 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Point Deformable Network with Enhanced Normal Embedding for Point Cloud Analysis
Dec 20, 2023
Recently MLP-based methods have shown strong performance in point cloud analysis. Simple MLP architectures are able to learn geometric features in local point groups yet fail to model long-range dependencies directly. In this paper, we propose Point Deformable Network (PDNet), a concise MLP-based network that can capture long-range relations with strong representation ability. Specifically, we put forward Point Deformable Aggregation Module (PDAM) to improve representation capability in both long-range dependency and adaptive aggregation among points. For each query point, PDAM aggregates information from deformable reference points rather than points in limited local areas. The deformable reference points are generated data-dependent, and we initialize them according to the input point positions. Additional offsets and modulation scalars are learned on the whole point features, which shift the deformable reference points to the regions of interest. We also suggest estimating the normal vector for point clouds and applying Enhanced Normal Embedding (ENE) to the geometric extractors to improve the representation ability of single-point. Extensive experiments and ablation studies on various benchmarks demonstrate the effectiveness and superiority of our PDNet.
Bayesian Transfer Learning
Dec 20, 2023Transfer learning is a burgeoning concept in statistical machine learning that seeks to improve inference and/or predictive accuracy on a domain of interest by leveraging data from related domains. While the term "transfer learning" has garnered much recent interest, its foundational principles have existed for years under various guises. Prior literature reviews in computer science and electrical engineering have sought to bring these ideas into focus, primarily surveying general methodologies and works from these disciplines. This article highlights Bayesian approaches to transfer learning, which have received relatively limited attention despite their innate compatibility with the notion of drawing upon prior knowledge to guide new learning tasks. Our survey encompasses a wide range of Bayesian transfer learning frameworks applicable to a variety of practical settings. We discuss how these methods address the problem of finding the optimal information to transfer between domains, which is a central question in transfer learning. We illustrate the utility of Bayesian transfer learning methods via a simulation study where we compare performance against frequentist competitors.
SLP-Net:An efficient lightweight network for segmentation of skin lesions
Dec 20, 2023Prompt treatment for melanoma is crucial. To assist physicians in identifying lesion areas precisely in a quick manner, we propose a novel skin lesion segmentation technique namely SLP-Net, an ultra-lightweight segmentation network based on the spiking neural P(SNP) systems type mechanism. Most existing convolutional neural networks achieve high segmentation accuracy while neglecting the high hardware cost. SLP-Net, on the contrary, has a very small number of parameters and a high computation speed. We design a lightweight multi-scale feature extractor without the usual encoder-decoder structure. Rather than a decoder, a feature adaptation module is designed to replace it and implement multi-scale information decoding. Experiments at the ISIC2018 challenge demonstrate that the proposed model has the highest Acc and DSC among the state-of-the-art methods, while experiments on the PH2 dataset also demonstrate a favorable generalization ability. Finally, we compare the computational complexity as well as the computational speed of the models in experiments, where SLP-Net has the highest overall superiority
Predicting urban tree cover from incomplete point labels and limited background information
Nov 20, 2023Trees inside cities are important for the urban microclimate, contributing positively to the physical and mental health of the urban dwellers. Despite their importance, often only limited information about city trees is available. Therefore in this paper, we propose a method for mapping urban trees in high-resolution aerial imagery using limited datasets and deep learning. Deep learning has become best-practice for this task, however, existing approaches rely on large and accurately labelled training datasets, which can be difficult and expensive to obtain. However, often noisy and incomplete data may be available that can be combined and utilized to solve more difficult tasks than those datasets were intended for. This paper studies how to combine accurate point labels of urban trees along streets with crowd-sourced annotations from an open geographic database to delineate city trees in remote sensing images, a task which is challenging even for humans. To that end, we perform semantic segmentation of very high resolution aerial imagery using a fully convolutional neural network. The main challenge is that our segmentation maps are sparsely annotated and incomplete. Small areas around the point labels of the street trees coming from official and crowd-sourced data are marked as foreground class. Crowd-sourced annotations of streets, buildings, etc. define the background class. Since the tree data is incomplete, we introduce a masking to avoid class confusion. Our experiments in Hamburg, Germany, showed that the system is able to produce tree cover maps, not limited to trees along streets, without providing tree delineations. We evaluated the method on manually labelled trees and show that performance drastically deteriorates if the open geographic database is not used.
Incorporating sufficient physical information into artificial neural networks: a guaranteed improvement via physics-based Rao-Blackwellization
Nov 10, 2023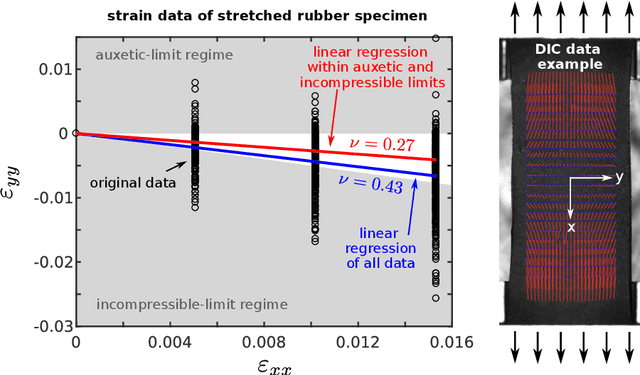
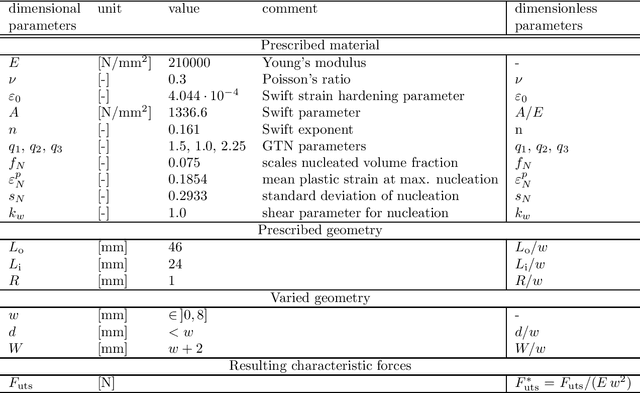
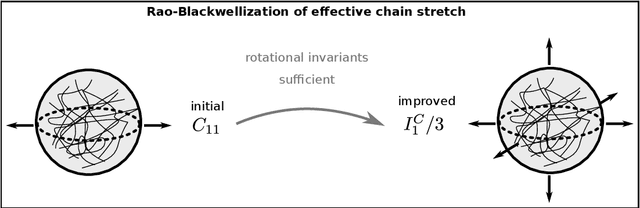
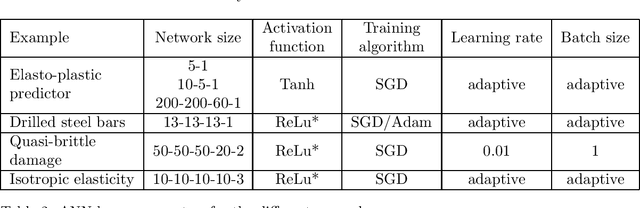
The concept of Rao-Blackwellization is employed to improve predictions of artificial neural networks by physical information. The error norm and the proof of improvement are transferred from the original statistical concept to a deterministic one, using sufficient information on physics-based conditions. The proposed strategy is applied to material modeling and illustrated by examples of the identification of a yield function, elasto-plastic steel simulations, the identification of driving forces for quasi-brittle damage and rubber experiments. Sufficient physical information is employed, e.g., in the form of invariants, parameters of a minimization problem, dimensional analysis, isotropy and differentiability. It is proven how intuitive accretion of information can yield improvement if it is physically sufficient, but also how insufficient or superfluous information can cause impairment. Opportunities for the improvement of artificial neural networks are explored in terms of the training data set, the networks' structure and output filters. Even crude initial predictions are remarkably improved by reducing noise, overfitting and data requirements.
Hourglass-AVSR: Down-Up Sampling-based Computational Efficiency Model for Audio-Visual Speech Recognition
Dec 14, 2023Recently audio-visual speech recognition (AVSR), which better leverages video modality as additional information to extend automatic speech recognition (ASR), has shown promising results in complex acoustic environments. However, there is still substantial space to improve as complex computation of visual modules and ineffective fusion of audio-visual modalities. To eliminate these drawbacks, we propose a down-up sampling-based AVSR model (Hourglass-AVSR) to enjoy high efficiency and performance, whose time length is scaled during the intermediate processing, resembling an hourglass. Firstly, we propose a context and residual aware video upsampling approach to improve the recognition performance, which utilizes contextual information from visual representations and captures residual information between adjacent video frames. Secondly, we introduce a visual-audio alignment approach during the upsampling by explicitly incorporating boundary constraint loss. Besides, we propose a cross-layer attention fusion to capture the modality dependencies within each visual encoder layer. Experiments conducted on the MISP-AVSR dataset reveal that our proposed Hourglass-AVSR model outperforms ASR model by 12.9% and 20.8% relative concatenated minimum permutation character error rate (cpCER) reduction on far-field and middle-field test sets, respectively. Moreover, compared to other state-of-the-art AVSR models, our model exhibits the highest improvement in cpCER for the visual module. Furthermore, on the benefit of our down-up sampling approach, Hourglass-AVSR model reduces 54.2% overall computation costs with minor performance degradation.
GIELLM: Japanese General Information Extraction Large Language Model Utilizing Mutual Reinforcement Effect
Nov 12, 2023Information Extraction (IE) stands as a cornerstone in natural language processing, traditionally segmented into distinct sub-tasks. The advent of Large Language Models (LLMs) heralds a paradigm shift, suggesting the feasibility of a singular model addressing multiple IE subtasks. In this vein, we introduce the General Information Extraction Large Language Model (GIELLM), which integrates text Classification, Sentiment Analysis, Named Entity Recognition, Relation Extraction, and Event Extraction using a uniform input-output schema. This innovation marks the first instance of a model simultaneously handling such a diverse array of IE subtasks. Notably, the GIELLM leverages the Mutual Reinforcement Effect (MRE), enhancing performance in integrated tasks compared to their isolated counterparts. Our experiments demonstrate State-of-the-Art (SOTA) results in five out of six Japanese mixed datasets, significantly surpassing GPT-3.5-Turbo. Further, an independent evaluation using the novel Text Classification Relation and Event Extraction(TCREE) dataset corroborates the synergistic advantages of MRE in text and word classification. This breakthrough paves the way for most IE subtasks to be subsumed under a singular LLM framework. Specialized fine-tune task-specific models are no longer needed.
Turbo: Informativity-Driven Acceleration Plug-In for Vision-Language Models
Dec 12, 2023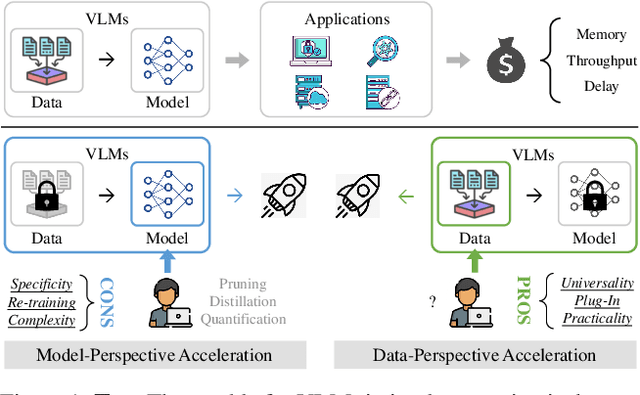
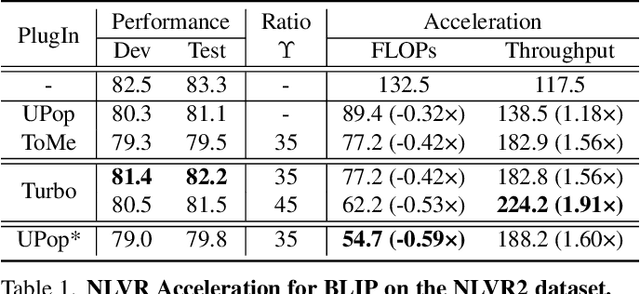
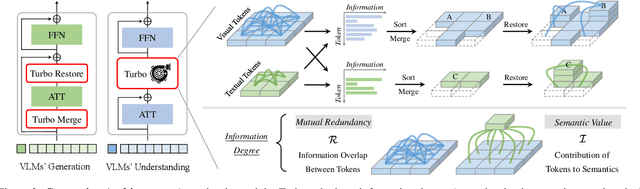
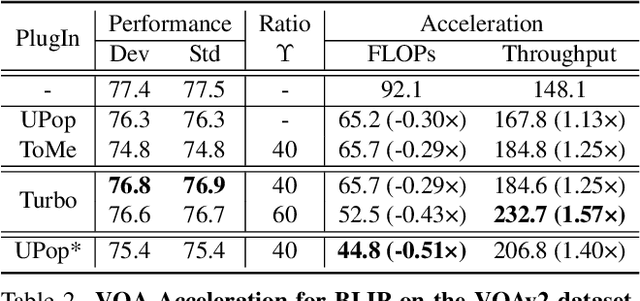
Vision-Language Large Models (VLMs) have become primary backbone of AI, due to the impressive performance. However, their expensive computation costs, i.e., throughput and delay, impede potentials in real-world scenarios. To achieve acceleration for VLMs, most existing methods focus on the model perspective: pruning, distillation, quantification, but completely overlook the data-perspective redundancy. To fill the overlook, this paper pioneers the severity of data redundancy, and designs one plug-and-play Turbo module guided by information degree to prune inefficient tokens from visual or textual data. In pursuit of efficiency-performance trade-offs, information degree takes two key factors into consideration: mutual redundancy and semantic value. Concretely, the former evaluates the data duplication between sequential tokens; while the latter evaluates each token by its contribution to the overall semantics. As a result, tokens with high information degree carry less redundancy and stronger semantics. For VLMs' calculation, Turbo works as a user-friendly plug-in that sorts data referring to information degree, utilizing only top-level ones to save costs. Its advantages are multifaceted, e.g., being generally compatible to various VLMs across understanding and generation, simple use without retraining and trivial engineering efforts. On multiple public VLMs benchmarks, we conduct extensive experiments to reveal the gratifying acceleration of Turbo, under negligible performance drop.
Towards Information Theory-Based Discovery of Equivariances
Oct 25, 2023The presence of symmetries imposes a stringent set of constraints on a system. This constrained structure allows intelligent agents interacting with such a system to drastically improve the efficiency of learning and generalization, through the internalisation of the system's symmetries into their information-processing. In parallel, principled models of complexity-constrained learning and behaviour make increasing use of information-theoretic methods. Here, we wish to marry these two perspectives and understand whether and in which form the information-theoretic lens can "see" the effect of symmetries of a system. For this purpose, we propose a novel variant of the Information Bottleneck principle, which has served as a productive basis for many principled studies of learning and information-constrained adaptive behaviour. We show (in the discrete case) that our approach formalises a certain duality between symmetry and information parsimony: namely, channel equivariances can be characterised by the optimal mutual information-preserving joint compression of the channel's input and output. This information-theoretic treatment furthermore suggests a principled notion of "soft" equivariance, whose "coarseness" is measured by the amount of input-output mutual information preserved by the corresponding optimal compression. This new notion offers a bridge between the field of bounded rationality and the study of symmetries in neural representations. The framework may also allow (exact and soft) equivariances to be automatically discovered.
PhysRFANet: Physics-Guided Neural Network for Real-Time Prediction of Thermal Effect During Radiofrequency Ablation Treatment
Dec 21, 2023Radiofrequency ablation (RFA) is a widely used minimally invasive technique for ablating solid tumors. Achieving precise personalized treatment necessitates feedback information on in situ thermal effects induced by the RFA procedure. While computer simulation facilitates the prediction of electrical and thermal phenomena associated with RFA, its practical implementation in clinical settings is hindered by high computational demands. In this paper, we propose a physics-guided neural network model, named PhysRFANet, to enable real-time prediction of thermal effect during RFA treatment. The networks, designed for predicting temperature distribution and the corresponding ablation lesion, were trained using biophysical computational models that integrated electrostatics, bio-heat transfer, and cell necrosis, alongside magnetic resonance (MR) images of breast cancer patients. Validation of the computational model was performed through experiments on ex vivo bovine liver tissue. Our model demonstrated a 96% Dice score in predicting the lesion volume and an RMSE of 0.4854 for temperature distribution when tested with foreseen tumor images. Notably, even with unforeseen images, it achieved a 93% Dice score for the ablation lesion and an RMSE of 0.6783 for temperature distribution. All networks were capable of inferring results within 10 ms. The presented technique, applied to optimize the placement of the electrode for a specific target region, holds significant promise in enhancing the safety and efficacy of RFA treatments.