 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
2D-Guided 3D Gaussian Segmentation
Dec 26, 2023
Recently, 3D Gaussian, as an explicit 3D representation method, has demonstrated strong competitiveness over NeRF (Neural Radiance Fields) in terms of expressing complex scenes and training duration. These advantages signal a wide range of applications for 3D Gaussians in 3D understanding and editing. Meanwhile, the segmentation of 3D Gaussians is still in its infancy. The existing segmentation methods are not only cumbersome but also incapable of segmenting multiple objects simultaneously in a short amount of time. In response, this paper introduces a 3D Gaussian segmentation method implemented with 2D segmentation as supervision. This approach uses input 2D segmentation maps to guide the learning of the added 3D Gaussian semantic information, while nearest neighbor clustering and statistical filtering refine the segmentation results. Experiments show that our concise method can achieve comparable performances on mIOU and mAcc for multi-object segmentation as previous single-object segmentation methods.
Ensemble Learning to Assess Dynamics of Affective Experience Ratings and Physiological Change
Dec 26, 2023The congruence between affective experiences and physiological changes has been a debated topic for centuries. Recent technological advances in measurement and data analysis provide hope to solve this epic challenge. Open science and open data practices, together with data analysis challenges open to the academic community, are also promising tools for solving this problem. In this entry to the Emotion Physiology and Experience Collaboration (EPiC) challenge, we propose a data analysis solution that combines theoretical assumptions with data-driven methodologies. We used feature engineering and ensemble selection. Each predictor was trained on subsets of the training data that would maximize the information available for training. Late fusion was used with an averaging step. We chose to average considering a ``wisdom of crowds'' strategy. This strategy yielded an overall RMSE of 1.19 in the test set. Future work should carefully explore if our assumptions are correct and the potential of weighted fusion.
Discrete Messages Improve Communication Efficiency among Isolated Intelligent Agents
Dec 26, 2023Individuals, despite having varied life experiences and learning processes, can communicate effectively through languages. This study aims to explore the efficiency of language as a communication medium. We put forth two specific hypotheses: First, discrete messages are more effective than continuous ones when agents have diverse personal experiences. Second, communications using multiple discrete tokens are more advantageous than those using a single token. To valdate these hypotheses, we designed multi-agent machine learning experiments to assess communication efficiency using various information transmission methods between speakers and listeners. Our empirical findings indicate that, in scenarios where agents are exposed to different data, communicating through sentences composed of discrete tokens offers the best inter-agent communication efficiency. The limitations of our finding include lack of systematic advantages over other more sophisticated encoder-decoder model such as variational autoencoder and lack of evluation on non-image dataset, which we will leave for future studies.
Paralinguistics-Enhanced Large Language Modeling of Spoken Dialogue
Dec 23, 2023Large Language Models (LLMs) have demonstrated superior abilities in tasks such as chatting, reasoning, and question-answering. However, standard LLMs may ignore crucial paralinguistic information, such as sentiment, emotion, and speaking style, which are essential for achieving natural, human-like spoken conversation, especially when such information is conveyed by acoustic cues. We therefore propose Paralinguistics-enhanced Generative Pretrained Transformer (ParalinGPT), an LLM utilizes text and speech modality to better model the linguistic content and paralinguistic attribute of spoken response. The model takes the conversational context of text, speech embeddings, and paralinguistic attributes as input prompts within a serialized multitasking multi-modal framework. Specifically, our framework serializes tasks in the order of current paralinguistic attribute prediction, response paralinguistic attribute prediction, and response text generation with autoregressive conditioning. We utilize the Switchboard-1 corpus, including its sentiment labels to be the paralinguistic attribute, as our spoken dialogue dataset. Experimental results indicate the proposed serialized multitasking method outperforms typical sequence classification techniques on current and response sentiment classification. Furthermore, leveraging conversational context and speech embeddings significantly improves both response text generation and sentiment prediction. Our proposed framework achieves relative improvements of 6.7%, 12.0%, and 3.5% in current sentiment accuracy, response sentiment accuracy, and response text BLEU score, respectively.
Revealing Shadows: Low-Light Image Enhancement Using Self-Calibrated Illumination
Dec 23, 2023In digital imaging, enhancing visual content in poorly lit environments is a significant challenge, as images often suffer from inadequate brightness, hidden details, and an overall reduction in quality. This issue is especially critical in applications like nighttime surveillance, astrophotography, and low-light videography, where clear and detailed visual information is crucial. Our research addresses this problem by enhancing the illumination aspect of dark images. We have advanced past techniques by using varied color spaces to extract the illumination component, enhance it, and then recombine it with the other components of the image. By employing the Self-Calibrated Illumination (SCI) method, a strategy initially developed for RGB images, we effectively intensify and clarify details that are typically lost in low-light conditions. This method of selective illumination enhancement leaves the color information intact, thus preserving the color integrity of the image. Crucially, our method eliminates the need for paired images, making it suitable for situations where they are unavailable. Implementing the modified SCI technique represents a substantial shift from traditional methods, providing a refined and potent solution for low-light image enhancement. Our approach sets the stage for more complex image processing techniques and extends the range of possible real-world applications where accurate color representation and improved visibility are essential.
EIGEN: Expert-Informed Joint Learning Aggregation for High-Fidelity Information Extraction from Document Images
Nov 23, 2023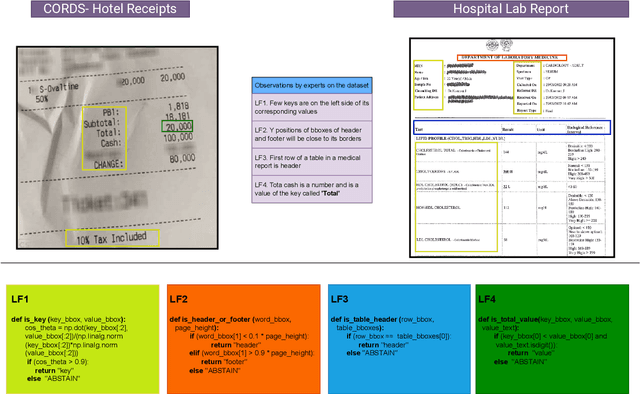
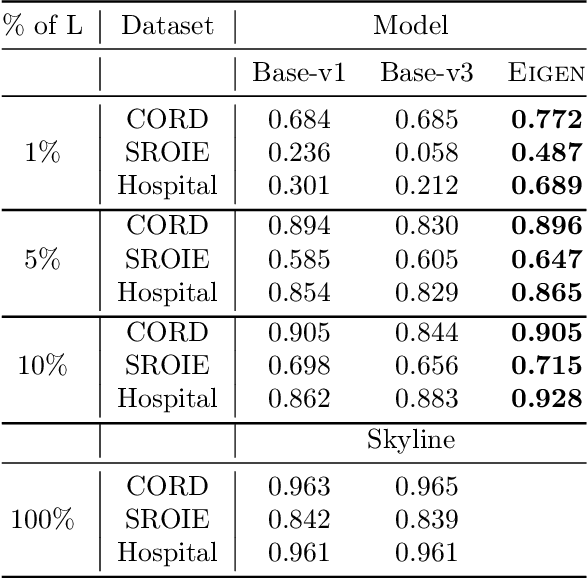
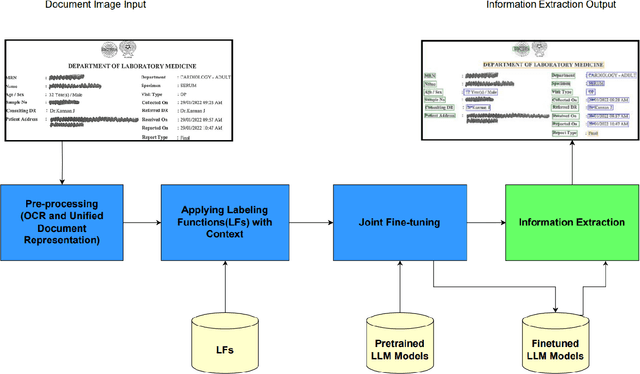
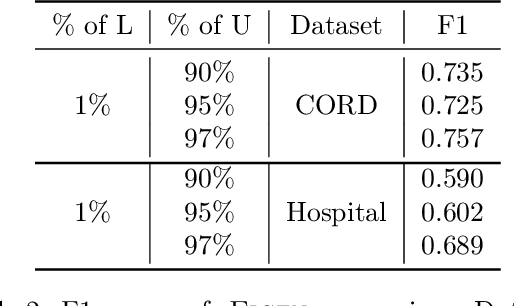
Information Extraction (IE) from document images is challenging due to the high variability of layout formats. Deep models such as LayoutLM and BROS have been proposed to address this problem and have shown promising results. However, they still require a large amount of field-level annotations for training these models. Other approaches using rule-based methods have also been proposed based on the understanding of the layout and semantics of a form such as geometric position, or type of the fields, etc. In this work, we propose a novel approach, EIGEN (Expert-Informed Joint Learning aGgrEatioN), which combines rule-based methods with deep learning models using data programming approaches to circumvent the requirement of annotation of large amounts of training data. Specifically, EIGEN consolidates weak labels induced from multiple heuristics through generative models and use them along with a small number of annotated labels to jointly train a deep model. In our framework, we propose the use of labeling functions that include incorporating contextual information thus capturing the visual and language context of a word for accurate categorization. We empirically show that our EIGEN framework can significantly improve the performance of state-of-the-art deep models with the availability of very few labeled data instances. The source code is available at https://github.com/ayushayush591/EIGEN-High-Fidelity-Extraction-Document-Images.
MCANet: Medical Image Segmentation with Multi-Scale Cross-Axis Attention
Dec 20, 2023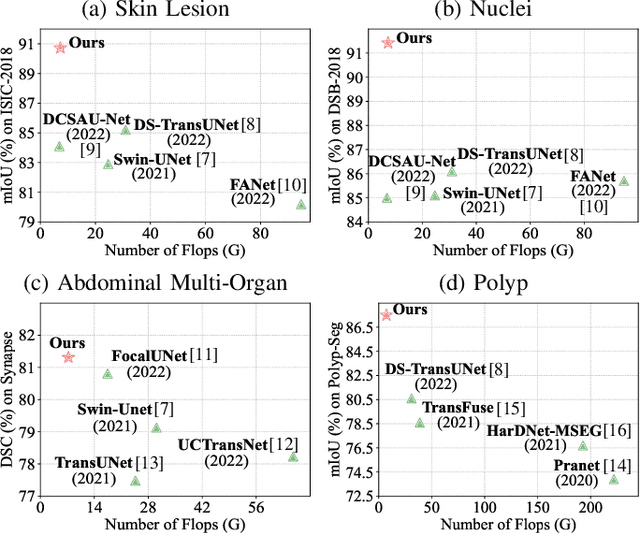
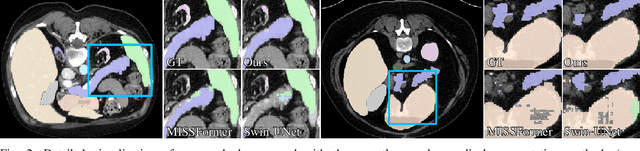
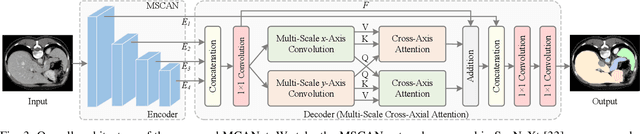
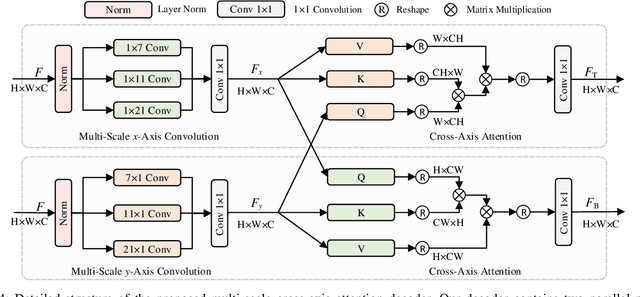
Efficiently capturing multi-scale information and building long-range dependencies among pixels are essential for medical image segmentation because of the various sizes and shapes of the lesion regions or organs. In this paper, we present Multi-scale Cross-axis Attention (MCA) to solve the above challenging issues based on the efficient axial attention. Instead of simply connecting axial attention along the horizontal and vertical directions sequentially, we propose to calculate dual cross attentions between two parallel axial attentions to capture global information better. To process the significant variations of lesion regions or organs in individual sizes and shapes, we also use multiple convolutions of strip-shape kernels with different kernel sizes in each axial attention path to improve the efficiency of the proposed MCA in encoding spatial information. We build the proposed MCA upon the MSCAN backbone, yielding our network, termed MCANet. Our MCANet with only 4M+ parameters performs even better than most previous works with heavy backbones (e.g., Swin Transformer) on four challenging tasks, including skin lesion segmentation, nuclei segmentation, abdominal multi-organ segmentation, and polyp segmentation. Code is available at https://github.com/haoshao-nku/medical_seg.
Describing Robots from Design to Learning: Towards an Interactive Lifecycle Representation of Robots
Dec 19, 2023The robot development process is divided into several stages, which create barriers to the exchange of information between these different stages. We advocate for an interactive lifecycle representation, extending from robot morphology design to learning, and introduce the role of robot description formats in facilitating information transfer throughout this pipeline. We analyzed the relationship between design and simulation, enabling us to employ robot process automation methods for transferring information from the design phase to the learning phase in simulation. As part of this effort, we have developed an open-source plugin called ACDC4Robot for Fusion 360, which automates this process and transforms Fusion 360 into a user-friendly graphical interface for creating and editing robot description formats. Additionally, we offer an out-of-the-box robot model library to streamline and reduce repetitive tasks. All codes are hosted open-source. (\url{https://github.com/bionicdl-sustech/ACDC4Robot})
Enhancing Traffic Flow Prediction using Outlier-Weighted AutoEncoders: Handling Real-Time Changes
Dec 27, 2023In today's urban landscape, traffic congestion poses a critical challenge, especially during outlier scenarios. These outliers can indicate abrupt traffic peaks, drops, or irregular trends, often arising from factors such as accidents, events, or roadwork. Moreover, Given the dynamic nature of traffic, the need for real-time traffic modeling also becomes crucial to ensure accurate and up-to-date traffic predictions. To address these challenges, we introduce the Outlier Weighted Autoencoder Modeling (OWAM) framework. OWAM employs autoencoders for local outlier detection and generates correlation scores to assess neighboring traffic's influence. These scores serve as a weighted factor for neighboring sensors, before fusing them into the model. This information enhances the traffic model's performance and supports effective real-time updates, a crucial aspect for capturing dynamic traffic patterns. OWAM demonstrates a favorable trade-off between accuracy and efficiency, rendering it highly suitable for real-world applications. The research findings contribute significantly to the development of more efficient and adaptive traffic prediction models, advancing the field of transportation management for the future. The code and datasets of our framework is publicly available under https://github.com/himanshudce/OWAM.
Make BERT-based Chinese Spelling Check Model Enhanced by Layerwise Attention and Gaussian Mixture Model
Dec 27, 2023BERT-based models have shown a remarkable ability in the Chinese Spelling Check (CSC) task recently. However, traditional BERT-based methods still suffer from two limitations. First, although previous works have identified that explicit prior knowledge like Part-Of-Speech (POS) tagging can benefit in the CSC task, they neglected the fact that spelling errors inherent in CSC data can lead to incorrect tags and therefore mislead models. Additionally, they ignored the correlation between the implicit hierarchical information encoded by BERT's intermediate layers and different linguistic phenomena. This results in sub-optimal accuracy. To alleviate the above two issues, we design a heterogeneous knowledge-infused framework to strengthen BERT-based CSC models. To incorporate explicit POS knowledge, we utilize an auxiliary task strategy driven by Gaussian mixture model. Meanwhile, to incorporate implicit hierarchical linguistic knowledge within the encoder, we propose a novel form of n-gram-based layerwise self-attention to generate a multilayer representation. Experimental results show that our proposed framework yields a stable performance boost over four strong baseline models and outperforms the previous state-of-the-art methods on two datasets.
* 10 pages, 4 figures, 2023 International Joint Conference on Neural Networks (IJCNN)