 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ASF-YOLO: A Novel YOLO Model with Attentional Scale Sequence Fusion for Cell Instance Segmentation
Dec 11, 2023

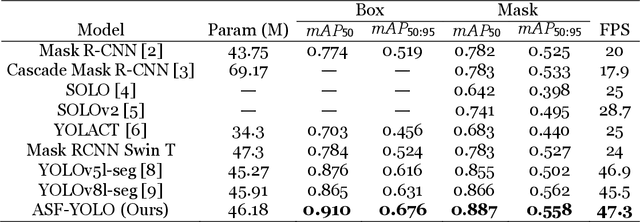
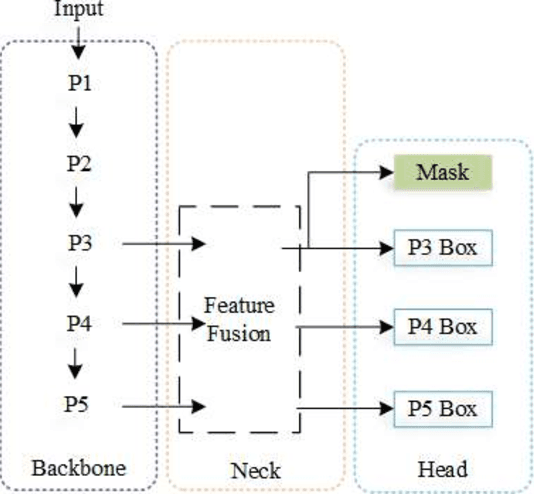
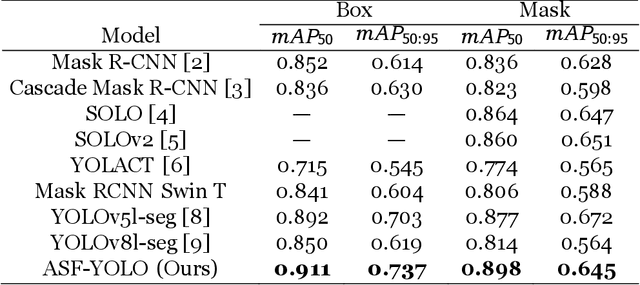
We propose a novel Attentional Scale Sequence Fusion based You Only Look Once (YOLO) framework (ASF-YOLO) which combines spatial and scale features for accurate and fast cell instance segmentation. Built on the YOLO segmentation framework, we employ the Scale Sequence Feature Fusion (SSFF) module to enhance the multi-scale information extraction capability of the network, and the Triple Feature Encoder (TPE) module to fuse feature maps of different scales to increase detailed information. We further introduce a Channel and Position Attention Mechanism (CPAM) to integrate both the SSFF and TPE modules, which focus on informative channels and spatial position-related small objects for improved detection and segmentation performance. Experimental validations on two cell datasets show remarkable segmentation accuracy and speed of the proposed ASF-YOLO model. It achieves a box mAP of 0.91, mask mAP of 0.887, and an inference speed of 47.3 FPS on the 2018 Data Science Bowl dataset, outperforming the state-of-the-art methods. The source code is available at https://github.com/mkang315/ASF-YOLO.
An AI-based solution for the cold start and data sparsity problems in the recommendation systems
Dec 04, 2023In recent years, the amount of data available on the internet and the number of users who utilize the Internet have increased at an unparalleled pace. The exponential development in the quantity of digital information accessible and the number of Internet users has created the possibility for information overload, impeding fast access to items of interest on the Internet. Information retrieval systems like as Google, DevilFinder, and Altavista have partly overcome this challenge, but prioritizing and customization of information (where a system maps accessible material to a user's interests and preferences) were lacking. This has resulted in a higher-than-ever need for recommender systems. Recommender systems are information filtering systems that address the issue of information overload by filtering important information fragments from a huge volume of dynamically produced data based on the user's interests, favorite things, preferences and ratings on the desired item. Recommender systems can figure out if a person would like an item or not based on their profile.
GEAR-Up: Generative AI and External Knowledge-based Retrieval Upgrading Scholarly Article Searches for Systematic Reviews
Dec 15, 2023Systematic reviews (SRs) - the librarian-assisted literature survey of scholarly articles takes time and requires significant human resources. Given the ever-increasing volume of published studies, applying existing computing and informatics technology can decrease this time and resource burden. Due to the revolutionary advances in (1) Generative AI such as ChatGPT, and (2) External knowledge-augmented information extraction efforts such as Retrieval-Augmented Generation, In this work, we explore the use of techniques from (1) and (2) for SR. We demonstrate a system that takes user queries, performs query expansion to obtain enriched context (includes additional terms and definitions by querying language models and knowledge graphs), and uses this context to search for articles on scholarly databases to retrieve articles. We perform qualitative evaluations of our system through comparison against sentinel (ground truth) articles provided by an in-house librarian. The demo can be found at: https://youtu.be/zMdP56GJ9mU.
Topic-VQ-VAE: Leveraging Latent Codebooks for Flexible Topic-Guided Document Generation
Dec 15, 2023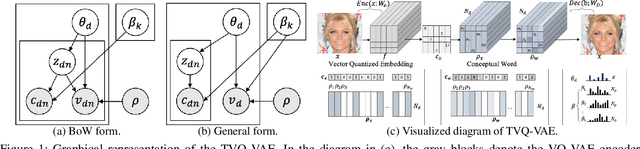
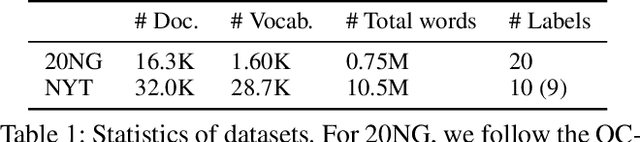


This paper introduces a novel approach for topic modeling utilizing latent codebooks from Vector-Quantized Variational Auto-Encoder~(VQ-VAE), discretely encapsulating the rich information of the pre-trained embeddings such as the pre-trained language model. From the novel interpretation of the latent codebooks and embeddings as conceptual bag-of-words, we propose a new generative topic model called Topic-VQ-VAE~(TVQ-VAE) which inversely generates the original documents related to the respective latent codebook. The TVQ-VAE can visualize the topics with various generative distributions including the traditional BoW distribution and the autoregressive image generation. Our experimental results on document analysis and image generation demonstrate that TVQ-VAE effectively captures the topic context which reveals the underlying structures of the dataset and supports flexible forms of document generation. Official implementation of the proposed TVQ-VAE is available at https://github.com/clovaai/TVQ-VAE.
ReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
Dec 15, 2023Answering complex natural language questions often necessitates multi-step reasoning and integrating external information. Several systems have combined knowledge retrieval with a large language model (LLM) to answer such questions. These systems, however, suffer from various failure cases, and we cannot directly train them end-to-end to fix such failures, as interaction with external knowledge is non-differentiable. To address these deficiencies, we define a ReAct-style LLM agent with the ability to reason and act upon external knowledge. We further refine the agent through a ReST-like method that iteratively trains on previous trajectories, employing growing-batch reinforcement learning with AI feedback for continuous self-improvement and self-distillation. Starting from a prompted large model and after just two iterations of the algorithm, we can produce a fine-tuned small model that achieves comparable performance on challenging compositional question-answering benchmarks with two orders of magnitude fewer parameters.
Self-Supervised Learning for Anomalous Sound Detection
Dec 15, 2023State-of-the-art anomalous sound detection (ASD) systems are often trained by using an auxiliary classification task to learn an embedding space. Doing so enables the system to learn embeddings that are robust to noise and are ignoring non-target sound events but requires manually annotated meta information to be used as class labels. However, the less difficult the classification task becomes, the less informative are the embeddings and the worse is the resulting ASD performance. A solution to this problem is to utilize self-supervised learning (SSL). In this work, feature exchange (FeatEx), a simple yet effective SSL approach for ASD, is proposed. In addition, FeatEx is compared to and combined with existing SSL approaches. As the main result, a new state-of-the-art performance for the DCASE2023 ASD dataset is obtained that outperforms all other published results on this dataset by a large margin.
Positional Information Matters for Invariant In-Context Learning: A Case Study of Simple Function Classes
Nov 30, 2023In-context learning (ICL) refers to the ability of a model to condition on a few in-context demonstrations (input-output examples of the underlying task) to generate the answer for a new query input, without updating parameters. Despite the impressive ICL ability of LLMs, it has also been found that ICL in LLMs is sensitive to input demonstrations and limited to short context lengths. To understand the limitations and principles for successful ICL, we conduct an investigation with ICL linear regression of transformers. We characterize several Out-of-Distribution (OOD) cases for ICL inspired by realistic LLM ICL failures and compare transformers with DeepSet, a simple yet powerful architecture for ICL. Surprisingly, DeepSet outperforms transformers across a variety of distribution shifts, implying that preserving permutation invariance symmetry to input demonstrations is crucial for OOD ICL. The phenomenon specifies a fundamental requirement by ICL, which we termed as ICL invariance. Nevertheless, the positional encodings in LLMs will break ICL invariance. To this end, we further evaluate transformers with identical positional encodings and find preserving ICL invariance in transformers achieves state-of-the-art performance across various ICL distribution shifts
A Framework for Exploring Federated Community Detection
Dec 14, 2023Federated Learning is machine learning in the context of a network of clients whilst maintaining data residency and/or privacy constraints. Community detection is the unsupervised discovery of clusters of nodes within graph-structured data. The intersection of these two fields uncovers much opportunity, but also challenge. For example, it adds complexity due to missing connectivity information between privately held graphs. In this work, we explore the potential of federated community detection by conducting initial experiments across a range of existing datasets that showcase the gap in performance introduced by the distributed data. We demonstrate that isolated models would benefit from collaboration establishing a framework for investigating challenges within this domain. The intricacies of these research frontiers are discussed alongside proposed solutions to these issues.
CEIR: Concept-based Explainable Image Representation Learning
Dec 17, 2023In modern machine learning, the trend of harnessing self-supervised learning to derive high-quality representations without label dependency has garnered significant attention. However, the absence of label information, coupled with the inherently high-dimensional nature, improves the difficulty for the interpretation of learned representations. Consequently, indirect evaluations become the popular metric for evaluating the quality of these features, leading to a biased validation of the learned representation rationale. To address these challenges, we introduce a novel approach termed Concept-based Explainable Image Representation (CEIR). Initially, using the Concept-based Model (CBM) incorporated with pretrained CLIP and concepts generated by GPT-4, we project input images into a concept vector space. Subsequently, a Variational Autoencoder (VAE) learns the latent representation from these projected concepts, which serves as the final image representation. Due to the capability of the representation to encapsulate high-level, semantically relevant concepts, the model allows for attributions to a human-comprehensible concept space. This not only enhances interpretability but also preserves the robustness essential for downstream tasks. For instance, our method exhibits state-of-the-art unsupervised clustering performance on benchmarks such as CIFAR10, CIFAR100, and STL10. Furthermore, capitalizing on the universality of human conceptual understanding, CEIR can seamlessly extract the related concept from open-world images without fine-tuning. This offers a fresh approach to automatic label generation and label manipulation.
p-Laplacian Adaptation for Generative Pre-trained Vision-Language Models
Dec 17, 2023Vision-Language models (VLMs) pre-trained on large corpora have demonstrated notable success across a range of downstream tasks. In light of the rapidly increasing size of pre-trained VLMs, parameter-efficient transfer learning (PETL) has garnered attention as a viable alternative to full fine-tuning. One such approach is the adapter, which introduces a few trainable parameters into the pre-trained models while preserving the original parameters during adaptation. In this paper, we present a novel modeling framework that recasts adapter tuning after attention as a graph message passing process on attention graphs, where the projected query and value features and attention matrix constitute the node features and the graph adjacency matrix, respectively. Within this framework, tuning adapters in VLMs necessitates handling heterophilic graphs, owing to the disparity between the projected query and value space. To address this challenge, we propose a new adapter architecture, $p$-adapter, which employs $p$-Laplacian message passing in Graph Neural Networks (GNNs). Specifically, the attention weights are re-normalized based on the features, and the features are then aggregated using the calibrated attention matrix, enabling the dynamic exploitation of information with varying frequencies in the heterophilic attention graphs. We conduct extensive experiments on different pre-trained VLMs and multi-modal tasks, including visual question answering, visual entailment, and image captioning. The experimental results validate our method's significant superiority over other PETL methods.