 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
NTrack: A Multiple-Object Tracker and Dataset for Infield Cotton Boll Counting
Dec 18, 2023
In agriculture, automating the accurate tracking of fruits, vegetables, and fiber is a very tough problem. The issue becomes extremely challenging in dynamic field environments. Yet, this information is critical for making day-to-day agricultural decisions, assisting breeding programs, and much more. To tackle this dilemma, we introduce NTrack, a novel multiple object tracking framework based on the linear relationship between the locations of neighboring tracks. NTrack computes dense optical flow and utilizes particle filtering to guide each tracker. Correspondences between detections and tracks are found through data association via direct observations and indirect cues, which are then combined to obtain an updated observation. Our modular multiple object tracking system is independent of the underlying detection method, thus allowing for the interchangeable use of any off-the-shelf object detector. We show the efficacy of our approach on the task of tracking and counting infield cotton bolls. Experimental results show that our system exceeds contemporary tracking and cotton boll-based counting methods by a large margin. Furthermore, we publicly release the first annotated cotton boll video dataset to the research community.
Discovering Geo-dependent Stories by Combining Density-based Clustering and Thread-based Aggregation techniques
Dec 18, 2023Citizens are actively interacting with their surroundings, especially through social media. Not only do shared posts give important information about what is happening (from the users' perspective), but also the metadata linked to these posts offer relevant data, such as the GPS-location in Location-based Social Networks (LBSNs). In this paper we introduce a global analysis of the geo-tagged posts in social media which supports (i) the detection of unexpected behavior in the city and (ii) the analysis of the posts to infer what is happening. The former is obtained by applying density-based clustering techniques, whereas the latter is consequence of applying natural language processing. We have applied our methodology to a dataset obtained from Instagram activity in New York City for seven months obtaining promising results. The developed algorithms require very low resources, being able to analyze millions of data-points in commodity hardware in less than one hour without applying complex parallelization techniques. Furthermore, the solution can be easily adapted to other geo-tagged data sources without extra effort.
* 11 pages, 12 figures, journal
TOP-ReID: Multi-spectral Object Re-Identification with Token Permutation
Dec 15, 2023Multi-spectral object Re-identification (ReID) aims to retrieve specific objects by leveraging complementary information from different image spectra. It delivers great advantages over traditional single-spectral ReID in complex visual environment. However, the significant distribution gap among different image spectra poses great challenges for effective multi-spectral feature representations. In addition, most of current Transformer-based ReID methods only utilize the global feature of class tokens to achieve the holistic retrieval, ignoring the local discriminative ones. To address the above issues, we step further to utilize all the tokens of Transformers and propose a cyclic token permutation framework for multi-spectral object ReID, dubbled TOP-ReID. More specifically, we first deploy a multi-stream deep network based on vision Transformers to preserve distinct information from different image spectra. Then, we propose a Token Permutation Module (TPM) for cyclic multi-spectral feature aggregation. It not only facilitates the spatial feature alignment across different image spectra, but also allows the class token of each spectrum to perceive the local details of other spectra. Meanwhile, we propose a Complementary Reconstruction Module (CRM), which introduces dense token-level reconstruction constraints to reduce the distribution gap across different image spectra. With the above modules, our proposed framework can generate more discriminative multi-spectral features for robust object ReID. Extensive experiments on three ReID benchmarks (i.e., RGBNT201, RGBNT100 and MSVR310) verify the effectiveness of our methods. The code is available at https://github.com/924973292/TOP-ReID.
AdaSub: Stochastic Optimization Using Second-Order Information in Low-Dimensional Subspaces
Nov 06, 2023We introduce AdaSub, a stochastic optimization algorithm that computes a search direction based on second-order information in a low-dimensional subspace that is defined adaptively based on available current and past information. Compared to first-order methods, second-order methods exhibit better convergence characteristics, but the need to compute the Hessian matrix at each iteration results in excessive computational expenses, making them impractical. To address this issue, our approach enables the management of computational expenses and algorithm efficiency by enabling the selection of the subspace dimension for the search. Our code is freely available on GitHub, and our preliminary numerical results demonstrate that AdaSub surpasses popular stochastic optimizers in terms of time and number of iterations required to reach a given accuracy.
LLF-Bench: Benchmark for Interactive Learning from Language Feedback
Dec 13, 2023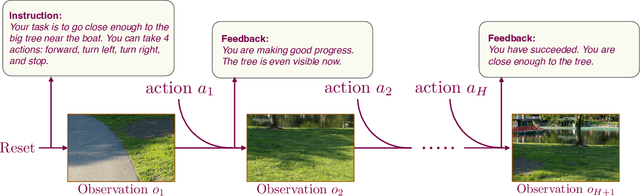
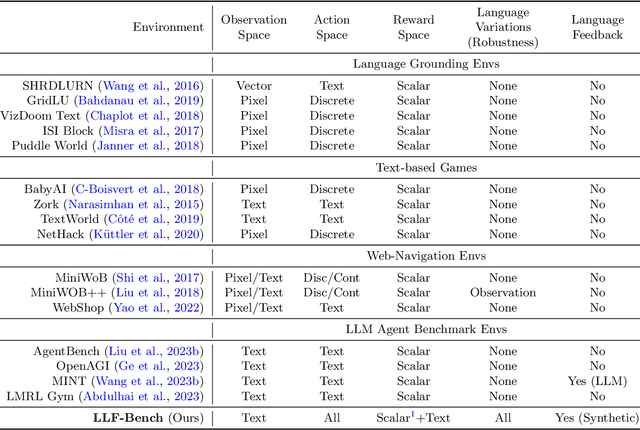
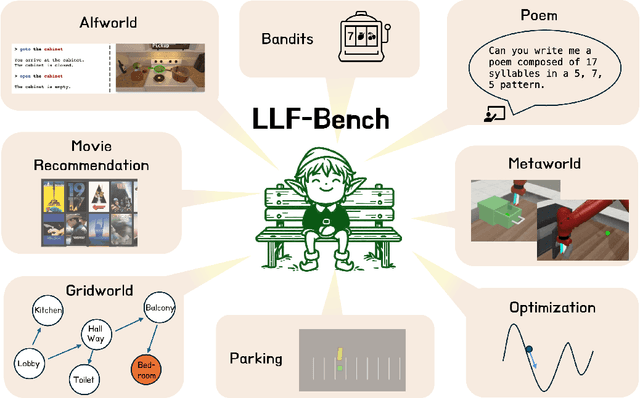
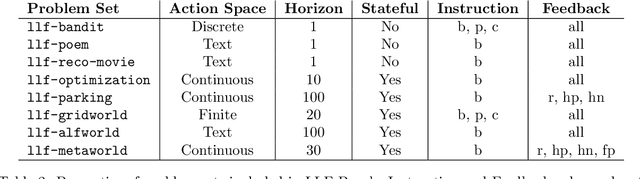
We introduce a new benchmark, LLF-Bench (Learning from Language Feedback Benchmark; pronounced as "elf-bench"), to evaluate the ability of AI agents to interactively learn from natural language feedback and instructions. Learning from language feedback (LLF) is essential for people, largely because the rich information this feedback provides can help a learner avoid much of trial and error and thereby speed up the learning process. Large Language Models (LLMs) have recently enabled AI agents to comprehend natural language -- and hence AI agents can potentially benefit from language feedback during learning like humans do. But existing interactive benchmarks do not assess this crucial capability: they either use numeric reward feedback or require no learning at all (only planning or information retrieval). LLF-Bench is designed to fill this omission. LLF-Bench is a diverse collection of sequential decision-making tasks that includes user recommendation, poem writing, navigation, and robot control. The objective of an agent is to interactively solve these tasks based on their natural-language instructions and the feedback received after taking actions. Crucially, to ensure that the agent actually "learns" from the feedback, LLF-Bench implements several randomization techniques (such as paraphrasing and environment randomization) to ensure that the task isn't familiar to the agent and that the agent is robust to various verbalizations. In addition, LLF-Bench provides a unified OpenAI Gym interface for all its tasks and allows the users to easily configure the information the feedback conveys (among suggestion, explanation, and instantaneous performance) to study how agents respond to different types of feedback. Together, these features make LLF-Bench a unique research platform for developing and testing LLF agents.
FER-C: Benchmarking Out-of-Distribution Soft Calibration for Facial Expression Recognition
Dec 16, 2023We present a soft benchmark for calibrating facial expression recognition (FER). While prior works have focused on identifying affective states, we find that FER models are uncalibrated. This is particularly true when out-of-distribution (OOD) shifts further exacerbate the ambiguity of facial expressions. While most OOD benchmarks provide hard labels, we argue that the ground-truth labels for evaluating FER models should be soft in order to better reflect the ambiguity behind facial behaviours. Our framework proposes soft labels that closely approximates the average information loss based on different types of OOD shifts. Finally, we show the benefits of calibration on five state-of-the-art FER algorithms tested on our benchmark.
Multimodal Sentiment Analysis: Perceived vs Induced Sentiments
Dec 12, 2023Social media has created a global network where people can easily access and exchange vast information. This information gives rise to a variety of opinions, reflecting both positive and negative viewpoints. GIFs stand out as a multimedia format offering a visually engaging way for users to communicate. In this research, we propose a multimodal framework that integrates visual and textual features to predict the GIF sentiment. It also incorporates attributes including face emotion detection and OCR generated captions to capture the semantic aspects of the GIF. The developed classifier achieves an accuracy of 82.7% on Twitter GIFs, which is an improvement over state-of-the-art models. Moreover, we have based our research on the ReactionGIF dataset, analysing the variance in sentiment perceived by the author and sentiment induced in the reader
Metalearning with Very Few Samples Per Task
Dec 21, 2023Metalearning and multitask learning are two frameworks for solving a group of related learning tasks more efficiently than we could hope to solve each of the individual tasks on their own. In multitask learning, we are given a fixed set of related learning tasks and need to output one accurate model per task, whereas in metalearning we are given tasks that are drawn i.i.d. from a metadistribution and need to output some common information that can be easily specialized to new, previously unseen tasks from the metadistribution. In this work, we consider a binary classification setting where tasks are related by a shared representation, that is, every task $P$ of interest can be solved by a classifier of the form $f_{P} \circ h$ where $h \in H$ is a map from features to some representation space that is shared across tasks, and $f_{P} \in F$ is a task-specific classifier from the representation space to labels. The main question we ask in this work is how much data do we need to metalearn a good representation? Here, the amount of data is measured in terms of both the number of tasks $t$ that we need to see and the number of samples $n$ per task. We focus on the regime where the number of samples per task is extremely small. Our main result shows that, in a distribution-free setting where the feature vectors are in $\mathbb{R}^d$, the representation is a linear map from $\mathbb{R}^d \to \mathbb{R}^k$, and the task-specific classifiers are halfspaces in $\mathbb{R}^k$, we can metalearn a representation with error $\varepsilon$ using just $n = k+2$ samples per task, and $d \cdot (1/\varepsilon)^{O(k)}$ tasks. Learning with so few samples per task is remarkable because metalearning would be impossible with $k+1$ samples per task, and because we cannot even hope to learn an accurate task-specific classifier with just $k+2$ samples per task.
Spot the Bot: Distinguishing Human-Written and Bot-Generated Texts Using Clustering and Information Theory Techniques
Nov 19, 2023With the development of generative models like GPT-3, it is increasingly more challenging to differentiate generated texts from human-written ones. There is a large number of studies that have demonstrated good results in bot identification. However, the majority of such works depend on supervised learning methods that require labelled data and/or prior knowledge about the bot-model architecture. In this work, we propose a bot identification algorithm that is based on unsupervised learning techniques and does not depend on a large amount of labelled data. By combining findings in semantic analysis by clustering (crisp and fuzzy) and information techniques, we construct a robust model that detects a generated text for different types of bot. We find that the generated texts tend to be more chaotic while literary works are more complex. We also demonstrate that the clustering of human texts results in fuzzier clusters in comparison to the more compact and well-separated clusters of bot-generated texts.
Leveraging Structured Information for Explainable Multi-hop Question Answering and Reasoning
Nov 07, 2023Neural models, including large language models (LLMs), achieve superior performance on multi-hop question-answering. To elicit reasoning capabilities from LLMs, recent works propose using the chain-of-thought (CoT) mechanism to generate both the reasoning chain and the answer, which enhances the model's capabilities in conducting multi-hop reasoning. However, several challenges still remain: such as struggling with inaccurate reasoning, hallucinations, and lack of interpretability. On the other hand, information extraction (IE) identifies entities, relations, and events grounded to the text. The extracted structured information can be easily interpreted by humans and machines (Grishman, 2019). In this work, we investigate constructing and leveraging extracted semantic structures (graphs) for multi-hop question answering, especially the reasoning process. Empirical results and human evaluations show that our framework: generates more faithful reasoning chains and substantially improves the QA performance on two benchmark datasets. Moreover, the extracted structures themselves naturally provide grounded explanations that are preferred by humans, as compared to the generated reasoning chains and saliency-based explanations.