 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Probabilistic Prediction of Longitudinal Trajectory Considering Driving Heterogeneity with Interpretability
Dec 19, 2023
Automated vehicles are envisioned to navigate safely in complex mixed-traffic scenarios alongside human-driven vehicles. To promise a high degree of safety, accurately predicting the maneuvers of surrounding vehicles and their future positions is a critical task and attracts much attention. However, most existing studies focused on reasoning about positional information based on objective historical trajectories without fully considering the heterogeneity of driving behaviors. Therefore, this study proposes a trajectory prediction framework that combines Mixture Density Networks (MDN) and considers the driving heterogeneity to provide probabilistic and personalized predictions. Specifically, based on a certain length of historical trajectory data, the situation-specific driving preferences of each driver are identified, where key driving behavior feature vectors are extracted to characterize heterogeneity in driving behavior among different drivers. With the inputs of the short-term historical trajectory data and key driving behavior feature vectors, a probabilistic LSTMMD-DBV model combined with LSTM-based encoder-decoder networks and MDN layers is utilized to carry out personalized predictions. Finally, the SHapley Additive exPlanations (SHAP) method is employed to interpret the trained model for predictions. The proposed framework is tested based on a wide-range vehicle trajectory dataset. The results indicate that the proposed model can generate probabilistic future trajectories with remarkably improved predictions compared to existing benchmark models. Moreover, the results confirm that the additional input of driving behavior feature vectors representing the heterogeneity of driving behavior could provide more information and thus contribute to improving the prediction accuracy.
Superpixel-based and Spatially-regularized Diffusion Learning for Unsupervised Hyperspectral Image Clustering
Dec 24, 2023Hyperspectral images (HSIs) provide exceptional spatial and spectral resolution of a scene, crucial for various remote sensing applications. However, the high dimensionality, presence of noise and outliers, and the need for precise labels of HSIs present significant challenges to HSIs analysis, motivating the development of performant HSI clustering algorithms. This paper introduces a novel unsupervised HSI clustering algorithm, Superpixel-based and Spatially-regularized Diffusion Learning (S2DL), which addresses these challenges by incorporating rich spatial information encoded in HSIs into diffusion geometry-based clustering. S2DL employs the Entropy Rate Superpixel (ERS) segmentation technique to partition an image into superpixels, then constructs a spatially-regularized diffusion graph using the most representative high-density pixels. This approach reduces computational burden while preserving accuracy. Cluster modes, serving as exemplars for underlying cluster structure, are identified as the highest-density pixels farthest in diffusion distance from other highest-density pixels. These modes guide the labeling of the remaining representative pixels from ERS superpixels. Finally, majority voting is applied to the labels assigned within each superpixel to propagate labels to the rest of the image. This spatial-spectral approach simultaneously simplifies graph construction, reduces computational cost, and improves clustering performance. S2DL's performance is illustrated with extensive experiments on three publicly available, real-world HSIs: Indian Pines, Salinas, and Salinas A. Additionally, we apply S2DL to landscape-scale, unsupervised mangrove species mapping in the Mai Po Nature Reserve, Hong Kong, using a Gaofen-5 HSI. The success of S2DL in these diverse numerical experiments indicates its efficacy on a wide range of important unsupervised remote sensing analysis tasks.
Beam Foreseeing in Millimeter-Wave Systems with Situational Awareness: Fundamental Limits via Cramér-Rao Lower Bound
Dec 22, 2023Millimeter-wave (mmWave) networks offer the potential for high-speed data transfer and precise localization, leveraging large antenna arrays and extensive bandwidths. However, these networks are challenged by significant path loss and susceptibility to blockages. In this study, we delve into the use of situational awareness for beam prediction within the 5G NR beam management framework. We introduce an analytical framework based on the Cram\'{e}r-Rao Lower Bound, enabling the quantification of 6D position-related information of geometric reflectors. This includes both 3D locations and 3D orientation biases, facilitating accurate determinations of the beamforming gain achievable by each reflector or candidate beam. This framework empowers us to predict beam alignment performance at any given location in the environment, ensuring uninterrupted wireless access. Our analysis offers critical insights for choosing the most effective beam and antenna module strategies, particularly in scenarios where communication stability is threatened by blockages. Simulation results show that our approach closely approximates the performance of an ideal, Oracle-based solution within the existing 5G NR beam management system.
PoseViNet: Distracted Driver Action Recognition Framework Using Multi-View Pose Estimation and Vision Transformer
Dec 22, 2023Driver distraction is a principal cause of traffic accidents. In a study conducted by the National Highway Traffic Safety Administration, engaging in activities such as interacting with in-car menus, consuming food or beverages, or engaging in telephonic conversations while operating a vehicle can be significant sources of driver distraction. From this viewpoint, this paper introduces a novel method for detection of driver distraction using multi-view driver action images. The proposed method is a vision transformer-based framework with pose estimation and action inference, namely PoseViNet. The motivation for adding posture information is to enable the transformer to focus more on key features. As a result, the framework is more adept at identifying critical actions. The proposed framework is compared with various state-of-the-art models using SFD3 dataset representing 10 behaviors of drivers. It is found from the comparison that the PoseViNet outperforms these models. The proposed framework is also evaluated with the SynDD1 dataset representing 16 behaviors of driver. As a result, the PoseViNet achieves 97.55% validation accuracy and 90.92% testing accuracy with the challenging dataset.
CaptainCook4D: A dataset for understanding errors in procedural activities
Dec 22, 2023Following step-by-step procedures is an essential component of various activities carried out by individuals in their daily lives. These procedures serve as a guiding framework that helps to achieve goals efficiently, whether it is assembling furniture or preparing a recipe. However, the complexity and duration of procedural activities inherently increase the likelihood of making errors. Understanding such procedural activities from a sequence of frames is a challenging task that demands an accurate interpretation of visual information and the ability to reason about the structure of the activity. To this end, we collect a new egocentric 4D dataset, CaptainCook4D, comprising 384 recordings (94.5 hours) of people performing recipes in real kitchen environments. This dataset consists of two distinct types of activity: one in which participants adhere to the provided recipe instructions and another in which they deviate and induce errors. We provide 5.3K step annotations and 10K fine-grained action annotations and benchmark the dataset for the following tasks: supervised error recognition, multistep localization, and procedure learning
AI Generated Signal for Wireless Sensing
Dec 22, 2023Deep learning has significantly advanced wireless sensing technology by leveraging substantial amounts of high-quality training data. However, collecting wireless sensing data encounters diverse challenges, including unavoidable data noise, limited data scale due to significant collection overhead, and the necessity to reacquire data in new environments. Taking inspiration from the achievements of AI-generated content, this paper introduces a signal generation method that achieves data denoising, augmentation, and synthesis by disentangling distinct attributes within the signal, such as individual and environment. The approach encompasses two pivotal modules: structured signal selection and signal disentanglement generation. Structured signal selection establishes a minimal signal set with the target attributes for subsequent attribute disentanglement. Signal disentanglement generation disentangles the target attributes and reassembles them to generate novel signals. Extensive experimental results demonstrate that the proposed method can generate data that closely resembles real-world data on two wireless sensing datasets, exhibiting state-of-the-art performance. Our approach presents a robust framework for comprehending and manipulating attribute-specific information in wireless sensing.
Paint3D: Paint Anything 3D with Lighting-Less Texture Diffusion Models
Dec 22, 2023This paper presents Paint3D, a novel coarse-to-fine generative framework that is capable of producing high-resolution, lighting-less, and diverse 2K UV texture maps for untextured 3D meshes conditioned on text or image inputs. The key challenge addressed is generating high-quality textures without embedded illumination information, which allows the textures to be re-lighted or re-edited within modern graphics pipelines. To achieve this, our method first leverages a pre-trained depth-aware 2D diffusion model to generate view-conditional images and perform multi-view texture fusion, producing an initial coarse texture map. However, as 2D models cannot fully represent 3D shapes and disable lighting effects, the coarse texture map exhibits incomplete areas and illumination artifacts. To resolve this, we train separate UV Inpainting and UVHD diffusion models specialized for the shape-aware refinement of incomplete areas and the removal of illumination artifacts. Through this coarse-to-fine process, Paint3D can produce high-quality 2K UV textures that maintain semantic consistency while being lighting-less, significantly advancing the state-of-the-art in texturing 3D objects.
Mirror: A Universal Framework for Various Information Extraction Tasks
Nov 09, 2023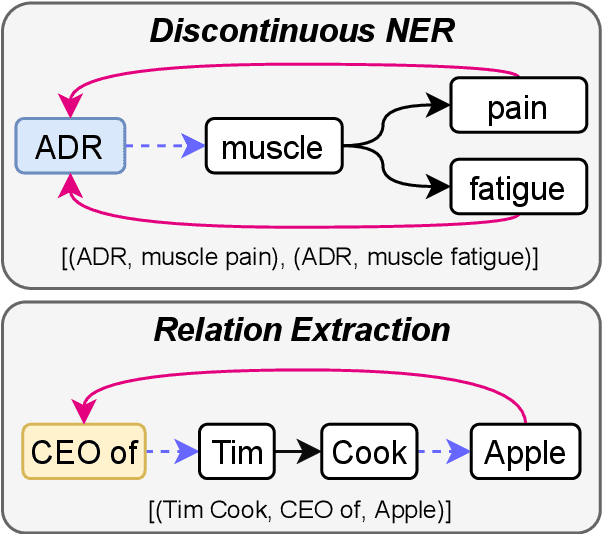
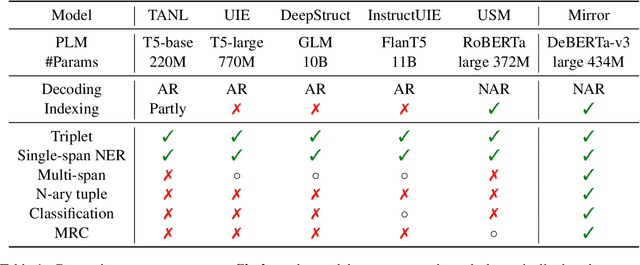
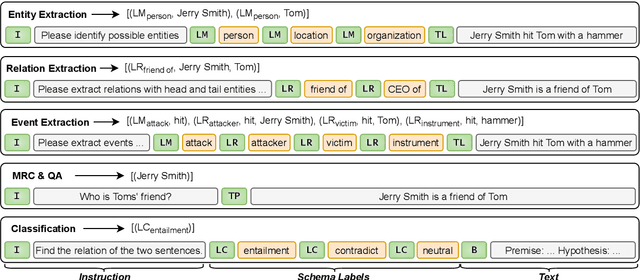
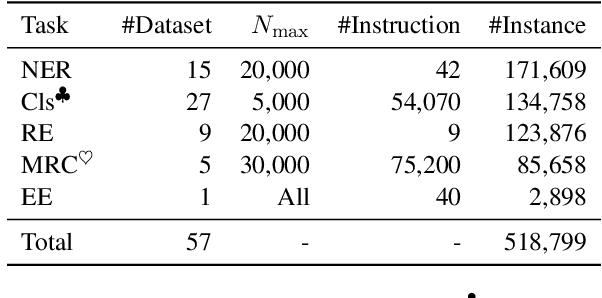
Sharing knowledge between information extraction tasks has always been a challenge due to the diverse data formats and task variations. Meanwhile, this divergence leads to information waste and increases difficulties in building complex applications in real scenarios. Recent studies often formulate IE tasks as a triplet extraction problem. However, such a paradigm does not support multi-span and n-ary extraction, leading to weak versatility. To this end, we reorganize IE problems into unified multi-slot tuples and propose a universal framework for various IE tasks, namely Mirror. Specifically, we recast existing IE tasks as a multi-span cyclic graph extraction problem and devise a non-autoregressive graph decoding algorithm to extract all spans in a single step. It is worth noting that this graph structure is incredibly versatile, and it supports not only complex IE tasks, but also machine reading comprehension and classification tasks. We manually construct a corpus containing 57 datasets for model pretraining, and conduct experiments on 30 datasets across 8 downstream tasks. The experimental results demonstrate that our model has decent compatibility and outperforms or reaches competitive performance with SOTA systems under few-shot and zero-shot settings. The code, model weights, and pretraining corpus are available at https://github.com/Spico197/Mirror .
Sampling Complexity of Deep Approximation Spaces
Dec 20, 2023While it is well-known that neural networks enjoy excellent approximation capabilities, it remains a big challenge to compute such approximations from point samples. Based on tools from Information-based complexity, recent work by Grohs and Voigtlaender [Journal of the FoCM (2023)] developed a rigorous framework for assessing this so-called "theory-to-practice gap". More precisely, in that work it is shown that there exist functions that can be approximated by neural networks with ReLU activation function at an arbitrary rate while requiring an exponentially growing (in the input dimension) number of samples for their numerical computation. The present study extends these findings by showing analogous results for the ReQU activation function.
Expand-and-Quantize: Unsupervised Semantic Segmentation Using High-Dimensional Space and Product Quantization
Dec 12, 2023Unsupervised semantic segmentation (USS) aims to discover and recognize meaningful categories without any labels. For a successful USS, two key abilities are required: 1) information compression and 2) clustering capability. Previous methods have relied on feature dimension reduction for information compression, however, this approach may hinder the process of clustering. In this paper, we propose a novel USS framework called Expand-and-Quantize Unsupervised Semantic Segmentation (EQUSS), which combines the benefits of high-dimensional spaces for better clustering and product quantization for effective information compression. Our extensive experiments demonstrate that EQUSS achieves state-of-the-art results on three standard benchmarks. In addition, we analyze the entropy of USS features, which is the first step towards understanding USS from the perspective of information theory.