shuffle-based aggregation strategy to enrich co-occurrence collaboration among labels. Experiments on two benchmark datasets CMU-MOSEI and M3ED demonstrate the effectiveness of CARAT over state-of-the-art methods. Code is available at https://github.com/chengzju/CARAT.
Do Text Simplification Systems Preserve Meaning? A Human Evaluation via Reading Comprehension
Dec 15, 2023Automatic text simplification (TS) aims to automate the process of rewriting text to make it easier for people to read. A pre-requisite for TS to be useful is that it should convey information that is consistent with the meaning of the original text. However, current TS evaluation protocols assess system outputs for simplicity and meaning preservation without regard for the document context in which output sentences occur and for how people understand them. In this work, we introduce a human evaluation framework to assess whether simplified texts preserve meaning using reading comprehension questions. With this framework, we conduct a thorough human evaluation of texts by humans and by nine automatic systems. Supervised systems that leverage pre-training knowledge achieve the highest scores on the reading comprehension (RC) tasks amongst the automatic controllable TS systems. However, even the best-performing supervised system struggles with at least 14% of the questions, marking them as "unanswerable'' based on simplified content. We further investigate how existing TS evaluation metrics and automatic question-answering systems approximate the human judgments we obtained.