 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-criteria recommendation systems to foster online grocery
Dec 12, 2023
With the exponential increase in information, it has become imperative to design mechanisms that allow users to access what matters to them as quickly as possible. The recommendation system ($RS$) with information technology development is the solution, it is an intelligent system. Various types of data can be collected on items of interest to users and presented as recommendations. $RS$ also play a very important role in e-commerce. The purpose of recommending a product is to designate the most appropriate designation for a specific product. The major challenges when recommending products are insufficient information about the products and the categories to which they belong. In this paper, we transform the product data using two methods of document representation: bag-of-words (BOW) and the neural network-based document combination known as vector-based (Doc2Vec). We propose three-criteria recommendation systems (product, package, and health) for each document representation method to foster online grocery, which depends on product characteristics such as (composition, packaging, nutrition table, allergen, etc.). For our evaluation, we conducted a user and expert survey. Finally, we have compared the performance of these three criteria for each document representation method, discovering that the neural network-based (Doc2Vec) performs better and completely alters the results.
* 30 pages, 8 images, journal
Using eye tracking to investigate what native Chinese speakers notice about linguistic landscape images
Dec 16, 2023Linguistic landscape is an important field in sociolinguistic research. Eye tracking technology is a common technology in psychological research. There are few cases of using eye movement to study linguistic landscape. This paper uses eye tracking technology to study the actual fixation of the linguistic landscape and finds that in the two dimensions of fixation time and fixation times, the fixation of native Chinese speakers to the linguistic landscape is higher than that of the general landscape. This paper argues that this phenomenon is due to the higher information density of linguistic landscapes. At the same time, the article also discusses other possible reasons for this phenomenon.
Mapping Housing Stock Characteristics from Drone Images for Climate Resilience in the Caribbean
Dec 16, 2023Comprehensive information on housing stock is crucial for climate adaptation initiatives aiming to reduce the adverse impacts of climate-extreme hazards in high-risk regions like the Caribbean. In this study, we propose a workflow for rapidly generating critical baseline housing stock data using very high-resolution drone images and deep learning techniques. Specifically, our work leverages the Segment Anything Model and convolutional neural networks for the automated generation of building footprints and roof classification maps. By strengthening local capacity within government agencies to leverage AI and Earth Observation-based solutions, this work seeks to improve the climate resilience of the housing sector in small island developing states in the Caribbean.
UstanceBR: a multimodal language resource for stance prediction
Dec 11, 2023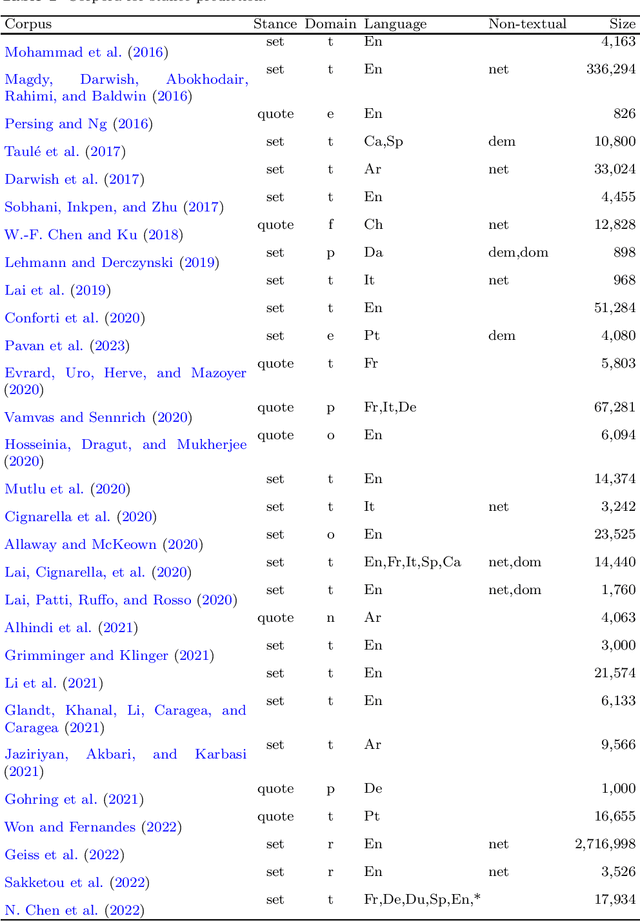
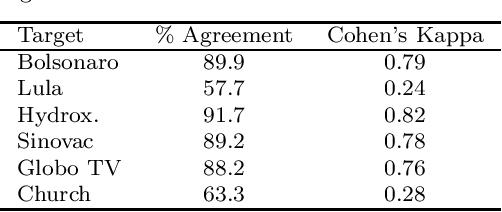
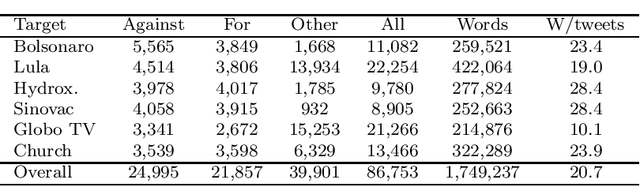
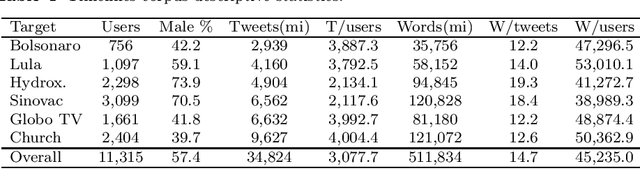
This work introduces UstanceBR, a multimodal corpus in the Brazilian Portuguese Twitter domain for target-based stance prediction. The corpus comprises 86.8 k labelled stances towards selected target topics, and extensive network information about the users who published these stances on social media. In this article we describe the corpus multimodal data, and a number of usage examples in both in-domain and zero-shot stance prediction based on text- and network-related information, which are intended to provide initial baseline results for future studies in the field.
Fuzzy Information Seeded Region Growing for Automated Lesions After Stroke Segmentation in MR Brain Images
Nov 20, 2023In the realm of medical imaging, precise segmentation of stroke lesions from brain MRI images stands as a critical challenge with significant implications for patient diagnosis and treatment. Addressing this, our study introduces an innovative approach using a Fuzzy Information Seeded Region Growing (FISRG) algorithm. Designed to effectively delineate the complex and irregular boundaries of stroke lesions, the FISRG algorithm combines fuzzy logic with Seeded Region Growing (SRG) techniques, aiming to enhance segmentation accuracy. The research involved three experiments to optimize the FISRG algorithm's performance, each focusing on different parameters to improve the accuracy of stroke lesion segmentation. The highest Dice score achieved in these experiments was 94.2\%, indicating a high degree of similarity between the algorithm's output and the expert-validated ground truth. Notably, the best average Dice score, amounting to 88.1\%, was recorded in the third experiment, highlighting the efficacy of the algorithm in consistently segmenting stroke lesions across various slices. Our findings reveal the FISRG algorithm's strengths in handling the heterogeneity of stroke lesions. However, challenges remain in areas of abrupt lesion topology changes and in distinguishing lesions from similar intensity brain regions. The results underscore the potential of the FISRG algorithm in contributing significantly to advancements in medical imaging analysis for stroke diagnosis and treatment.
Information Geometry for the Working Information Theorist
Oct 05, 2023Information geometry is a study of statistical manifolds, that is, spaces of probability distributions from a geometric perspective. Its classical information-theoretic applications relate to statistical concepts such as Fisher information, sufficient statistics, and efficient estimators. Today, information geometry has emerged as an interdisciplinary field that finds applications in diverse areas such as radar sensing, array signal processing, quantum physics, deep learning, and optimal transport. This article presents an overview of essential information geometry to initiate an information theorist, who may be unfamiliar with this exciting area of research. We explain the concepts of divergences on statistical manifolds, generalized notions of distances, orthogonality, and geodesics, thereby paving the way for concrete applications and novel theoretical investigations. We also highlight some recent information-geometric developments, which are of interest to the broader information theory community.
Context-Aware Iteration Policy Network for Efficient Optical Flow Estimation
Dec 14, 2023Existing recurrent optical flow estimation networks are computationally expensive since they use a fixed large number of iterations to update the flow field for each sample. An efficient network should skip iterations when the flow improvement is limited. In this paper, we develop a Context-Aware Iteration Policy Network for efficient optical flow estimation, which determines the optimal number of iterations per sample. The policy network achieves this by learning contextual information to realize whether flow improvement is bottlenecked or minimal. On the one hand, we use iteration embedding and historical hidden cell, which include previous iterations information, to convey how flow has changed from previous iterations. On the other hand, we use the incremental loss to make the policy network implicitly perceive the magnitude of optical flow improvement in the subsequent iteration. Furthermore, the computational complexity in our dynamic network is controllable, allowing us to satisfy various resource preferences with a single trained model. Our policy network can be easily integrated into state-of-the-art optical flow networks. Extensive experiments show that our method maintains performance while reducing FLOPs by about 40%/20% for the Sintel/KITTI datasets.
Image Demoireing in RAW and sRGB Domains
Dec 14, 2023Moir\'e patterns frequently appear when capturing screens with smartphones or cameras, potentially compromising image quality. Previous studies suggest that moir\'e pattern elimination in the RAW domain offers greater efficiency compared to demoir\'eing in the sRGB domain. Nevertheless, relying solely on raw data for image demoir\'eing is insufficient in mitigating color cast due to the absence of essential information required for color correction by the Image Signal Processor (ISP). In this paper, we propose perform Image Demoir\'eing concurrently utilizing both RAW and sRGB data (RRID), which is readily accessible in both smartphones and digital cameras. We develop Skip-Connection-based Demoir\'eing Module (SCDM) with specific modules embeded in skip-connections for the efficient and effective demoir\'eing of RAW and sRGB features, respectively. Subsequently, we propose RGB Guided Image Signal Processor (RGISP) to incorporate color information from coarsely demoir\'ed sRGB features during the ISP stage, assisting the process of color recovery. Extensive experiments demonstrate that our RRID outperforms state-of-the-art approaches by 0.62dB in PSNR and 0.003 in SSIM, exhibiting superior performance both in moir\'e pattern removal and color cast correction.
TAP4LLM: Table Provider on Sampling, Augmenting, and Packing Semi-structured Data for Large Language Model Reasoning
Dec 14, 2023Table reasoning has shown remarkable progress in a wide range of table-based tasks. These challenging tasks require reasoning over both free-form natural language (NL) questions and semi-structured tabular data. However, previous table reasoning solutions suffer from significant performance degradation on "huge" tables. In addition, most existing methods struggle to reason over complex questions since they lack essential information or they are scattered in different places. To alleviate these challenges, we exploit a table provider, namely TAP4LLM, on versatile sampling, augmentation, and packing methods to achieve effective semi-structured data reasoning using large language models (LLMs), which 1) decompose raw tables into sub-tables with specific rows or columns based on the rules or semantic similarity; 2) augment table information by extracting semantic and statistical metadata from raw tables while retrieving relevant knowledge from trustworthy knowledge sources (e.g., Wolfram Alpha, Wikipedia); 3) pack sampled tables with augmented knowledge into sequence prompts for LLMs reasoning while balancing the token allocation trade-off. We show that TAP4LLM allows for different components as plug-ins, enhancing LLMs' understanding of structured data in diverse tabular tasks.
ChatSOS: LLM-based knowledge Q&A system for safety engineering
Dec 14, 2023Recent advancements in large language models (LLMs) have notably propelled natural language processing (NLP) capabilities, demonstrating significant potential in safety engineering applications. Despite these advancements, LLMs face constraints in processing specialized tasks, attributed to factors such as corpus size, input processing limitations, and privacy concerns. Obtaining useful information from reliable sources in a limited time is crucial for LLM. Addressing this, our study introduces an LLM-based Q&A system for safety engineering, enhancing the comprehension and response accuracy of the model. We employed prompt engineering to incorporate external knowledge databases, thus enriching the LLM with up-to-date and reliable information. The system analyzes historical incident reports through statistical methods, utilizes vector embedding to construct a vector database, and offers an efficient similarity-based search functionality. Our findings indicate that the integration of external knowledge significantly augments the capabilities of LLM for in-depth problem analysis and autonomous task assignment. It effectively summarizes accident reports and provides pertinent recommendations. This integration approach not only expands LLM applications in safety engineering but also sets a precedent for future developments towards automation and intelligent systems.