 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Helping Language Models Learn More: Multi-dimensional Task Prompt for Few-shot Tuning
Dec 13, 2023
Large language models (LLMs) can be used as accessible and intelligent chatbots by constructing natural language queries and directly inputting the prompt into the large language model. However, different prompt' constructions often lead to uncertainty in the answers and thus make it hard to utilize the specific knowledge of LLMs (like ChatGPT). To alleviate this, we use an interpretable structure to explain the prompt learning principle in LLMs, which certificates that the effectiveness of language models is determined by position changes of the task's related tokens. Therefore, we propose MTPrompt, a multi-dimensional task prompt learning method consisting based on task-related object, summary, and task description information. By automatically building and searching for appropriate prompts, our proposed MTPrompt achieves the best results on few-shot samples setting and five different datasets. In addition, we demonstrate the effectiveness and stability of our method in different experimental settings and ablation experiments. In interaction with large language models, embedding more task-related information into prompts will make it easier to stimulate knowledge embedded in large language models.
Mono3DVG: 3D Visual Grounding in Monocular Images
Dec 13, 2023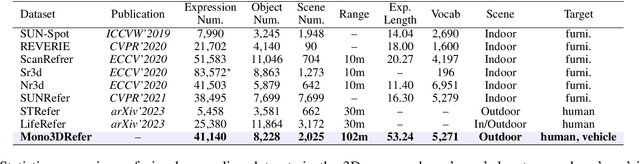


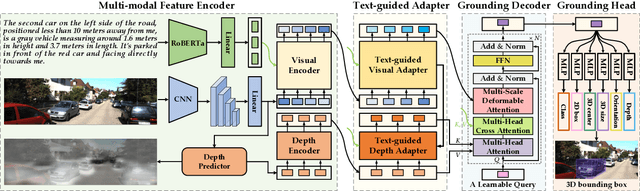
We introduce a novel task of 3D visual grounding in monocular RGB images using language descriptions with both appearance and geometry information. Specifically, we build a large-scale dataset, Mono3DRefer, which contains 3D object targets with their corresponding geometric text descriptions, generated by ChatGPT and refined manually. To foster this task, we propose Mono3DVG-TR, an end-to-end transformer-based network, which takes advantage of both the appearance and geometry information in text embeddings for multi-modal learning and 3D object localization. Depth predictor is designed to explicitly learn geometry features. The dual text-guided adapter is proposed to refine multiscale visual and geometry features of the referred object. Based on depth-text-visual stacking attention, the decoder fuses object-level geometric cues and visual appearance into a learnable query. Comprehensive benchmarks and some insightful analyses are provided for Mono3DVG. Extensive comparisons and ablation studies show that our method significantly outperforms all baselines. The dataset and code will be publicly available at: https://github.com/ZhanYang-nwpu/Mono3DVG.
Cross-modal Contrastive Learning with Asymmetric Co-attention Network for Video Moment Retrieval
Dec 12, 2023Video moment retrieval is a challenging task requiring fine-grained interactions between video and text modalities. Recent work in image-text pretraining has demonstrated that most existing pretrained models suffer from information asymmetry due to the difference in length between visual and textual sequences. We question whether the same problem also exists in the video-text domain with an auxiliary need to preserve both spatial and temporal information. Thus, we evaluate a recently proposed solution involving the addition of an asymmetric co-attention network for video grounding tasks. Additionally, we incorporate momentum contrastive loss for robust, discriminative representation learning in both modalities. We note that the integration of these supplementary modules yields better performance compared to state-of-the-art models on the TACoS dataset and comparable results on ActivityNet Captions, all while utilizing significantly fewer parameters with respect to baseline.
Semi-Supervised Clustering via Structural Entropy with Different Constraints
Dec 18, 2023Semi-supervised clustering techniques have emerged as valuable tools for leveraging prior information in the form of constraints to improve the quality of clustering outcomes. Despite the proliferation of such methods, the ability to seamlessly integrate various types of constraints remains limited. While structural entropy has proven to be a powerful clustering approach with wide-ranging applications, it has lacked a variant capable of accommodating these constraints. In this work, we present Semi-supervised clustering via Structural Entropy (SSE), a novel method that can incorporate different types of constraints from diverse sources to perform both partitioning and hierarchical clustering. Specifically, we formulate a uniform view for the commonly used pairwise and label constraints for both types of clustering. Then, we design objectives that incorporate these constraints into structural entropy and develop tailored algorithms for their optimization. We evaluate SSE on nine clustering datasets and compare it with eleven semi-supervised partitioning and hierarchical clustering methods. Experimental results demonstrate the superiority of SSE on clustering accuracy with different types of constraints. Additionally, the functionality of SSE for biological data analysis is demonstrated by cell clustering experiments conducted on four single-cell RNAseq datasets.
TMP: Temporal Motion Propagation for Online Video Super-Resolution
Dec 18, 2023Online video super-resolution (online-VSR) highly relies on an effective alignment module to aggregate temporal information, while the strict latency requirement makes accurate and efficient alignment very challenging. Though much progress has been achieved, most of the existing online-VSR methods estimate the motion fields of each frame separately to perform alignment, which is computationally redundant and ignores the fact that the motion fields of adjacent frames are correlated. In this work, we propose an efficient Temporal Motion Propagation (TMP) method, which leverages the continuity of motion field to achieve fast pixel-level alignment among consecutive frames. Specifically, we first propagate the offsets from previous frames to the current frame, and then refine them in the neighborhood, which significantly reduces the matching space and speeds up the offset estimation process. Furthermore, to enhance the robustness of alignment, we perform spatial-wise weighting on the warped features, where the positions with more precise offsets are assigned higher importance. Experiments on benchmark datasets demonstrate that the proposed TMP method achieves leading online-VSR accuracy as well as inference speed. The source code of TMP can be found at https://github.com/xtudbxk/TMP.
Application of AI in Nutrition
Dec 18, 2023
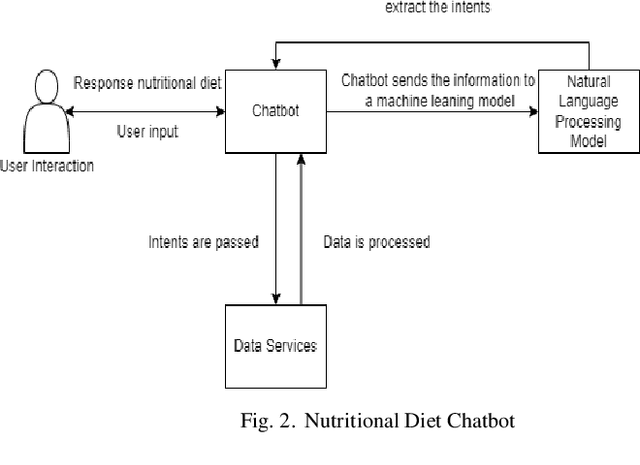
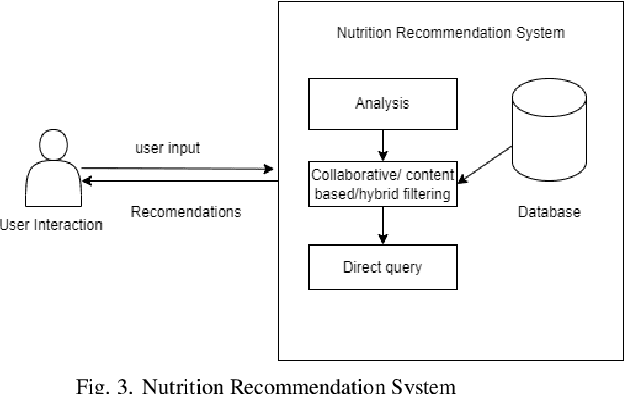

In healthcare, artificial intelligence (AI) has been changing the way doctors and health experts take care of people. This paper will cover how AI is making major changes in the health care system, especially with nutrition. Various machine learning and deep learning algorithms have been developed to extract valuable information from healthcare data which help doctors, nutritionists, and health experts to make better decisions and make our lifestyle healthy. This paper provides an overview of the current state of AI applications in healthcare with a focus on the utilization of AI-driven recommender systems in nutrition. It will discuss the positive outcomes and challenges that arise when AI is used in this field. This paper addresses the challenges to develop AI recommender systems in healthcare, providing a well-rounded perspective on the complexities. Real-world examples and research findings are presented to underscore the tangible and significant impact AI recommender systems have in the field of healthcare, particularly in nutrition. The ongoing efforts of applying AI in nutrition lay the groundwork for a future where personalized recommendations play a pivotal role in guiding individuals toward healthier lifestyles.
Warping the Residuals for Image Editing with StyleGAN
Dec 18, 2023StyleGAN models show editing capabilities via their semantically interpretable latent organizations which require successful GAN inversion methods to edit real images. Many works have been proposed for inverting images into StyleGAN's latent space. However, their results either suffer from low fidelity to the input image or poor editing qualities, especially for edits that require large transformations. That is because low-rate latent spaces lose many image details due to the information bottleneck even though it provides an editable space. On the other hand, higher-rate latent spaces can pass all the image details to StyleGAN for perfect reconstruction of images but suffer from low editing qualities. In this work, we present a novel image inversion architecture that extracts high-rate latent features and includes a flow estimation module to warp these features to adapt them to edits. The flows are estimated from StyleGAN features of edited and unedited latent codes. By estimating the high-rate features and warping them for edits, we achieve both high-fidelity to the input image and high-quality edits. We run extensive experiments and compare our method with state-of-the-art inversion methods. Qualitative metrics and visual comparisons show significant improvements.
TIP: Text-Driven Image Processing with Semantic and Restoration Instructions
Dec 18, 2023Text-driven diffusion models have become increasingly popular for various image editing tasks, including inpainting, stylization, and object replacement. However, it still remains an open research problem to adopt this language-vision paradigm for more fine-level image processing tasks, such as denoising, super-resolution, deblurring, and compression artifact removal. In this paper, we develop TIP, a Text-driven Image Processing framework that leverages natural language as a user-friendly interface to control the image restoration process. We consider the capacity of text information in two dimensions. First, we use content-related prompts to enhance the semantic alignment, effectively alleviating identity ambiguity in the restoration outcomes. Second, our approach is the first framework that supports fine-level instruction through language-based quantitative specification of the restoration strength, without the need for explicit task-specific design. In addition, we introduce a novel fusion mechanism that augments the existing ControlNet architecture by learning to rescale the generative prior, thereby achieving better restoration fidelity. Our extensive experiments demonstrate the superior restoration performance of TIP compared to the state of the arts, alongside offering the flexibility of text-based control over the restoration effects.
Dirichlet-based Uncertainty Quantification for Personalized Federated Learning with Improved Posterior Networks
Dec 18, 2023In modern federated learning, one of the main challenges is to account for inherent heterogeneity and the diverse nature of data distributions for different clients. This problem is often addressed by introducing personalization of the models towards the data distribution of the particular client. However, a personalized model might be unreliable when applied to the data that is not typical for this client. Eventually, it may perform worse for these data than the non-personalized global model trained in a federated way on the data from all the clients. This paper presents a new approach to federated learning that allows selecting a model from global and personalized ones that would perform better for a particular input point. It is achieved through a careful modeling of predictive uncertainties that helps to detect local and global in- and out-of-distribution data and use this information to select the model that is confident in a prediction. The comprehensive experimental evaluation on the popular real-world image datasets shows the superior performance of the model in the presence of out-of-distribution data while performing on par with state-of-the-art personalized federated learning algorithms in the standard scenarios.
Investigating salient representations and label Variance in Dimensional Speech Emotion Analysis
Dec 17, 2023Representations derived from models such as BERT (Bidirectional Encoder Representations from Transformers) and HuBERT (Hidden units BERT), have helped to achieve state-of-the-art performance in dimensional speech emotion recognition. Despite their large dimensionality, and even though these representations are not tailored for emotion recognition tasks, they are frequently used to train large speech emotion models with high memory and computational costs. In this work, we show that there exist lower-dimensional subspaces within the these pre-trained representational spaces that offer a reduction in downstream model complexity without sacrificing performance on emotion estimation. In addition, we model label uncertainty in the form of grader opinion variance, and demonstrate that such information can improve the models generalization capacity and robustness. Finally, we compare the robustness of the emotion models against acoustic degradations and observed that the reduced dimensional representations were able to retain the performance similar to the full-dimensional representations without significant regression in dimensional emotion performance.
* 5 pages