 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bi-directional Adapter for Multi-modal Tracking
Dec 17, 2023
Due to the rapid development of computer vision, single-modal (RGB) object tracking has made significant progress in recent years. Considering the limitation of single imaging sensor, multi-modal images (RGB, Infrared, etc.) are introduced to compensate for this deficiency for all-weather object tracking in complex environments. However, as acquiring sufficient multi-modal tracking data is hard while the dominant modality changes with the open environment, most existing techniques fail to extract multi-modal complementary information dynamically, yielding unsatisfactory tracking performance. To handle this problem, we propose a novel multi-modal visual prompt tracking model based on a universal bi-directional adapter, cross-prompting multiple modalities mutually. Our model consists of a universal bi-directional adapter and multiple modality-specific transformer encoder branches with sharing parameters. The encoders extract features of each modality separately by using a frozen pre-trained foundation model. We develop a simple but effective light feature adapter to transfer modality-specific information from one modality to another, performing visual feature prompt fusion in an adaptive manner. With adding fewer (0.32M) trainable parameters, our model achieves superior tracking performance in comparison with both the full fine-tuning methods and the prompt learning-based methods. Our code is available: https://github.com/SparkTempest/BAT.
Research Team Identification Based on Representation Learning of Academic Heterogeneous Information Network
Nov 02, 2023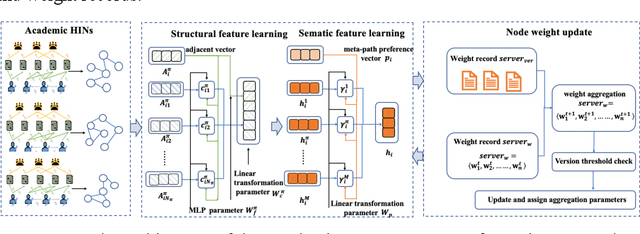
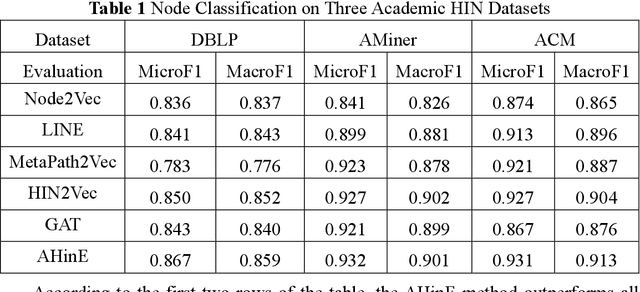

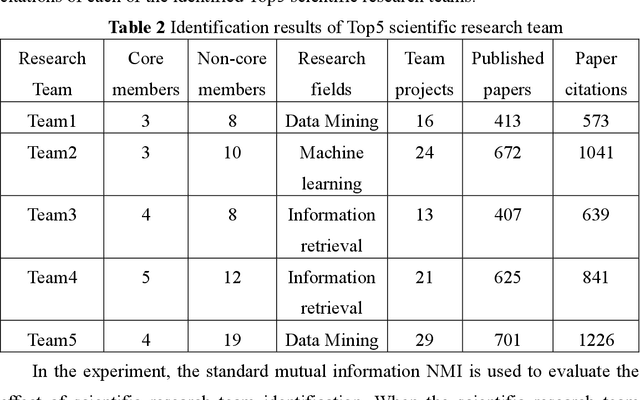
Academic networks in the real world can usually be described by heterogeneous information networks composed of multi-type nodes and relationships. Some existing research on representation learning for homogeneous information networks lacks the ability to explore heterogeneous information networks in heterogeneous information networks. It cannot be applied to heterogeneous information networks. Aiming at the practical needs of effectively identifying and discovering scientific research teams from the academic heterogeneous information network composed of massive and complex scientific and technological big data, this paper proposes a scientific research team identification method based on representation learning of academic heterogeneous information networks. The attention mechanism at node level and meta-path level learns low-dimensional, dense and real-valued vector representations on the basis of retaining the rich topological information of nodes in the network and the semantic information based on meta-paths, and realizes effective identification and discovery of scientific research teams and important team members in academic heterogeneous information networks based on maximizing node influence. Experimental results show that our proposed method outperforms the comparative methods.
GIELLM: Japanese General Information Extraction Large Language Model Utilizing Mutual Reinforcement Effect
Nov 12, 2023Information Extraction (IE) stands as a cornerstone in natural language processing, traditionally segmented into distinct sub-tasks. The advent of Large Language Models (LLMs) heralds a paradigm shift, suggesting the feasibility of a singular model addressing multiple IE subtasks. In this vein, we introduce the General Information Extraction Large Language Model (GIELLM), which integrates text Classification, Sentiment Analysis, Named Entity Recognition, Relation Extraction, and Event Extraction using a uniform input-output schema. This innovation marks the first instance of a model simultaneously handling such a diverse array of IE subtasks. Notably, the GIELLM leverages the Mutual Reinforcement Effect (MRE), enhancing performance in integrated tasks compared to their isolated counterparts. Our experiments demonstrate State-of-the-Art (SOTA) results in five out of six Japanese mixed datasets, significantly surpassing GPT-3.5-Turbo. Further, an independent evaluation using the novel Text Classification Relation and Event Extraction(TCREE) dataset corroborates the synergistic advantages of MRE in text and word classification. This breakthrough paves the way for most IE subtasks to be subsumed under a singular LLM framework. Specialized fine-tune task-specific models are no longer needed.
Brain Computer Interface Technology for Future Battlefield
Dec 13, 2023With the development of artificial intelligence and unmanned equipment, human-machine hybrid formations will be the main focus in future combat formations. With the development of big data and various situational awareness technologies, while enhancing the breadth and depth of information, decision-making has also become more complex. The operation mode of existing unmanned equipment often requires complex manual input, which is not conducive to the battlefield environment. How to reduce the cognitive load of information exchange between soldiers and various unmanned equipment is an important issue in future intelligent warfare. This paper proposes a brain computer interface communication system for soldier combat, which takes into account the characteristics of soldier combat scenarios in design. The stimulation paradigm is combined with helmets, portable computers, and firearms, and brain computer interface technology is used to achieve fast, barrier free, and hands-free communication between humans and machines. Intelligent algorithms are combined to assist decision-making in fully perceiving and fusing situational information on the battlefield, and a large amount of data is processed quickly, understanding and integrating a large amount of data from human and machine networks, achieving real-time perception of battlefield information, making intelligent decisions, and achieving the effect of direct control of drone swarms and other equipment by the human brain to assist in soldier scenarios.
Optimizing Ego Vehicle Trajectory Prediction: The Graph Enhancement Approach
Dec 20, 2023Predicting the trajectory of an ego vehicle is a critical component of autonomous driving systems. Current state-of-the-art methods typically rely on Deep Neural Networks (DNNs) and sequential models to process front-view images for future trajectory prediction. However, these approaches often struggle with perspective issues affecting object features in the scene. To address this, we advocate for the use of Bird's Eye View (BEV) perspectives, which offer unique advantages in capturing spatial relationships and object homogeneity. In our work, we leverage Graph Neural Networks (GNNs) and positional encoding to represent objects in a BEV, achieving competitive performance compared to traditional DNN-based methods. While the BEV-based approach loses some detailed information inherent to front-view images, we balance this by enriching the BEV data by representing it as a graph where relationships between the objects in a scene are captured effectively.
Segmenting Messy Text: Detecting Boundaries in Text Derived from Historical Newspaper Images
Dec 20, 2023Text segmentation, the task of dividing a document into sections, is often a prerequisite for performing additional natural language processing tasks. Existing text segmentation methods have typically been developed and tested using clean, narrative-style text with segments containing distinct topics. Here we consider a challenging text segmentation task: dividing newspaper marriage announcement lists into units of one announcement each. In many cases the information is not structured into sentences, and adjacent segments are not topically distinct from each other. In addition, the text of the announcements, which is derived from images of historical newspapers via optical character recognition, contains many typographical errors. As a result, these announcements are not amenable to segmentation with existing techniques. We present a novel deep learning-based model for segmenting such text and show that it significantly outperforms an existing state-of-the-art method on our task.
* 8 pages, 4 figures
Online Auditing of Information Flow
Oct 23, 2023Modern social media platforms play an important role in facilitating rapid dissemination of information through their massive user networks. Fake news, misinformation, and unverifiable facts on social media platforms propagate disharmony and affect society. In this paper, we consider the problem of online auditing of information flow/propagation with the goal of classifying news items as fake or genuine. Specifically, driven by experiential studies on real-world social media platforms, we propose a probabilistic Markovian information spread model over networks modeled by graphs. We then formulate our inference task as a certain sequential detection problem with the goal of minimizing the combination of the error probability and the time it takes to achieve correct decision. For this model, we find the optimal detection algorithm minimizing the aforementioned risk and prove several statistical guarantees. We then test our algorithm over real-world datasets. To that end, we first construct an offline algorithm for learning the probabilistic information spreading model, and then apply our optimal detection algorithm. Experimental study show that our algorithm outperforms state-of-the-art misinformation detection algorithms in terms of accuracy and detection time.
SELM: Speech Enhancement Using Discrete Tokens and Language Models
Dec 15, 2023Language models (LMs) have shown superior performances in various speech generation tasks recently, demonstrating their powerful ability for semantic context modeling. Given the intrinsic similarity between speech generation and speech enhancement, harnessing semantic information holds potential advantages for speech enhancement tasks. In light of this, we propose SELM, a novel paradigm for speech enhancement, which integrates discrete tokens and leverages language models. SELM comprises three stages: encoding, modeling, and decoding. We transform continuous waveform signals into discrete tokens using pre-trained self-supervised learning (SSL) models and a k-means tokenizer. Language models then capture comprehensive contextual information within these tokens. Finally, a detokenizer and HiFi-GAN restore them into enhanced speech. Experimental results demonstrate that SELM achieves comparable performance in objective metrics alongside superior results in subjective perception. Our demos are available https://honee-w.github.io/SELM/.
Extending Context Window of Large Language Models via Semantic Compression
Dec 15, 2023Transformer-based Large Language Models (LLMs) often impose limitations on the length of the text input to ensure the generation of fluent and relevant responses. This constraint restricts their applicability in scenarios involving long texts. We propose a novel semantic compression method that enables generalization to texts that are 6-8 times longer, without incurring significant computational costs or requiring fine-tuning. Our proposed framework draws inspiration from source coding in information theory and employs a pre-trained model to reduce the semantic redundancy of long inputs before passing them to the LLMs for downstream tasks. Experimental results demonstrate that our method effectively extends the context window of LLMs across a range of tasks including question answering, summarization, few-shot learning, and information retrieval. Furthermore, the proposed semantic compression method exhibits consistent fluency in text generation while reducing the associated computational overhead.
Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
Dec 22, 2023A key method for creating Artificial Intelligence (AI) agents is Reinforcement Learning (RL). However, constructing a standalone RL policy that maps perception to action directly encounters severe problems, chief among them being its lack of generality across multiple tasks and the need for a large amount of training data. The leading cause is that it cannot effectively integrate prior information into the perception-action cycle when devising the policy. Large language models (LLMs) emerged as a fundamental way to incorporate cross-domain knowledge into AI agents but lack crucial learning and adaptation toward specific decision problems. This paper presents a general framework model for integrating and learning structured reasoning into AI agents' policies. Our methodology is motivated by the modularity found in the human brain. The framework utilises the construction of intrinsic and extrinsic functions to add previous understandings of reasoning structures. It also provides the adaptive ability to learn models inside every module or function, consistent with the modular structure of cognitive processes. We describe the framework in-depth and compare it with other AI pipelines and existing frameworks. The paper explores practical applications, covering experiments that show the effectiveness of our method. Our results indicate that AI agents perform and adapt far better when organised reasoning and prior knowledge are embedded. This opens the door to more resilient and general AI agent systems.