 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Information Theory-Based Discovery of Equivariances
Oct 25, 2023
The presence of symmetries imposes a stringent set of constraints on a system. This constrained structure allows intelligent agents interacting with such a system to drastically improve the efficiency of learning and generalization, through the internalisation of the system's symmetries into their information-processing. In parallel, principled models of complexity-constrained learning and behaviour make increasing use of information-theoretic methods. Here, we wish to marry these two perspectives and understand whether and in which form the information-theoretic lens can "see" the effect of symmetries of a system. For this purpose, we propose a novel variant of the Information Bottleneck principle, which has served as a productive basis for many principled studies of learning and information-constrained adaptive behaviour. We show (in the discrete case) that our approach formalises a certain duality between symmetry and information parsimony: namely, channel equivariances can be characterised by the optimal mutual information-preserving joint compression of the channel's input and output. This information-theoretic treatment furthermore suggests a principled notion of "soft" equivariance, whose "coarseness" is measured by the amount of input-output mutual information preserved by the corresponding optimal compression. This new notion offers a bridge between the field of bounded rationality and the study of symmetries in neural representations. The framework may also allow (exact and soft) equivariances to be automatically discovered.
A quantitative fusion strategy of stock picking and timing based on Particle Swarm Optimized-Back Propagation Neural Network and Multivariate Gaussian-Hidden Markov Model
Dec 22, 2023In recent years, machine learning (ML) has brought effective approaches and novel techniques to economic decision, investment forecasting, and risk management, etc., coping the variable and intricate nature of economic and financial environments. For the investment in stock market, this research introduces a pioneering quantitative fusion model combining stock timing and picking strategy by leveraging the Multivariate Gaussian-Hidden Markov Model (MGHMM) and Back Propagation Neural Network optimized by Particle Swarm (PSO-BPNN). After the information coefficients (IC) between fifty-two factors that have been winsorized, neutralized and standardized and the return of CSI 300 index are calculated, a given amount of factors that rank ahead are choose to be candidate factors heading for the input of PSO-BPNN after dimension reduction by Principal Component Analysis (PCA), followed by a certain amount of constituent stocks outputted. Subsequently, we conduct the prediction and trading on the basis of the screening stocks and stock market state outputted by MGHMM trained using inputting CSI 300 index data after Box-Cox transformation, bespeaking eximious performance during the period of past four years. Ultimately, some conventional forecast and trading methods are compared with our strategy in Chinese stock market. Our fusion strategy incorporating stock picking and timing presented in this article provide a innovative technique for financial analysis.
A Multi-Stage Adaptive Feature Fusion Neural Network for Multimodal Gait Recognition
Dec 22, 2023Gait recognition is a biometric technology that has received extensive attention. Most existing gait recognition algorithms are unimodal, and a few multimodal gait recognition algorithms perform multimodal fusion only once. None of these algorithms may fully exploit the complementary advantages of the multiple modalities. In this paper, by considering the temporal and spatial characteristics of gait data, we propose a multi-stage feature fusion strategy (MSFFS), which performs multimodal fusions at different stages in the feature extraction process. Also, we propose an adaptive feature fusion module (AFFM) that considers the semantic association between silhouettes and skeletons. The fusion process fuses different silhouette areas with their more related skeleton joints. Since visual appearance changes and time passage co-occur in a gait period, we propose a multiscale spatial-temporal feature extractor (MSSTFE) to learn the spatial-temporal linkage features thoroughly. Specifically, MSSTFE extracts and aggregates spatial-temporal linkages information at different spatial scales. Combining the strategy and modules mentioned above, we propose a multi-stage adaptive feature fusion (MSAFF) neural network, which shows state-of-the-art performance in many experiments on three datasets. Besides, MSAFF is equipped with feature dimensional pooling (FD Pooling), which can significantly reduce the dimension of the gait representations without hindering the accuracy. https://github.com/ShinanZou/MSAFF
* This paper has been accepted by IJCB2023
Attacking Byzantine Robust Aggregation in High Dimensions
Dec 22, 2023Training modern neural networks or models typically requires averaging over a sample of high-dimensional vectors. Poisoning attacks can skew or bias the average vectors used to train the model, forcing the model to learn specific patterns or avoid learning anything useful. Byzantine robust aggregation is a principled algorithmic defense against such biasing. Robust aggregators can bound the maximum bias in computing centrality statistics, such as mean, even when some fraction of inputs are arbitrarily corrupted. Designing such aggregators is challenging when dealing with high dimensions. However, the first polynomial-time algorithms with strong theoretical bounds on the bias have recently been proposed. Their bounds are independent of the number of dimensions, promising a conceptual limit on the power of poisoning attacks in their ongoing arms race against defenses. In this paper, we show a new attack called HIDRA on practical realization of strong defenses which subverts their claim of dimension-independent bias. HIDRA highlights a novel computational bottleneck that has not been a concern of prior information-theoretic analysis. Our experimental evaluation shows that our attacks almost completely destroy the model performance, whereas existing attacks with the same goal fail to have much effect. Our findings leave the arms race between poisoning attacks and provable defenses wide open.
Understanding driver-pedestrian interactions to predict driver yielding: naturalistic open-source dataset collected in Minnesota
Dec 22, 2023Many factors influence the yielding result of a driver-pedestrian interaction, including traffic volume, vehicle speed, roadway characteristics, etc. While individual aspects of these interactions have been explored, comprehensive, naturalistic studies, particularly those considering the built environment's influence on driver-yielding behavior, are lacking. To address this gap, our study introduces an extensive open-source dataset, compiled from video data at 18 unsignalized intersections across Minnesota. Documenting more than 3000 interactions, this dataset provides a detailed view of driver-pedestrian interactions and over 50 distinct contextual variables. The data, which covers individual driver-pedestrian interactions and contextual factors, is made publicly available at https://github.com/tianyi17/pedestrian_yielding_data_MN. Using logistic regression, we developed a classification model that predicts driver yielding based on the identified variables. Our analysis indicates that vehicle speed, the presence of parking lots, proximity to parks or schools, and the width of major road crossings significantly influence driver yielding at unsignalized intersections. This study contributes to one of the most comprehensive driver-pedestrian datasets in the US, offering valuable insights for traffic safety improvements. By making this information available, our study will support communities across Minnesota and the United States in their ongoing efforts to improve road safety for pedestrians.
GroundVLP: Harnessing Zero-shot Visual Grounding from Vision-Language Pre-training and Open-Vocabulary Object Detection
Dec 22, 2023Visual grounding, a crucial vision-language task involving the understanding of the visual context based on the query expression, necessitates the model to capture the interactions between objects, as well as various spatial and attribute information. However, the annotation data of visual grounding task is limited due to its time-consuming and labor-intensive annotation process, resulting in the trained models being constrained from generalizing its capability to a broader domain. To address this challenge, we propose GroundVLP, a simple yet effective zero-shot method that harnesses visual grounding ability from the existing models trained from image-text pairs and pure object detection data, both of which are more conveniently obtainable and offer a broader domain compared to visual grounding annotation data. GroundVLP proposes a fusion mechanism that combines the heatmap from GradCAM and the object proposals of open-vocabulary detectors. We demonstrate that the proposed method significantly outperforms other zero-shot methods on RefCOCO/+/g datasets, surpassing prior zero-shot state-of-the-art by approximately 28\% on the test split of RefCOCO and RefCOCO+. Furthermore, GroundVLP performs comparably to or even better than some non-VLP-based supervised models on the Flickr30k entities dataset. Our code is available at https://github.com/om-ai-lab/GroundVLP.
Retrieval-Augmented Code Generation for Universal Information Extraction
Nov 06, 2023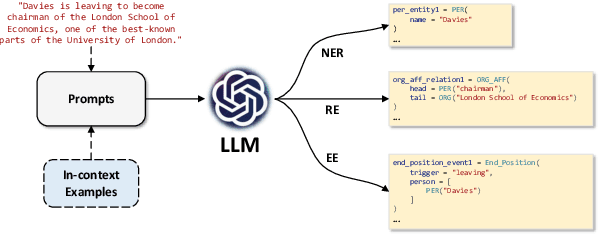
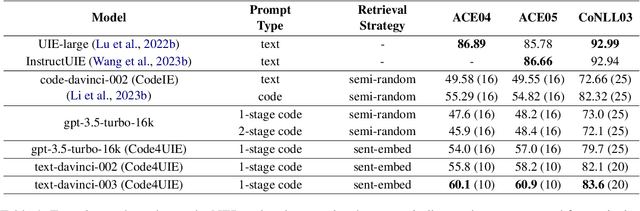

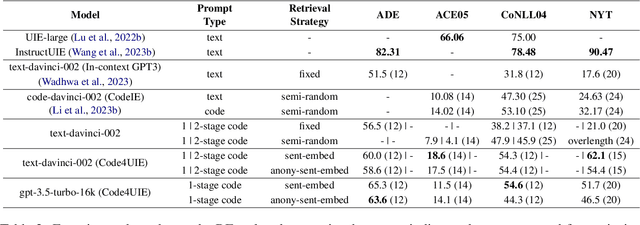
Information Extraction (IE) aims to extract structural knowledge (e.g., entities, relations, events) from natural language texts, which brings challenges to existing methods due to task-specific schemas and complex text expressions. Code, as a typical kind of formalized language, is capable of describing structural knowledge under various schemas in a universal way. On the other hand, Large Language Models (LLMs) trained on both codes and texts have demonstrated powerful capabilities of transforming texts into codes, which provides a feasible solution to IE tasks. Therefore, in this paper, we propose a universal retrieval-augmented code generation framework based on LLMs, called Code4UIE, for IE tasks. Specifically, Code4UIE adopts Python classes to define task-specific schemas of various structural knowledge in a universal way. By so doing, extracting knowledge under these schemas can be transformed into generating codes that instantiate the predefined Python classes with the information in texts. To generate these codes more precisely, Code4UIE adopts the in-context learning mechanism to instruct LLMs with examples. In order to obtain appropriate examples for different tasks, Code4UIE explores several example retrieval strategies, which can retrieve examples semantically similar to the given texts. Extensive experiments on five representative IE tasks across nine datasets demonstrate the effectiveness of the Code4UIE framework.
Forced Exploration in Bandit Problems
Dec 13, 2023The multi-armed bandit(MAB) is a classical sequential decision problem. Most work requires assumptions about the reward distribution (e.g., bounded), while practitioners may have difficulty obtaining information about these distributions to design models for their problems, especially in non-stationary MAB problems. This paper aims to design a multi-armed bandit algorithm that can be implemented without using information about the reward distribution while still achieving substantial regret upper bounds. To this end, we propose a novel algorithm alternating between greedy rule and forced exploration. Our method can be applied to Gaussian, Bernoulli and other subgaussian distributions, and its implementation does not require additional information. We employ a unified analysis method for different forced exploration strategies and provide problem-dependent regret upper bounds for stationary and piecewise-stationary settings. Furthermore, we compare our algorithm with popular bandit algorithms on different reward distributions.
Part Representation Learning with Teacher-Student Decoder for Occluded Person Re-identification
Dec 15, 2023Occluded person re-identification (ReID) is a very challenging task due to the occlusion disturbance and incomplete target information. Leveraging external cues such as human pose or parsing to locate and align part features has been proven to be very effective in occluded person ReID. Meanwhile, recent Transformer structures have a strong ability of long-range modeling. Considering the above facts, we propose a Teacher-Student Decoder (TSD) framework for occluded person ReID, which utilizes the Transformer decoder with the help of human parsing. More specifically, our proposed TSD consists of a Parsing-aware Teacher Decoder (PTD) and a Standard Student Decoder (SSD). PTD employs human parsing cues to restrict Transformer's attention and imparts this information to SSD through feature distillation. Thereby, SSD can learn from PTD to aggregate information of body parts automatically. Moreover, a mask generator is designed to provide discriminative regions for better ReID. In addition, existing occluded person ReID benchmarks utilize occluded samples as queries, which will amplify the role of alleviating occlusion interference and underestimate the impact of the feature absence issue. Contrastively, we propose a new benchmark with non-occluded queries, serving as a complement to the existing benchmark. Extensive experiments demonstrate that our proposed method is superior and the new benchmark is essential. The source codes are available at https://github.com/hh23333/TSD.
A Novel Energy based Model Mechanism for Multi-modal Aspect-Based Sentiment Analysis
Dec 15, 2023
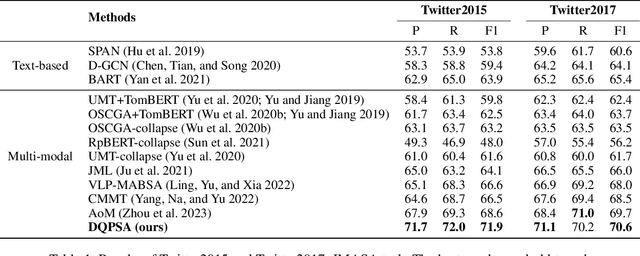
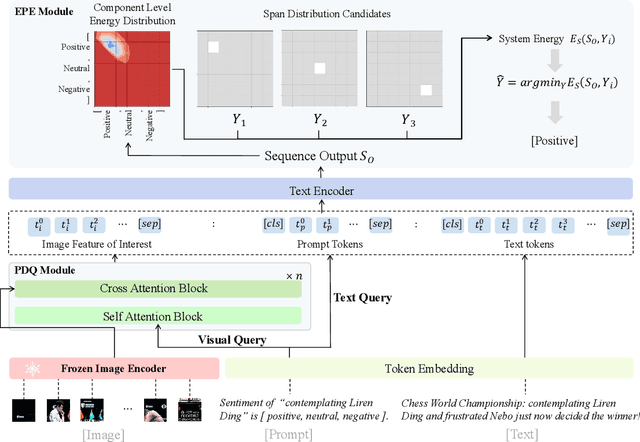
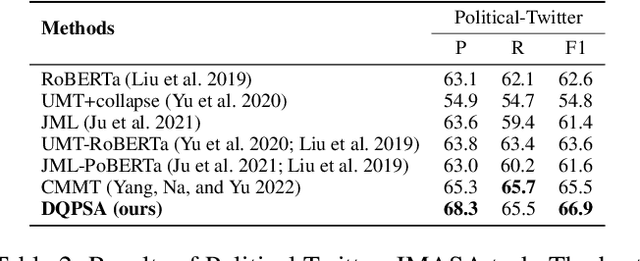
Multi-modal aspect-based sentiment analysis (MABSA) has recently attracted increasing attention. The span-based extraction methods, such as FSUIE, demonstrate strong performance in sentiment analysis due to their joint modeling of input sequences and target labels. However, previous methods still have certain limitations: (i) They ignore the difference in the focus of visual information between different analysis targets (aspect or sentiment). (ii) Combining features from uni-modal encoders directly may not be sufficient to eliminate the modal gap and can cause difficulties in capturing the image-text pairwise relevance. (iii) Existing span-based methods for MABSA ignore the pairwise relevance of target span boundaries. To tackle these limitations, we propose a novel framework called DQPSA for multi-modal sentiment analysis. Specifically, our model contains a Prompt as Dual Query (PDQ) module that uses the prompt as both a visual query and a language query to extract prompt-aware visual information and strengthen the pairwise relevance between visual information and the analysis target. Additionally, we introduce an Energy-based Pairwise Expert (EPE) module that models the boundaries pairing of the analysis target from the perspective of an Energy-based Model. This expert predicts aspect or sentiment span based on pairwise stability. Experiments on three widely used benchmarks demonstrate that DQPSA outperforms previous approaches and achieves a new state-of-the-art performance.