 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
C-NERF: Representing Scene Changes as Directional Consistency Difference-based NeRF
Dec 23, 2023
In this work, we aim to detect the changes caused by object variations in a scene represented by the neural radiance fields (NeRFs). Given an arbitrary view and two sets of scene images captured at different timestamps, we can predict the scene changes in that view, which has significant potential applications in scene monitoring and measuring. We conducted preliminary studies and found that such an exciting task cannot be easily achieved by utilizing existing NeRFs and 2D change detection methods with many false or missing detections. The main reason is that the 2D change detection is based on the pixel appearance difference between spatial-aligned image pairs and neglects the stereo information in the NeRF. To address the limitations, we propose the C-NERF to represent scene changes as directional consistency difference-based NeRF, which mainly contains three modules. We first perform the spatial alignment of two NeRFs captured before and after changes. Then, we identify the change points based on the direction-consistent constraint; that is, real change points have similar change representations across view directions, but fake change points do not. Finally, we design the change map rendering process based on the built NeRFs and can generate the change map of an arbitrarily specified view direction. To validate the effectiveness, we build a new dataset containing ten scenes covering diverse scenarios with different changing objects. Our approach surpasses state-of-the-art 2D change detection and NeRF-based methods by a significant margin.
SECap: Speech Emotion Captioning with Large Language Model
Dec 23, 2023Speech emotions are crucial in human communication and are extensively used in fields like speech synthesis and natural language understanding. Most prior studies, such as speech emotion recognition, have categorized speech emotions into a fixed set of classes. Yet, emotions expressed in human speech are often complex, and categorizing them into predefined groups can be insufficient to adequately represent speech emotions. On the contrary, describing speech emotions directly by means of natural language may be a more effective approach. Regrettably, there are not many studies available that have focused on this direction. Therefore, this paper proposes a speech emotion captioning framework named SECap, aiming at effectively describing speech emotions using natural language. Owing to the impressive capabilities of large language models in language comprehension and text generation, SECap employs LLaMA as the text decoder to allow the production of coherent speech emotion captions. In addition, SECap leverages HuBERT as the audio encoder to extract general speech features and Q-Former as the Bridge-Net to provide LLaMA with emotion-related speech features. To accomplish this, Q-Former utilizes mutual information learning to disentangle emotion-related speech features and speech contents, while implementing contrastive learning to extract more emotion-related speech features. The results of objective and subjective evaluations demonstrate that: 1) the SECap framework outperforms the HTSAT-BART baseline in all objective evaluations; 2) SECap can generate high-quality speech emotion captions that attain performance on par with human annotators in subjective mean opinion score tests.
WildScenes: A Benchmark for 2D and 3D Semantic Segmentation in Large-scale Natural Environments
Dec 23, 2023Recent progress in semantic scene understanding has primarily been enabled by the availability of semantically annotated bi-modal (camera and lidar) datasets in urban environments. However, such annotated datasets are also needed for natural, unstructured environments to enable semantic perception for applications, including conservation, search and rescue, environment monitoring, and agricultural automation. Therefore, we introduce WildScenes, a bi-modal benchmark dataset consisting of multiple large-scale traversals in natural environments, including semantic annotations in high-resolution 2D images and dense 3D lidar point clouds, and accurate 6-DoF pose information. The data is (1) trajectory-centric with accurate localization and globally aligned point clouds, (2) calibrated and synchronized to support bi-modal inference, and (3) containing different natural environments over 6 months to support research on domain adaptation. Our 3D semantic labels are obtained via an efficient automated process that transfers the human-annotated 2D labels from multiple views into 3D point clouds, thus circumventing the need for expensive and time-consuming human annotation in 3D. We introduce benchmarks on 2D and 3D semantic segmentation and evaluate a variety of recent deep-learning techniques to demonstrate the challenges in semantic segmentation in natural environments. We propose train-val-test splits for standard benchmarks as well as domain adaptation benchmarks and utilize an automated split generation technique to ensure the balance of class label distributions. The data, evaluation scripts and pretrained models will be released upon acceptance at https://csiro-robotics.github.io/WildScenes.
Understanding and Leveraging the Learning Phases of Neural Networks
Dec 14, 2023The learning dynamics of deep neural networks are not well understood. The information bottleneck (IB) theory proclaimed separate fitting and compression phases. But they have since been heavily debated. We comprehensively analyze the learning dynamics by investigating a layer's reconstruction ability of the input and prediction performance based on the evolution of parameters during training. We empirically show the existence of three phases using common datasets and architectures such as ResNet and VGG: (i) near constant reconstruction loss, (ii) decrease, and (iii) increase. We also derive an empirically grounded data model and prove the existence of phases for single-layer networks. Technically, our approach leverages classical complexity analysis. It differs from IB by relying on measuring reconstruction loss rather than information theoretic measures to relate information of intermediate layers and inputs. Our work implies a new best practice for transfer learning: We show empirically that the pre-training of a classifier should stop well before its performance is optimal.
ConDaFormer: Disassembled Transformer with Local Structure Enhancement for 3D Point Cloud Understanding
Dec 18, 2023Transformers have been recently explored for 3D point cloud understanding with impressive progress achieved. A large number of points, over 0.1 million, make the global self-attention infeasible for point cloud data. Thus, most methods propose to apply the transformer in a local region, e.g., spherical or cubic window. However, it still contains a large number of Query-Key pairs, which requires high computational costs. In addition, previous methods usually learn the query, key, and value using a linear projection without modeling the local 3D geometric structure. In this paper, we attempt to reduce the costs and model the local geometry prior by developing a new transformer block, named ConDaFormer. Technically, ConDaFormer disassembles the cubic window into three orthogonal 2D planes, leading to fewer points when modeling the attention in a similar range. The disassembling operation is beneficial to enlarging the range of attention without increasing the computational complexity, but ignores some contexts. To provide a remedy, we develop a local structure enhancement strategy that introduces a depth-wise convolution before and after the attention. This scheme can also capture the local geometric information. Taking advantage of these designs, ConDaFormer captures both long-range contextual information and local priors. The effectiveness is demonstrated by experimental results on several 3D point cloud understanding benchmarks. Code is available at https://github.com/LHDuan/ConDaFormer .
FrameFinder: Explorative Multi-Perspective Framing Extraction from News Headlines
Dec 14, 2023Revealing the framing of news articles is an important yet neglected task in information seeking and retrieval. In the present work, we present FrameFinder, an open tool for extracting and analyzing frames in textual data. FrameFinder visually represents the frames of text from three perspectives, i.e., (i) frame labels, (ii) frame dimensions, and (iii) frame structure. By analyzing the well-established gun violence frame corpus, we demonstrate the merits of our proposed solution to support social science research and call for subsequent integration into information interactions.
* Accepted for publication at CHIIR'24
Learning of networked spreading models from noisy and incomplete data
Dec 20, 2023Recent years have seen a lot of progress in algorithms for learning parameters of spreading dynamics from both full and partial data. Some of the remaining challenges include model selection under the scenarios of unknown network structure, noisy data, missing observations in time, as well as an efficient incorporation of prior information to minimize the number of samples required for an accurate learning. Here, we introduce a universal learning method based on scalable dynamic message-passing technique that addresses these challenges often encountered in real data. The algorithm leverages available prior knowledge on the model and on the data, and reconstructs both network structure and parameters of a spreading model. We show that a linear computational complexity of the method with the key model parameters makes the algorithm scalable to large network instances.
Exploiting Latent Attribute Interaction with Transformer on Heterogeneous Information Networks
Nov 06, 2023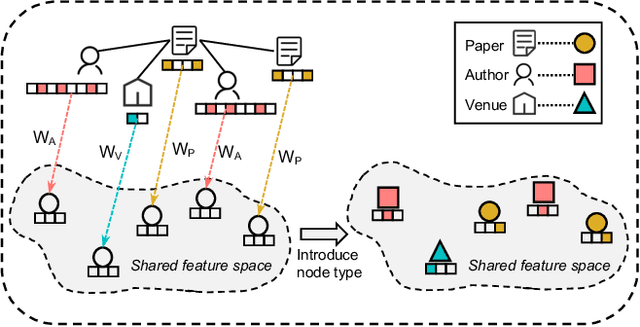
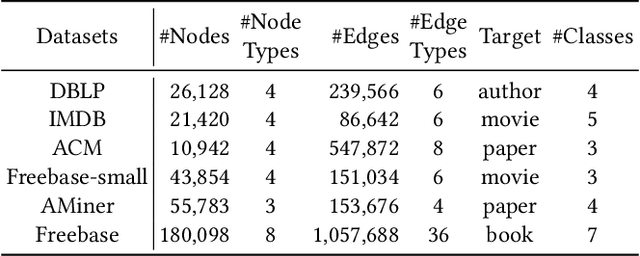
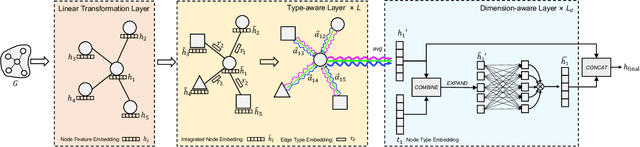
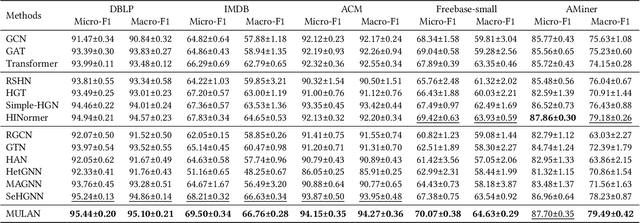
Heterogeneous graph neural networks (HGNNs) have recently shown impressive capability in modeling heterogeneous graphs that are ubiquitous in real-world applications. Due to the diversity of attributes of nodes in different types, most existing models first align nodes by mapping them into the same low-dimensional space. However, in this way, they lose the type information of nodes. In addition, most of them only consider the interactions between nodes while neglecting the high-order information behind the latent interactions among different node features. To address these problems, in this paper, we propose a novel heterogeneous graph model MULAN, including two major components, i.e., a type-aware encoder and a dimension-aware encoder. Specifically, the type-aware encoder compensates for the loss of node type information and better leverages graph heterogeneity in learning node representations. Built upon transformer architecture, the dimension-aware encoder is capable of capturing the latent interactions among the diverse node features. With these components, the information of graph heterogeneity, node features and graph structure can be comprehensively encoded in node representations. We conduct extensive experiments on six heterogeneous benchmark datasets, which demonstrates the superiority of MULAN over other state-of-the-art competitors and also shows that MULAN is efficient.
Rethinking Dimensional Rationale in Graph Contrastive Learning from Causal Perspective
Dec 16, 2023Graph contrastive learning is a general learning paradigm excelling at capturing invariant information from diverse perturbations in graphs. Recent works focus on exploring the structural rationale from graphs, thereby increasing the discriminability of the invariant information. However, such methods may incur in the mis-learning of graph models towards the interpretability of graphs, and thus the learned noisy and task-agnostic information interferes with the prediction of graphs. To this end, with the purpose of exploring the intrinsic rationale of graphs, we accordingly propose to capture the dimensional rationale from graphs, which has not received sufficient attention in the literature. The conducted exploratory experiments attest to the feasibility of the aforementioned roadmap. To elucidate the innate mechanism behind the performance improvement arising from the dimensional rationale, we rethink the dimensional rationale in graph contrastive learning from a causal perspective and further formalize the causality among the variables in the pre-training stage to build the corresponding structural causal model. On the basis of the understanding of the structural causal model, we propose the dimensional rationale-aware graph contrastive learning approach, which introduces a learnable dimensional rationale acquiring network and a redundancy reduction constraint. The learnable dimensional rationale acquiring network is updated by leveraging a bi-level meta-learning technique, and the redundancy reduction constraint disentangles the redundant features through a decorrelation process during learning. Empirically, compared with state-of-the-art methods, our method can yield significant performance boosts on various benchmarks with respect to discriminability and transferability. The code implementation of our method is available at https://github.com/ByronJi/DRGCL.
A quantitative fusion strategy of stock picking and timing based on Particle Swarm Optimized-Back Propagation Neural Network and Multivariate Gaussian-Hidden Markov Model
Dec 22, 2023In recent years, machine learning (ML) has brought effective approaches and novel techniques to economic decision, investment forecasting, and risk management, etc., coping the variable and intricate nature of economic and financial environments. For the investment in stock market, this research introduces a pioneering quantitative fusion model combining stock timing and picking strategy by leveraging the Multivariate Gaussian-Hidden Markov Model (MGHMM) and Back Propagation Neural Network optimized by Particle Swarm (PSO-BPNN). After the information coefficients (IC) between fifty-two factors that have been winsorized, neutralized and standardized and the return of CSI 300 index are calculated, a given amount of factors that rank ahead are choose to be candidate factors heading for the input of PSO-BPNN after dimension reduction by Principal Component Analysis (PCA), followed by a certain amount of constituent stocks outputted. Subsequently, we conduct the prediction and trading on the basis of the screening stocks and stock market state outputted by MGHMM trained using inputting CSI 300 index data after Box-Cox transformation, bespeaking eximious performance during the period of past four years. Ultimately, some conventional forecast and trading methods are compared with our strategy in Chinese stock market. Our fusion strategy incorporating stock picking and timing presented in this article provide a innovative technique for financial analysis.