 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-label Learning from Privacy-Label
Dec 20, 2023
Multi-abel Learning (MLL) often involves the assignment of multiple relevant labels to each instance, which can lead to the leakage of sensitive information (such as smoking, diseases, etc.) about the instances. However, existing MLL suffer from failures in protection for sensitive information. In this paper, we propose a novel setting named Multi-Label Learning from Privacy-Label (MLLPL), which Concealing Labels via Privacy-Label Unit (CLPLU). Specifically, during the labeling phase, each privacy-label is randomly combined with a non-privacy label to form a Privacy-Label Unit (PLU). If any label within a PLU is positive, the unit is labeled as positive; otherwise, it is labeled negative, as shown in Figure 1. PLU ensures that only non-privacy labels are appear in the label set, while the privacy-labels remain concealed. Moreover, we further propose a Privacy-Label Unit Loss (PLUL) to learn the optimal classifier by minimizing the empirical risk of PLU. Experimental results on multiple benchmark datasets demonstrate the effectiveness and superiority of the proposed method.
High-Fidelity Diffusion-based Image Editing
Dec 25, 2023Diffusion models have attained remarkable success in the domains of image generation and editing. It is widely recognized that employing larger inversion and denoising steps in diffusion model leads to improved image reconstruction quality. However, the editing performance of diffusion models tends to be no more satisfactory even with increasing denoising steps. The deficiency in editing could be attributed to the conditional Markovian property of the editing process, where errors accumulate throughout denoising steps. To tackle this challenge, we first propose an innovative framework where a rectifier module is incorporated to modulate diffusion model weights with residual features, thereby providing compensatory information to bridge the fidelity gap. Furthermore, we introduce a novel learning paradigm aimed at minimizing error propagation during the editing process, which trains the editing procedure in a manner similar to denoising score-matching. Extensive experiments demonstrate that our proposed framework and training strategy achieve high-fidelity reconstruction and editing results across various levels of denoising steps, meanwhile exhibits exceptional performance in terms of both quantitative metric and qualitative assessments. Moreover, we explore our model's generalization through several applications like image-to-image translation and out-of-domain image editing.
Towards Consistent Language Models Using Declarative Constraints
Dec 24, 2023Large language models have shown unprecedented abilities in generating linguistically coherent and syntactically correct natural language output. However, they often return incorrect and inconsistent answers to input questions. Due to the complexity and uninterpretability of the internally learned representations, it is challenging to modify language models such that they provide correct and consistent results. The data management community has developed various methods and tools for providing consistent answers over inconsistent datasets. In these methods, users specify the desired properties of data in a domain in the form of high-level declarative constraints. This approach has provided usable and scalable methods to delivering consistent information from inconsistent datasets. We aim to build upon this success and leverage these methods to modify language models such that they deliver consistent and accurate results. We investigate the challenges of using these ideas to obtain consistent and relevant answers from language models and report some preliminary empirical studies.
A Belief Propagation Approach for Direct Multipath-Based SLAM
Dec 24, 2023In this work, we develop a multipath-based simultaneous localization and mapping (SLAM) method that can directly be applied to received radio signals. In existing multipath-based SLAM approaches, a channel estimator is used as a preprocessing stage that reduces data flow and computational complexity by extracting features related to multipath components (MPCs). We aim to avoid any preprocessing stage that may lead to a loss of relevant information. The presented method relies on a new statistical model for the data generation process of the received radio signal that can be represented by a factor graph. This factor graph is the starting point for the development of an efficient belief propagation (BP) method for multipath-based SLAM that directly uses received radio signals as measurements. Simulation results in a realistic scenario with a single-input single-output (SISO) channel demonstrate that the proposed direct method for radio-based SLAM outperforms state-of-the-art methods that rely on a channel estimator.
End-to-End 3D Object Detection using LiDAR Point Cloud
Dec 24, 2023There has been significant progress made in the field of autonomous vehicles. Object detection and tracking are the primary tasks for any autonomous vehicle. The task of object detection in autonomous vehicles relies on a variety of sensors like cameras, and LiDAR. Although image features are typically preferred, numerous approaches take spatial data as input. Exploiting this information we present an approach wherein, using a novel encoding of the LiDAR point cloud we infer the location of different classes near the autonomous vehicles. This approach does not implement a bird's eye view approach, which is generally applied for this application and thus saves the extensive pre-processing required. After studying the numerous networks and approaches used to solve this approach, we have implemented a novel model with the intention to inculcate their advantages and avoid their shortcomings. The output is predictions about the location and orientation of objects in the scene in form of 3D bounding boxes and labels of scene objects.
Shaping Political Discourse using multi-source News Summarization
Dec 18, 2023Multi-document summarization is the process of automatically generating a concise summary of multiple documents related to the same topic. This summary can help users quickly understand the key information from a large collection of documents. Multi-document summarization systems are more complex than single-document summarization systems due to the need to identify and combine information from multiple sources. In this paper, we have developed a machine learning model that generates a concise summary of a topic from multiple news documents. The model is designed to be unbiased by sampling its input equally from all the different aspects of the topic, even if the majority of the news sources lean one way.
Hybrid Internal Model: A Simple and Efficient Learner for Agile Legged Locomotion
Dec 21, 2023Robust locomotion control depends on accurate state estimations. However, the sensors of most legged robots can only provide partial and noisy observations, making the estimation particularly challenging, especially for external states like terrain frictions and elevation maps. Inspired by the classical Internal Model Control principle, we consider these external states as disturbances and introduce Hybrid Internal Model (HIM) to estimate them according to the response of the robot. The response, which we refer to as the hybrid internal embedding, contains the robot's explicit velocity and implicit stability representation, corresponding to two primary goals for locomotion tasks: explicitly tracking velocity and implicitly maintaining stability. We use contrastive learning to optimize the embedding to be close to the robot's successor state, in which the response is naturally embedded. HIM has several appealing benefits: It only needs the robot's proprioceptions, i.e., those from joint encoders and IMU as observations. It innovatively maintains consistent observations between simulation reference and reality that avoids information loss in mimicking learning. It exploits batch-level information that is more robust to noises and keeps better sample efficiency. It only requires 1 hour of training on an RTX 4090 to enable a quadruped robot to traverse any terrain under any disturbances. A wealth of real-world experiments demonstrates its agility, even in high-difficulty tasks and cases never occurred during the training process, revealing remarkable open-world generalizability.
Age of Actuation and Timeliness: Semantics in a Wireless Power Transfer System
Dec 21, 2023In this paper, we investigate a model relevant to semantics-aware goal-oriented communications, and we propose a new metric that incorporates the utilization of information in addition to its timelines. Specifically, we consider the transmission of observations from an external process to a battery-powered receiver through status updates. These updates inform the receiver about the process status and enable actuation if sufficient energy is available to achieve a goal. We focus on a wireless power transfer (WPT) model, where the receiver receives energy from a dedicated power transmitter and occasionally from the data transmitter when they share a common channel. We analyze the Age of Information (AoI) and propose a new metric, the \textit{Age of Actuation (AoA), which is relevant when the receiver utilizes the status updates to perform actions in a timely manner}. We provide analytical characterizations of the average AoA and the violation probability of the AoA, demonstrating that AoA generalizes AoI. Moreover, we introduce and analytically characterize the \textit{Probability of Missing Actuation (PoMA)}; this metric becomes relevant also \textit{to quantify the incurred cost of a missed action}. We formulate unconstrained and constrained optimization problems for all the metrics and present numerical evaluations of our analytical results. This proposed set of metrics goes beyond the traditional timeliness metrics since the synergy of different flows is now considered.
DyBluRF: Dynamic Deblurring Neural Radiance Fields for Blurry Monocular Video
Dec 21, 2023Video view synthesis, allowing for the creation of visually appealing frames from arbitrary viewpoints and times, offers immersive viewing experiences. Neural radiance fields, particularly NeRF, initially developed for static scenes, have spurred the creation of various methods for video view synthesis. However, the challenge for video view synthesis arises from motion blur, a consequence of object or camera movement during exposure, which hinders the precise synthesis of sharp spatio-temporal views. In response, we propose a novel dynamic deblurring NeRF framework for blurry monocular video, called DyBluRF, consisting of an Interleave Ray Refinement (IRR) stage and a Motion Decomposition-based Deblurring (MDD) stage. Our DyBluRF is the first that addresses and handles the novel view synthesis for blurry monocular video. The IRR stage jointly reconstructs dynamic 3D scenes and refines the inaccurate camera pose information to combat imprecise pose information extracted from the given blurry frames. The MDD stage is a novel incremental latent sharp-rays prediction (ILSP) approach for the blurry monocular video frames by decomposing the latent sharp rays into global camera motion and local object motion components. Extensive experimental results demonstrate that our DyBluRF outperforms qualitatively and quantitatively the very recent state-of-the-art methods. Our project page including source codes and pretrained model are publicly available at https://kaist-viclab.github.io/dyblurf-site/.
SAMSGL: Series-Aligned Multi-Scale Graph Learning for Spatio-Temporal Forecasting
Dec 26, 2023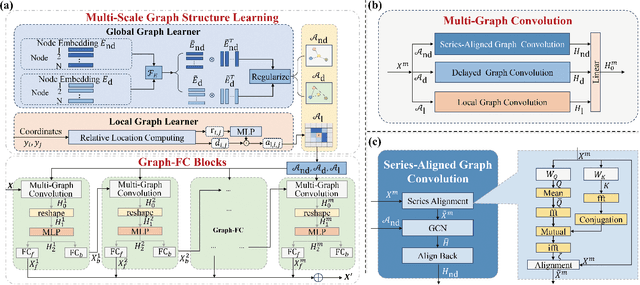

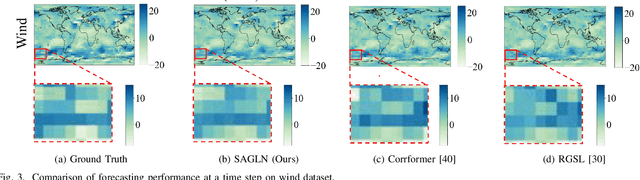
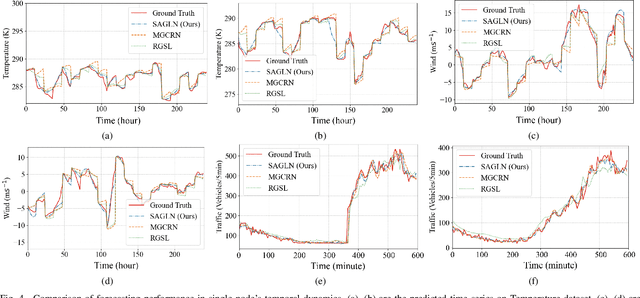
Spatio-temporal forecasting in various domains, like traffic prediction and weather forecasting, is a challenging endeavor, primarily due to the difficulties in modeling propagation dynamics and capturing high-dimensional interactions among nodes. Despite the significant strides made by graph-based networks in spatio-temporal forecasting, there remain two pivotal factors closely related to forecasting performance that need further consideration: time delays in propagation dynamics and multi-scale high-dimensional interactions. In this work, we present a Series-Aligned Multi-Scale Graph Learning (SAMSGL) framework, aiming to enhance forecasting performance. In order to handle time delays in spatial interactions, we propose a series-aligned graph convolution layer to facilitate the aggregation of non-delayed graph signals, thereby mitigating the influence of time delays for the improvement in accuracy. To understand global and local spatio-temporal interactions, we develop a spatio-temporal architecture via multi-scale graph learning, which encompasses two essential components: multi-scale graph structure learning and graph-fully connected (Graph-FC) blocks. The multi-scale graph structure learning includes a global graph structure to learn both delayed and non-delayed node embeddings, as well as a local one to learn node variations influenced by neighboring factors. The Graph-FC blocks synergistically fuse spatial and temporal information to boost prediction accuracy. To evaluate the performance of SAMSGL, we conduct experiments on meteorological and traffic forecasting datasets, which demonstrate its effectiveness and superiority.