 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Simplicial Representation Learning with Neural $k$-forms
Dec 13, 2023
Geometric deep learning extends deep learning to incorporate information about the geometry and topology data, especially in complex domains like graphs. Despite the popularity of message passing in this field, it has limitations such as the need for graph rewiring, ambiguity in interpreting data, and over-smoothing. In this paper, we take a different approach, focusing on leveraging geometric information from simplicial complexes embedded in $\mathbb{R}^n$ using node coordinates. We use differential k-forms in \mathbb{R}^n to create representations of simplices, offering interpretability and geometric consistency without message passing. This approach also enables us to apply differential geometry tools and achieve universal approximation. Our method is efficient, versatile, and applicable to various input complexes, including graphs, simplicial complexes, and cell complexes. It outperforms existing message passing neural networks in harnessing information from geometrical graphs with node features serving as coordinates.
Bi-directional Adapter for Multi-modal Tracking
Dec 17, 2023Due to the rapid development of computer vision, single-modal (RGB) object tracking has made significant progress in recent years. Considering the limitation of single imaging sensor, multi-modal images (RGB, Infrared, etc.) are introduced to compensate for this deficiency for all-weather object tracking in complex environments. However, as acquiring sufficient multi-modal tracking data is hard while the dominant modality changes with the open environment, most existing techniques fail to extract multi-modal complementary information dynamically, yielding unsatisfactory tracking performance. To handle this problem, we propose a novel multi-modal visual prompt tracking model based on a universal bi-directional adapter, cross-prompting multiple modalities mutually. Our model consists of a universal bi-directional adapter and multiple modality-specific transformer encoder branches with sharing parameters. The encoders extract features of each modality separately by using a frozen pre-trained foundation model. We develop a simple but effective light feature adapter to transfer modality-specific information from one modality to another, performing visual feature prompt fusion in an adaptive manner. With adding fewer (0.32M) trainable parameters, our model achieves superior tracking performance in comparison with both the full fine-tuning methods and the prompt learning-based methods. Our code is available: https://github.com/SparkTempest/BAT.
Retrieval-Augmented Code Generation for Universal Information Extraction
Nov 06, 2023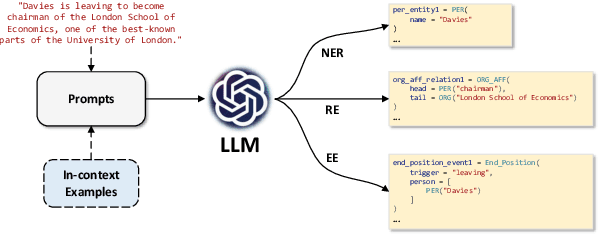
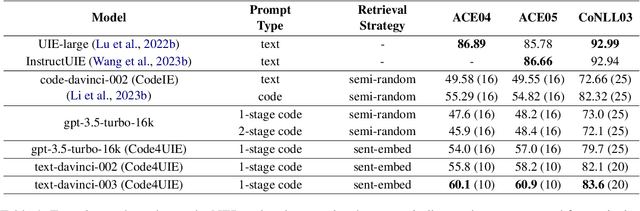

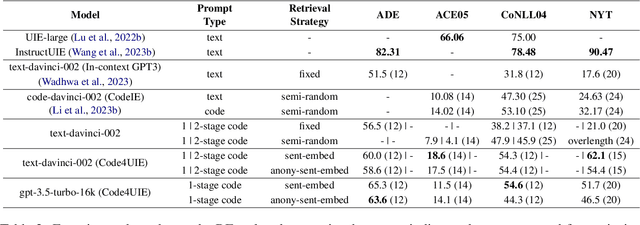
Information Extraction (IE) aims to extract structural knowledge (e.g., entities, relations, events) from natural language texts, which brings challenges to existing methods due to task-specific schemas and complex text expressions. Code, as a typical kind of formalized language, is capable of describing structural knowledge under various schemas in a universal way. On the other hand, Large Language Models (LLMs) trained on both codes and texts have demonstrated powerful capabilities of transforming texts into codes, which provides a feasible solution to IE tasks. Therefore, in this paper, we propose a universal retrieval-augmented code generation framework based on LLMs, called Code4UIE, for IE tasks. Specifically, Code4UIE adopts Python classes to define task-specific schemas of various structural knowledge in a universal way. By so doing, extracting knowledge under these schemas can be transformed into generating codes that instantiate the predefined Python classes with the information in texts. To generate these codes more precisely, Code4UIE adopts the in-context learning mechanism to instruct LLMs with examples. In order to obtain appropriate examples for different tasks, Code4UIE explores several example retrieval strategies, which can retrieve examples semantically similar to the given texts. Extensive experiments on five representative IE tasks across nine datasets demonstrate the effectiveness of the Code4UIE framework.
Guided Image Restoration via Simultaneous Feature and Image Guided Fusion
Dec 14, 2023
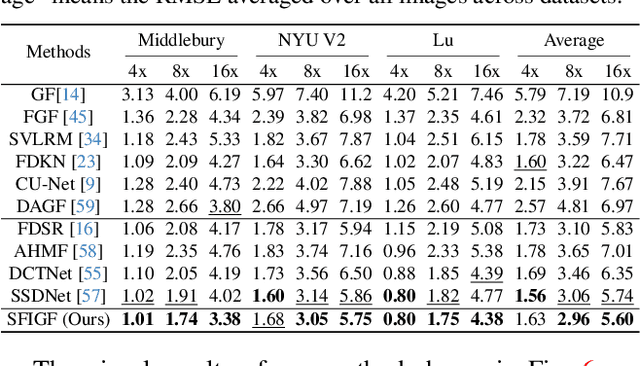
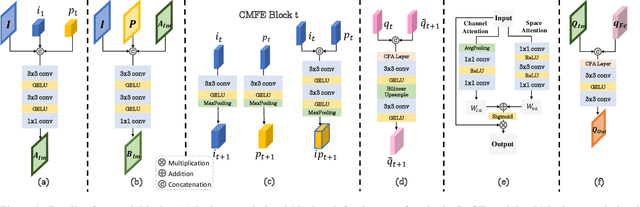
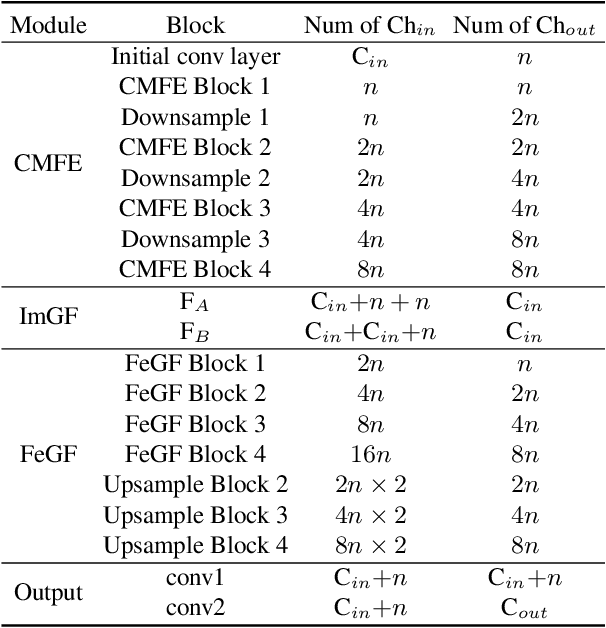
Guided image restoration (GIR), such as guided depth map super-resolution and pan-sharpening, aims to enhance a target image using guidance information from another image of the same scene. Currently, joint image filtering-inspired deep learning-based methods represent the state-of-the-art for GIR tasks. Those methods either deal with GIR in an end-to-end way by elaborately designing filtering-oriented deep neural network (DNN) modules, focusing on the feature-level fusion of inputs; or explicitly making use of the traditional joint filtering mechanism by parameterizing filtering coefficients with DNNs, working on image-level fusion. The former ones are good at recovering contextual information but tend to lose fine-grained details, while the latter ones can better retain textual information but might lead to content distortions. In this work, to inherit the advantages of both methodologies while mitigating their limitations, we proposed a Simultaneous Feature and Image Guided Fusion (SFIGF) network, that simultaneously considers feature and image-level guided fusion following the guided filter (GF) mechanism. In the feature domain, we connect the cross-attention (CA) with GF, and propose a GF-inspired CA module for better feature-level fusion; in the image domain, we fully explore the GF mechanism and design GF-like structure for better image-level fusion. Since guided fusion is implemented in both feature and image domains, the proposed SFIGF is expected to faithfully reconstruct both contextual and textual information from sources and thus lead to better GIR results. We apply SFIGF to 4 typical GIR tasks, and experimental results on these tasks demonstrate its effectiveness and general availability.
Towards Information Theory-Based Discovery of Equivariances
Oct 25, 2023The presence of symmetries imposes a stringent set of constraints on a system. This constrained structure allows intelligent agents interacting with such a system to drastically improve the efficiency of learning and generalization, through the internalisation of the system's symmetries into their information-processing. In parallel, principled models of complexity-constrained learning and behaviour make increasing use of information-theoretic methods. Here, we wish to marry these two perspectives and understand whether and in which form the information-theoretic lens can "see" the effect of symmetries of a system. For this purpose, we propose a novel variant of the Information Bottleneck principle, which has served as a productive basis for many principled studies of learning and information-constrained adaptive behaviour. We show (in the discrete case) that our approach formalises a certain duality between symmetry and information parsimony: namely, channel equivariances can be characterised by the optimal mutual information-preserving joint compression of the channel's input and output. This information-theoretic treatment furthermore suggests a principled notion of "soft" equivariance, whose "coarseness" is measured by the amount of input-output mutual information preserved by the corresponding optimal compression. This new notion offers a bridge between the field of bounded rationality and the study of symmetries in neural representations. The framework may also allow (exact and soft) equivariances to be automatically discovered.
Optimizing Ego Vehicle Trajectory Prediction: The Graph Enhancement Approach
Dec 20, 2023Predicting the trajectory of an ego vehicle is a critical component of autonomous driving systems. Current state-of-the-art methods typically rely on Deep Neural Networks (DNNs) and sequential models to process front-view images for future trajectory prediction. However, these approaches often struggle with perspective issues affecting object features in the scene. To address this, we advocate for the use of Bird's Eye View (BEV) perspectives, which offer unique advantages in capturing spatial relationships and object homogeneity. In our work, we leverage Graph Neural Networks (GNNs) and positional encoding to represent objects in a BEV, achieving competitive performance compared to traditional DNN-based methods. While the BEV-based approach loses some detailed information inherent to front-view images, we balance this by enriching the BEV data by representing it as a graph where relationships between the objects in a scene are captured effectively.
Segmenting Messy Text: Detecting Boundaries in Text Derived from Historical Newspaper Images
Dec 20, 2023Text segmentation, the task of dividing a document into sections, is often a prerequisite for performing additional natural language processing tasks. Existing text segmentation methods have typically been developed and tested using clean, narrative-style text with segments containing distinct topics. Here we consider a challenging text segmentation task: dividing newspaper marriage announcement lists into units of one announcement each. In many cases the information is not structured into sentences, and adjacent segments are not topically distinct from each other. In addition, the text of the announcements, which is derived from images of historical newspapers via optical character recognition, contains many typographical errors. As a result, these announcements are not amenable to segmentation with existing techniques. We present a novel deep learning-based model for segmenting such text and show that it significantly outperforms an existing state-of-the-art method on our task.
* 8 pages, 4 figures
Brain Computer Interface Technology for Future Battlefield
Dec 13, 2023With the development of artificial intelligence and unmanned equipment, human-machine hybrid formations will be the main focus in future combat formations. With the development of big data and various situational awareness technologies, while enhancing the breadth and depth of information, decision-making has also become more complex. The operation mode of existing unmanned equipment often requires complex manual input, which is not conducive to the battlefield environment. How to reduce the cognitive load of information exchange between soldiers and various unmanned equipment is an important issue in future intelligent warfare. This paper proposes a brain computer interface communication system for soldier combat, which takes into account the characteristics of soldier combat scenarios in design. The stimulation paradigm is combined with helmets, portable computers, and firearms, and brain computer interface technology is used to achieve fast, barrier free, and hands-free communication between humans and machines. Intelligent algorithms are combined to assist decision-making in fully perceiving and fusing situational information on the battlefield, and a large amount of data is processed quickly, understanding and integrating a large amount of data from human and machine networks, achieving real-time perception of battlefield information, making intelligent decisions, and achieving the effect of direct control of drone swarms and other equipment by the human brain to assist in soldier scenarios.
Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
Dec 22, 2023A key method for creating Artificial Intelligence (AI) agents is Reinforcement Learning (RL). However, constructing a standalone RL policy that maps perception to action directly encounters severe problems, chief among them being its lack of generality across multiple tasks and the need for a large amount of training data. The leading cause is that it cannot effectively integrate prior information into the perception-action cycle when devising the policy. Large language models (LLMs) emerged as a fundamental way to incorporate cross-domain knowledge into AI agents but lack crucial learning and adaptation toward specific decision problems. This paper presents a general framework model for integrating and learning structured reasoning into AI agents' policies. Our methodology is motivated by the modularity found in the human brain. The framework utilises the construction of intrinsic and extrinsic functions to add previous understandings of reasoning structures. It also provides the adaptive ability to learn models inside every module or function, consistent with the modular structure of cognitive processes. We describe the framework in-depth and compare it with other AI pipelines and existing frameworks. The paper explores practical applications, covering experiments that show the effectiveness of our method. Our results indicate that AI agents perform and adapt far better when organised reasoning and prior knowledge are embedded. This opens the door to more resilient and general AI agent systems.
Room Occupancy Prediction: Exploring the Power of Machine Learning and Temporal Insights
Dec 22, 2023Energy conservation in buildings is a paramount concern to combat greenhouse gas emissions and combat climate change. The efficient management of room occupancy, involving actions like lighting control and climate adjustment, is a pivotal strategy to curtail energy consumption. In contexts where surveillance technology isn't viable, non-intrusive sensors are employed to estimate room occupancy. In this study, we present a predictive framework for room occupancy that leverages a diverse set of machine learning models, with Random Forest consistently achieving the highest predictive accuracy. Notably, this dataset encompasses both temporal and spatial dimensions, revealing a wealth of information. Intriguingly, our framework demonstrates robust performance even in the absence of explicit temporal modeling. These findings underscore the remarkable predictive power of traditional machine learning models. The success can be attributed to the presence of feature redundancy, the simplicity of linear spatial and temporal patterns, and the advantages of high-frequency data sampling. While these results are compelling, it's essential to remain open to the possibility that explicitly modeling the temporal dimension could unlock deeper insights or further enhance predictive capabilities in specific scenarios. In summary, our research not only validates the effectiveness of our prediction framework for continuous and classification tasks but also underscores the potential for improvements through the inclusion of temporal aspects. The study highlights the promise of machine learning in shaping energy-efficient practices and room occupancy management.