 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Effective Paraphrasing for Information Disguise
Nov 08, 2023
Information Disguise (ID), a part of computational ethics in Natural Language Processing (NLP), is concerned with best practices of textual paraphrasing to prevent the non-consensual use of authors' posts on the Internet. Research on ID becomes important when authors' written online communication pertains to sensitive domains, e.g., mental health. Over time, researchers have utilized AI-based automated word spinners (e.g., SpinRewriter, WordAI) for paraphrasing content. However, these tools fail to satisfy the purpose of ID as their paraphrased content still leads to the source when queried on search engines. There is limited prior work on judging the effectiveness of paraphrasing methods for ID on search engines or their proxies, neural retriever (NeurIR) models. We propose a framework where, for a given sentence from an author's post, we perform iterative perturbation on the sentence in the direction of paraphrasing with an attempt to confuse the search mechanism of a NeurIR system when the sentence is queried on it. Our experiments involve the subreddit 'r/AmItheAsshole' as the source of public content and Dense Passage Retriever as a NeurIR system-based proxy for search engines. Our work introduces a novel method of phrase-importance rankings using perplexity scores and involves multi-level phrase substitutions via beam search. Our multi-phrase substitution scheme succeeds in disguising sentences 82% of the time and hence takes an essential step towards enabling researchers to disguise sensitive content effectively before making it public. We also release the code of our approach.
* Accepted at ECIR 2023
Dual Branch Network Towards Accurate Printed Mathematical Expression Recognition
Dec 14, 2023Over the past years, Printed Mathematical Expression Recognition (PMER) has progressed rapidly. However, due to the insufficient context information captured by Convolutional Neural Networks, some mathematical symbols might be incorrectly recognized or missed. To tackle this problem, in this paper, a Dual Branch transformer-based Network (DBN) is proposed to learn both local and global context information for accurate PMER. In our DBN, local and global features are extracted simultaneously, and a Context Coupling Module (CCM) is developed to complement the features between the global and local contexts. CCM adopts an interactive manner so that the coupled context clues are highly correlated to each expression symbol. Additionally, we design a Dynamic Soft Target (DST) strategy to utilize the similarities among symbol categories for reasonable label generation. Our experimental results have demonstrated that DBN can accurately recognize mathematical expressions and has achieved state-of-the-art performance.
Sample-Conditioned Hypothesis Stability Sharpens Information-Theoretic Generalization Bounds
Oct 31, 2023We present new information-theoretic generalization guarantees through the a novel construction of the "neighboring-hypothesis" matrix and a new family of stability notions termed sample-conditioned hypothesis (SCH) stability. Our approach yields sharper bounds that improve upon previous information-theoretic bounds in various learning scenarios. Notably, these bounds address the limitations of existing information-theoretic bounds in the context of stochastic convex optimization (SCO) problems, as explored in the recent work by Haghifam et al. (2023).
Visual-information-driven model for crowd simulation using temporal convolutional network
Nov 06, 2023Crowd simulations play a pivotal role in building design, influencing both user experience and public safety. While traditional knowledge-driven models have their merits, data-driven crowd simulation models promise to bring a new dimension of realism to these simulations. However, most of the existing data-driven models are designed for specific geometries, leading to poor adaptability and applicability. A promising strategy for enhancing the adaptability and realism of data-driven crowd simulation models is to incorporate visual information, including the scenario geometry and pedestrian locomotion. Consequently, this paper proposes a novel visual-information-driven (VID) crowd simulation model. The VID model predicts the pedestrian velocity at the next time step based on the prior social-visual information and motion data of an individual. A radar-geometry-locomotion method is established to extract the visual information of pedestrians. Moreover, a temporal convolutional network (TCN)-based deep learning model, named social-visual TCN, is developed for velocity prediction. The VID model is tested on three public pedestrian motion datasets with distinct geometries, i.e., corridor, corner, and T-junction. Both qualitative and quantitative metrics are employed to evaluate the VID model, and the results highlight the improved adaptability of the model across all three geometric scenarios. Overall, the proposed method demonstrates effectiveness in enhancing the adaptability of data-driven crowd models.
Deep dive into language traits of AI-generated Abstracts
Dec 17, 2023Generative language models, such as ChatGPT, have garnered attention for their ability to generate human-like writing in various fields, including academic research. The rapid proliferation of generated texts has bolstered the need for automatic identification to uphold transparency and trust in the information. However, these generated texts closely resemble human writing and often have subtle differences in the grammatical structure, tones, and patterns, which makes systematic scrutinization challenging. In this work, we attempt to detect the Abstracts generated by ChatGPT, which are much shorter in length and bounded. We extract the texts semantic and lexical properties and observe that traditional machine learning models can confidently detect these Abstracts.
Research Team Identification Based on Representation Learning of Academic Heterogeneous Information Network
Nov 02, 2023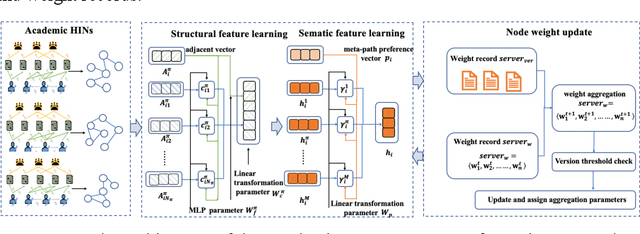
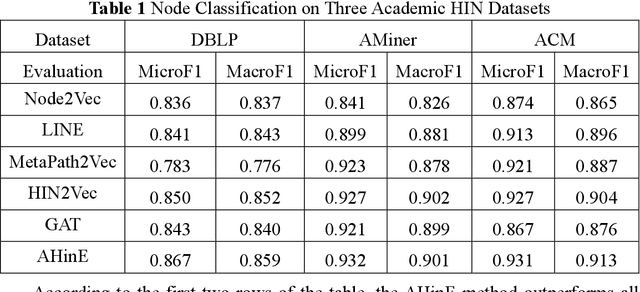

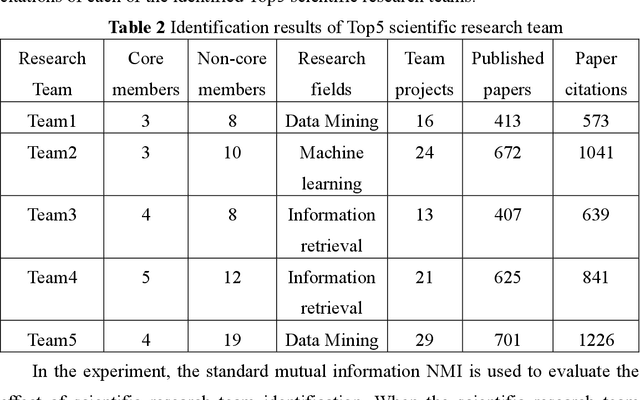
Academic networks in the real world can usually be described by heterogeneous information networks composed of multi-type nodes and relationships. Some existing research on representation learning for homogeneous information networks lacks the ability to explore heterogeneous information networks in heterogeneous information networks. It cannot be applied to heterogeneous information networks. Aiming at the practical needs of effectively identifying and discovering scientific research teams from the academic heterogeneous information network composed of massive and complex scientific and technological big data, this paper proposes a scientific research team identification method based on representation learning of academic heterogeneous information networks. The attention mechanism at node level and meta-path level learns low-dimensional, dense and real-valued vector representations on the basis of retaining the rich topological information of nodes in the network and the semantic information based on meta-paths, and realizes effective identification and discovery of scientific research teams and important team members in academic heterogeneous information networks based on maximizing node influence. Experimental results show that our proposed method outperforms the comparative methods.
No prejudice! Fair Federated Graph Neural Networks for Personalized Recommendation
Dec 20, 2023Ensuring fairness in Recommendation Systems (RSs) across demographic groups is critical due to the increased integration of RSs in applications such as personalized healthcare, finance, and e-commerce. Graph-based RSs play a crucial role in capturing intricate higher-order interactions among entities. However, integrating these graph models into the Federated Learning (FL) paradigm with fairness constraints poses formidable challenges as this requires access to the entire interaction graph and sensitive user information (such as gender, age, etc.) at the central server. This paper addresses the pervasive issue of inherent bias within RSs for different demographic groups without compromising the privacy of sensitive user attributes in FL environment with the graph-based model. To address the group bias, we propose F2PGNN (Fair Federated Personalized Graph Neural Network), a novel framework that leverages the power of Personalized Graph Neural Network (GNN) coupled with fairness considerations. Additionally, we use differential privacy techniques to fortify privacy protection. Experimental evaluation on three publicly available datasets showcases the efficacy of F2PGNN in mitigating group unfairness by 47% - 99% compared to the state-of-the-art while preserving privacy and maintaining the utility. The results validate the significance of our framework in achieving equitable and personalized recommendations using GNN within the FL landscape.
Pixel-to-Abundance Translation: Conditional Generative Adversarial Networks Based on Patch Transformer for Hyperspectral Unmixing
Dec 20, 2023Spectral unmixing is a significant challenge in hyperspectral image processing. Existing unmixing methods utilize prior knowledge about the abundance distribution to solve the regularization optimization problem, where the difficulty lies in choosing appropriate prior knowledge and solving the complex regularization optimization problem. To solve these problems, we propose a hyperspectral conditional generative adversarial network (HyperGAN) method as a generic unmixing framework, based on the following assumption: the unmixing process from pixel to abundance can be regarded as a transformation of two modalities with an internal specific relationship. The proposed HyperGAN is composed of a generator and discriminator, the former completes the modal conversion from mixed hyperspectral pixel patch to the abundance of corresponding endmember of the central pixel and the latter is used to distinguish whether the distribution and structure of generated abundance are the same as the true ones. We propose hyperspectral image (HSI) Patch Transformer as the main component of the generator, which utilize adaptive attention score to capture the internal pixels correlation of the HSI patch and leverage the spatial-spectral information in a fine-grained way to achieve optimization of the unmixing process. Experiments on synthetic data and real hyperspectral data achieve impressive results compared to state-of-the-art competitors.
BEVSeg2TP: Surround View Camera Bird's-Eye-View Based Joint Vehicle Segmentation and Ego Vehicle Trajectory Prediction
Dec 20, 2023Trajectory prediction is, naturally, a key task for vehicle autonomy. While the number of traffic rules is limited, the combinations and uncertainties associated with each agent's behaviour in real-world scenarios are nearly impossible to encode. Consequently, there is a growing interest in learning-based trajectory prediction. The proposed method in this paper predicts trajectories by considering perception and trajectory prediction as a unified system. In considering them as unified tasks, we show that there is the potential to improve the performance of perception. To achieve these goals, we present BEVSeg2TP - a surround-view camera bird's-eye-view-based joint vehicle segmentation and ego vehicle trajectory prediction system for autonomous vehicles. The proposed system uses a network trained on multiple camera views. The images are transformed using several deep learning techniques to perform semantic segmentation of objects, including other vehicles, in the scene. The segmentation outputs are fused across the camera views to obtain a comprehensive representation of the surrounding vehicles from the bird's-eye-view perspective. The system further predicts the future trajectory of the ego vehicle using a spatiotemporal probabilistic network (STPN) to optimize trajectory prediction. This network leverages information from encoder-decoder transformers and joint vehicle segmentation.
Doubly Perturbed Task-Free Continual Learning
Dec 20, 2023Task-free online continual learning (TF-CL) is a challenging problem where the model incrementally learns tasks without explicit task information. Although training with entire data from the past, present as well as future is considered as the gold standard, naive approaches in TF-CL with the current samples may be conflicted with learning with samples in the future, leading to catastrophic forgetting and poor plasticity. Thus, a proactive consideration of an unseen future sample in TF-CL becomes imperative. Motivated by this intuition, we propose a novel TF-CL framework considering future samples and show that injecting adversarial perturbations on both input data and decision-making is effective. Then, we propose a novel method named Doubly Perturbed Continual Learning (DPCL) to efficiently implement these input and decision-making perturbations. Specifically, for input perturbation, we propose an approximate perturbation method that injects noise into the input data as well as the feature vector and then interpolates the two perturbed samples. For decision-making process perturbation, we devise multiple stochastic classifiers. We also investigate a memory management scheme and learning rate scheduling reflecting our proposed double perturbations. We demonstrate that our proposed method outperforms the state-of-the-art baseline methods by large margins on various TF-CL benchmarks.