 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Agent Probabilistic Ensembles with Trajectory Sampling for Connected Autonomous Vehicles
Dec 21, 2023
Autonomous Vehicles (AVs) have attracted significant attention in recent years and Reinforcement Learning (RL) has shown remarkable performance in improving the autonomy of vehicles. In that regard, the widely adopted Model-Free RL (MFRL) promises to solve decision-making tasks in connected AVs (CAVs), contingent on the readiness of a significant amount of data samples for training. Nevertheless, it might be infeasible in practice and possibly lead to learning instability. In contrast, Model-Based RL (MBRL) manifests itself in sample-efficient learning, but the asymptotic performance of MBRL might lag behind the state-of-the-art MFRL algorithms. Furthermore, most studies for CAVs are limited to the decision-making of a single AV only, thus underscoring the performance due to the absence of communications. In this study, we try to address the decision-making problem of multiple CAVs with limited communications and propose a decentralized Multi-Agent Probabilistic Ensembles with Trajectory Sampling algorithm MA-PETS. In particular, in order to better capture the uncertainty of the unknown environment, MA-PETS leverages Probabilistic Ensemble (PE) neural networks to learn from communicated samples among neighboring CAVs. Afterwards, MA-PETS capably develops Trajectory Sampling (TS)-based model-predictive control for decision-making. On this basis, we derive the multi-agent group regret bound affected by the number of agents within the communication range and mathematically validate that incorporating effective information exchange among agents into the multi-agent learning scheme contributes to reducing the group regret bound in the worst case. Finally, we empirically demonstrate the superiority of MA-PETS in terms of the sample efficiency comparable to MFBL.
LLM4VG: Large Language Models Evaluation for Video Grounding
Dec 21, 2023Recently, researchers have attempted to investigate the capability of LLMs in handling videos and proposed several video LLM models. However, the ability of LLMs to handle video grounding (VG), which is an important time-related video task requiring the model to precisely locate the start and end timestamps of temporal moments in videos that match the given textual queries, still remains unclear and unexplored in literature. To fill the gap, in this paper, we propose the LLM4VG benchmark, which systematically evaluates the performance of different LLMs on video grounding tasks. Based on our proposed LLM4VG, we design extensive experiments to examine two groups of video LLM models on video grounding: (i) the video LLMs trained on the text-video pairs (denoted as VidLLM), and (ii) the LLMs combined with pretrained visual description models such as the video/image captioning model. We propose prompt methods to integrate the instruction of VG and description from different kinds of generators, including caption-based generators for direct visual description and VQA-based generators for information enhancement. We also provide comprehensive comparisons of various VidLLMs and explore the influence of different choices of visual models, LLMs, prompt designs, etc, as well. Our experimental evaluations lead to two conclusions: (i) the existing VidLLMs are still far away from achieving satisfactory video grounding performance, and more time-related video tasks should be included to further fine-tune these models, and (ii) the combination of LLMs and visual models shows preliminary abilities for video grounding with considerable potential for improvement by resorting to more reliable models and further guidance of prompt instructions.
ProvFL: Client-Driven Interpretability of Global Model Predictions in Federated Learning
Dec 21, 2023Federated Learning (FL) trains a collaborative machine learning model by aggregating multiple privately trained clients' models over several training rounds. Such a long, continuous action of model aggregations poses significant challenges in reasoning about the origin and composition of such a global model. Regardless of the quality of the global model or if it has a fault, understanding the model's origin is equally important for debugging, interpretability, and explainability in federated learning. FL application developers often question: (1) what clients contributed towards a global model and (2) if a global model predicts a label, which clients are responsible for it? We introduce, neuron provenance, a fine-grained lineage capturing mechanism that tracks the flow of information between the individual participating clients in FL and the final global model. We operationalize this concept in ProvFL that functions on two key principles. First, recognizing that monitoring every neuron of every client's model statically is ineffective and noisy due to the uninterpretable nature of individual neurons, ProvFL dynamically isolates influential and sensitive neurons in the global model, significantly reducing the search space. Second, as multiple clients' models are fused in each round to form a global model, tracking each client's contribution becomes challenging. ProvFL leverages the invertible nature of fusion algorithms to precisely isolate each client's contribution derived from selected neurons. When asked to localize the clients responsible for the given behavior (i.e., prediction) of the global model, ProvFL successfully localizes them with an average provenance accuracy of 97%. Additionally, ProvFL outperforms the state-of-the-art FL fault localization approach by an average margin of 50%.
Energy Efficiency Maximization for Intelligent Surfaces Aided Massive MIMO with Zero
Dec 21, 2023In this work, we address the energy efficiency (EE) maximization problem in a downlink communication system utilizing reconfigurable intelligent surface (RIS) in a multi-user massive multiple-input multiple-output (mMIMO) setup with zero-forcing (ZF) precoding. The channel between the base station (BS) and RIS operates under a Rician fading with Rician factor K1. Since systematically optimizing the RIS phase shifts in each channel coherence time interval is challenging and burdensome, we employ the statistical channel state information (CSI)-based optimization strategy to alleviate this overhead. By treating the RIS phase shifts matrix as a constant over multiple channel coherence time intervals, we can reduce the computational complexity while maintaining an interesting performance. Based on an ergodic rate (ER) lower bound closed-form, the EE optimization problem is formulated. Such a problem is non-convex and challenging to tackle due to the coupled variables. To circumvent such an obstacle, we explore the sequential optimization approach where the power allocation vector p, the number of antennas M, and the RIS phase shifts v are separated and sequentially solved iteratively until convergence. With the help of the Lagrangian dual method, fractional programming (FP) techniques, and Lemma 1, insightful compact closed-form expressions for each of the three optimization variables are derived. Simulation results validate the effectiveness of the proposed method across different generalized channel scenarios, including non-line-of-sight (NLoS) and partially line-of-sight (LoS) conditions. This underscores its potential to significantly reduce power consumption, decrease the number of active antennas at the base station, and effectively incorporate RIS structure in mMIMO communication setup with just statistical CSI knowledge.
PaperQA: Retrieval-Augmented Generative Agent for Scientific Research
Dec 14, 2023Large Language Models (LLMs) generalize well across language tasks, but suffer from hallucinations and uninterpretability, making it difficult to assess their accuracy without ground-truth. Retrieval-Augmented Generation (RAG) models have been proposed to reduce hallucinations and provide provenance for how an answer was generated. Applying such models to the scientific literature may enable large-scale, systematic processing of scientific knowledge. We present PaperQA, a RAG agent for answering questions over the scientific literature. PaperQA is an agent that performs information retrieval across full-text scientific articles, assesses the relevance of sources and passages, and uses RAG to provide answers. Viewing this agent as a question answering model, we find it exceeds performance of existing LLMs and LLM agents on current science QA benchmarks. To push the field closer to how humans perform research on scientific literature, we also introduce LitQA, a more complex benchmark that requires retrieval and synthesis of information from full-text scientific papers across the literature. Finally, we demonstrate PaperQA's matches expert human researchers on LitQA.
EmbAu: A Novel Technique to Embed Audio Data Using Shuffled Frog Leaping Algorithm
Dec 13, 2023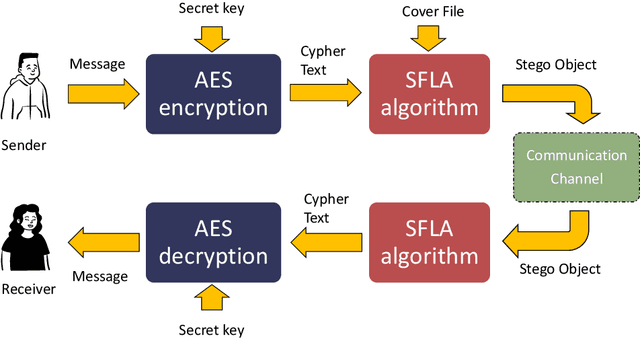



The aim of steganographic algorithms is to identify the appropriate pixel positions in the host or cover image, where bits of sensitive information can be concealed for data encryption. Work is being done to improve the capacity to integrate sensitive information and to maintain the visual appearance of the steganographic image. Consequently, steganography is a challenging research area. In our currently proposed image steganographic technique, we used the Shuffled Frog Leaping Algorithm (SFLA) to determine the order of pixels by which sensitive information can be placed in the cover image. To achieve greater embedding capacity, pixels from the spatial domain of the cover image are carefully chosen and used for placing the sensitive data. Bolstered via image steganography, the final image after embedding is resistant to steganalytic attacks. The SFLA algorithm serves in the optimal pixels selection of any colored (RGB) cover image for secret bit embedding. Using the fitness function, the SFLA benefits by reaching a minimum cost value in an acceptable amount of time. The pixels for embedding are meticulously chosen to minimize the host image's distortion upon embedding. Moreover, an effort has been taken to make the detection of embedded data in the steganographic image a formidable challenge. Due to the enormous need for audio data encryption in the current world, we feel that our suggested method has significant potential in real-world applications. In this paper, we propose and compare our strategy to existing steganographic methods.
RealGen: Retrieval Augmented Generation for Controllable Traffic Scenarios
Dec 19, 2023Simulation plays a crucial role in the development of autonomous vehicles (AVs) due to the potential risks associated with real-world testing. Although significant progress has been made in the visual aspects of simulators, generating complex behavior among agents remains a formidable challenge. It is not only imperative to ensure realism in the scenarios generated but also essential to incorporate preferences and conditions to facilitate controllable generation for AV training and evaluation. Traditional methods, mainly relying on memorizing the distribution of training datasets, often fall short in generating unseen scenarios. Inspired by the success of retrieval augmented generation in large language models, we present RealGen, a novel retrieval-based in-context learning framework for traffic scenario generation. RealGen synthesizes new scenarios by combining behaviors from multiple retrieved examples in a gradient-free way, which may originate from templates or tagged scenarios. This in-context learning framework endows versatile generative capabilities, including the ability to edit scenarios, compose various behaviors, and produce critical scenarios. Evaluations show that RealGen offers considerable flexibility and controllability, marking a new direction in the field of controllable traffic scenario generation. Check our project website for more information: https://realgen.github.io.
Geo-located Aspect Based Sentiment Analysis (ABSA) for Crowdsourced Evaluation of Urban Environments
Dec 19, 2023Sentiment analysis methods are rapidly being adopted by the field of Urban Design and Planning, for the crowdsourced evaluation of urban environments. However, most models used within this domain are able to identify positive or negative sentiment associated with a textual appraisal as a whole, without inferring information about specific urban aspects contained within it, or the sentiment associated with them. While Aspect Based Sentiment Analysis (ABSA) is becoming increasingly popular, most existing ABSA models are trained on non-urban themes such as restaurants, electronics, consumer goods and the like. This body of research develops an ABSA model capable of extracting urban aspects contained within geo-located textual urban appraisals, along with corresponding aspect sentiment classification. We annotate a dataset of 2500 crowdsourced reviews of public parks, and train a Bidirectional Encoder Representations from Transformers (BERT) model with Local Context Focus (LCF) on this data. Our model achieves significant improvement in prediction accuracy on urban reviews, for both Aspect Term Extraction (ATE) and Aspect Sentiment Classification (ASC) tasks. For demonstrative analysis, positive and negative urban aspects across Boston are spatially visualized. We hope that this model is useful for designers and planners for fine-grained urban sentiment evaluation.
DSAF: A Dual-Stage Adaptive Framework for Numerical Weather Prediction Downscaling
Dec 19, 2023While widely recognized as one of the most substantial weather forecasting methodologies, Numerical Weather Prediction (NWP) usually suffers from relatively coarse resolution and inevitable bias due to tempo-spatial discretization, physical parametrization process, and computation limitation. With the roaring growth of deep learning-based techniques, we propose the Dual-Stage Adaptive Framework (DSAF), a novel framework to address regional NWP downscaling and bias correction tasks. DSAF uniquely incorporates adaptive elements in its design to ensure a flexible response to evolving weather conditions. Specifically, NWP downscaling and correction are well-decoupled in the framework and can be applied independently, which strategically guides the optimization trajectory of the model. Utilizing a multi-task learning mechanism and an uncertainty-weighted loss function, DSAF facilitates balanced training across various weather factors. Additionally, our specifically designed attention-centric learnable module effectively integrates geographic information, proficiently managing complex interrelationships. Experimental validation on the ECMWF operational forecast (HRES) and reanalysis (ERA5) archive demonstrates DSAF's superior performance over existing state-of-the-art models and shows substantial improvements when existing models are augmented using our proposed modules. Code is publicly available at https://github.com/pengwei07/DSAF.
Hierarchical and Incremental Structural Entropy Minimization for Unsupervised Social Event Detection
Dec 19, 2023As a trending approach for social event detection, graph neural network (GNN)-based methods enable a fusion of natural language semantics and the complex social network structural information, thus showing SOTA performance. However, GNN-based methods can miss useful message correlations. Moreover, they require manual labeling for training and predetermining the number of events for prediction. In this work, we address social event detection via graph structural entropy (SE) minimization. While keeping the merits of the GNN-based methods, the proposed framework, HISEvent, constructs more informative message graphs, is unsupervised, and does not require the number of events given a priori. Specifically, we incrementally explore the graph neighborhoods using 1-dimensional (1D) SE minimization to supplement the existing message graph with edges between semantically related messages. We then detect events from the message graph by hierarchically minimizing 2-dimensional (2D) SE. Our proposed 1D and 2D SE minimization algorithms are customized for social event detection and effectively tackle the efficiency problem of the existing SE minimization algorithms. Extensive experiments show that HISEvent consistently outperforms GNN-based methods and achieves the new SOTA for social event detection under both closed- and open-set settings while being efficient and robust.